2022. 4. 28. 10:20ㆍNaver BoostCamp AI Tech 3기
Dense Passage Retrieval for Open-Domain Question Answering
Open-domain question answering은 후보 context를 고르기 위한 효율적인 passage retrieval에 의지하며, 여기에는 전통적인 sparse vector space model들인 TF-IDF, BM25 등이 표준적인 방법이다. 이번 논문에서는, 연구팀은 retrieval가 dense representation만 이용하여 거의 구현될 수 있다는 것을 보여줄 것이며, 여기서 embedding은 단순한 dual-encoder framework를 통해 작은 수의 question 및 passage로부터 학습될 것이다. 넓은 범위의 open-domain QA dataset들에서 평가 시에, 연구팀의 dense retriever는 strong한 Lucene-BM25 system을 top-20 passage retrieval accuracy에 대해서 크게 9%~19%까지 압도하였고, 결과적으로 다수의 open-domain QA benchmark들에서 이를 이용한 end-to-end QA system이 새 sota를 달성할 수 있었다.
1 Introduction
ODQA는 많은 document들을 이용하여 factoid question(주로 명사나 단순한 동사로 대답할 수 있는 짧은 대답을 가진 question)에 대답하는 task를 의미한다. 이 ODQA는 점점 발전을 이루어서 현재에는 다음과 같은 two-stage framework에 이르게 되었다.
(1) a context retriever
먼저 retriever가 question에 대한 answer를 포함하는 것 같은 passage들 중 subset을 선택한다.
(2) a machine reader
그 후 reader가 이 retrieved context들을 철저하게 조사하여 정답을 찾아낸다.
이런식으로 ODQA를 machine reading task로 축소시키는 것이 합리적인 전략이긴 하지만, 실제로는 이렇게 축소 시에 엄청난 성능 저하가 관찰되며, 이는 retrieval 쪽의 성능 향상의 필요성을 제기하는 것이다.
ODQA에서 retrieval은 주로 TF-IDF 또는 BM25를 사용하여 구현되는데, 이는 키워드들을 inverted index를 통해 효율적으로 match시키며 question 및 context를 고차원의 sparse vector로 표현하는 것이라 할 수 있다. 이와 대조적으로, dense하고 latent한 semantic encoding은 디자인면에서 sparse representation을 보완한 것이다. 바로 동의어 및 paraphrase들을 vector space에서 더 가깝게 표현할 수 있는 것이다. 기존 sparse한 term-based system은 동의어 및 paraphrase들을 포함한 context 및 question을 match하기 힘든 반면, dense한 경우에는 잘 match한다. 또한 dense encoding은 embedding function을 조절함으로써 학습 가능하며, 이는 task-specific한 representation을 가질 수 있는 추가적인 flexibility를 부여한다. Special한 in-memory 자료구조 및 indexing scheme를 통해, retrieval은 maximum inner product search(MIPS) 알고리즘을 통해 효율적으로 이루어질 수 있다.
그러나, 일반적으로 좋은 dense vector representation에는 대량의 question 및 context에 대한 labeled pair가 필요하다는 것이 상식이다. Dense retrieval은 그리하여 이전에는 TF-IDF 및 BM25를 ODQA에서 성능면에서 이기지 못하였다. 그러나 ORQA(2019)에서 정교한 inverse cloze task(ICT) objective를 제안한 이후로는 달라졌다. ICT objective는 masked sentence를 포함하는 block들을 예측하는 것으로, 추가적인 pre-training을 하기 위한 것이다. 그 후에는 question encoder 및 reader model이 question 및 answer가 결합된 pair를 사용하여 fine-tuned 된다. 이 ICT는 2가지 단점이 있었다. 먼저, ICT pre-training은 computationally intensive하며, objective function에서 일반적인 문장들이 question들을 잘 대체하는 지 명확하지 않다. 두번째로, context encoder가 QA pair로 잘 fine-tuned되지 않기 때문에, 이에 일치하는 representation들은 sub-optimal할 수 있다.
이번 논문에서는, 다음과 같은 질문에 대해 다룬다. 추가적인 pre-training없이 오직 Question-passage pair로만 dense embedding model을 더 잘 훈련시킬 수 있을까? 현재 standard BERT pre-trained model과 dual-encoder architecture를 통해서, 비교적 적은 숫자의 question-passage pair들로 올바르게 훈련하는 scheme을 발전시키는 것에 초점을 둘 것이다. 여러 ablation studies를 통해 얻은 최종 결론은 생각보다 간단한데, 바로 embedding은 question 및 passage vector들의 inner product를 최대화 시킴으로써 최적화된다는 것이다. 연구팀의 Dense Passage Retriever(DPR)은 매우 강력하다. BM25를 Top-5 accuracy에서 큰 격차를 내며 이기고, 그에 따라 ORQA와 비교하여도 end-to-end QA accuracy에서도 엄청난 성능 상승을 보였다.
연구팀의 기여는 크게 2부분으로 나눌 수 있다. 먼저, 적절한 training setup을 통해, 단순하게 question 및 passage encoder들을 현존하는 question-passage pair들로 fine-tuning하는 것이 BM25를 성능에서 압도하는 데에 충분하다는 것이다. 그리고 추가적인 pre-training도 필요 없다는 것이다. 두번째로, ODQA에서, 더 높은 retrieval precision은 결국 더 높은 end-to-end QA accuracy로 이어진 다는 것을 증명하였다. 훨씬 더 복잡한 system들과 비교하여, open-retrieval setting에서 연구팀은 다수의 QA dataset에 대해 비슷하거나 더 좋은 성능을 달성하였다.
2 Background
이 논문에서 연구된 ODQA의 문제점은 다음과 같다. 다음과 같은 factoid question이 주어졌다고 하자. “Who first voiced Meg on Family Guy?” 또는 “Where was the 8th Dalai Lama born?”가 주어지면 system에서 다양한 토픽의 거대 corpus를 사용하여 대답을 하도록 요구된다. 더 구체적으로는, 연구팀에서는 extractive QA setting(span 내에 answer가 나오게 한정함)이라고 가정한다. Document 모음에 d1, d2, … , dD로 구성된다고 하자. 우선적으로 각 document를 동일한 길이의 passage들로 나누어서 기본 retrieval unit으로 설정하며, 결과적으로 corpus C에는 p1, p2, …, pM으로 구성되게 된다. 여기서 각각의 passage pi는 토큰 w1, w2, …, w|pi|로 구성된다. 질문 q가 주어지면, 그에 맞춰 ws, ws+1, …, we의 answer span을 찾아낸다. Corpus size는 domain에 따라 다양할 수 있으며, 결과적으로 reader가 answer를 찾아내기 전에는 passage를 선택하기 위해 효율적인 retriever가 필요하다.
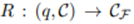
여기서 R이 Retriever, q는 query, C는 corpus이며, CF는 바로 선택된 passage들이다. 여기서 주로 상위 k개를 선택하는 top-k retrieval을 많이 사용한다.
3 Dense Passage Retriever (DPR)
ODQA에서 retrieval 요소의 성능 향상에 초점을 둔다. M개의 text passage가 주어졌을 때, DPR의 목적은 모든 passage들을 low-dimensional 및 continuous한 space에서 index를 매기는 것으로, 이를 통해 런타임에서 reader가 input question과 관련 있는 top k개의 passage들을 효율적으로 retrieve할 수 있게 된다. 주로 M은 매우 큰 숫자로, 논문에서는 2100만 정도이며, k는 주로 작은 숫자로 20~100정도이다.
3.1 Overview
DPR은 dense한 encoder Ep를 사용하며, 이 encoder는 어떠한 text passage라도 d차원의 실수값의 vector들로 mapping하고 retrieval에 사용할 전체 M개의 passage에 대해 index를 생성한다.
런타임에서, DPR은 또다른 encoder EQ를 적용하는데, 이는 input question을 d차원의 vector로 mapping하고, 이 question vector와 제일 가까운 k개의 passage를 retrieve한다. 이 question과 passage 간의 유사도는 다음과 같이 vector의 내적으로 정의한다.

비록 question과 passage 사이의 유사도를 측정하는 더 표현력이 좋은 model 형태가 존재하지만(cross-attention layer가 여러 개인 network와 같은 것들), similarity function은 분해가 가능해야 한다. 그래야 passage의 collection의 representation들을 미리 계산할 수 있기 때문이다. 대부분의 분해가능한 similarity function들은 유클리드 거리(L2)를 일부 변형한 것이다. 예를 들어, cosine은 unit vector들 간의 내적이며, mahalanobis(마할라노비스 거리)는 transformed space에서 유클리드 거리와 동일하다. 결과적으로, 연구팀에서는 더 단순한 inner product function을 선택하고, 더 좋은 encoder들을 학습시킴으로써 dense passage retriever 성능을 향상시켰다.
Encoders
비록 question encoder와 passage encoder들은 어떠한 신경망으로든 구현 가능하지만, 이번 연구에서는 독립적인 2개의 BERT network(base, uncased)를 사용하며 representation은 [CLS] token을 output으로 받는다. d = 768이다.
Inference
Inference 시간 동안에는, passage encoder Ep를 모든 passage들에 적용하고, FAISS를 사용하여 index를 offline에서 매긴다. FAISS는 매우 효율적이고, 오픈소스인 라이브러리로 similarity search와 dense vector들의 clustering을 위한 것으로, 수십억 개의 vector들에 쉽게 적용 가능하다. Question q가 런타임에서 주어지면, 그에 대한 embedding인 vq = EQ(q)이며, vq와 제일 가까운 embedding을 가진 top k개의 passage들을 retrieve한다.
3.2 Training
Dot-product similarity(Eq.1)이 retrieval를 위한 좋은 ranking function이 되기 위해 encoder를 훈련시키는 것은 metric learning problem이라 할 수 있다. 이 훈련의 목표는 question과 passage 간의 관련성이 높인 pair들은 더 적은 distance를 갖도록 하는 vector space를 생성해 내는 것이다.

이것을 m개의 instance로 구성된 training data라고 하자. 각각의 instance는 하나의 question인 qi를 포함하며, 하나의 관련 있는 passage인 pi+를 가지고, n개의 관련 없는 passage인 pi,j-를 포함한다. 이제 loss function은 positive passage에 대한 negative log likelihood로 최적화한다.

Positive and negative passages
Retrieval problem에 대해서, 보통은 positive example들이 명시적으로 사용 가능한 경우이며, 반면에 negative example들은 극도로 거대한 pool에서 선택되어야 한다. 예를 들어서, question과 관련된 passage들은 QA dataset에서 주어질 것이며, 또는 answer를 사용하여 찾을 수도 있다. 이 collection에서 다른 모든 passage들은 명시적으로 구체화되지 않으며, 기본적으로는 “관련 없는” passage로 보인다. 실제로는, 어떻게 negative example들을 고를 지가 간과되지만, 높은 quality의 encoder를 학습시키기 위해서는 중요하다. 연구팀에서는 3가지 종류의 negative를 고려한다.
(1) Random : corpus에서 랜덤하게 passage를 고른다.
(2) BM25 : BM25에 의해 return된 상위 passage 중 정답을 포함하지는 않지만, 대부분의 question token과 match하는 passage들을 고른다.
(3) Gold : TRAINING SET에 등장하는 다른 question들과 묶인 positive passage들을 고른다.
연구팀에서는 Section 5.2에서 training scheme와 각각 다른 종류의 negative passage들의 영향을 논의할 것이다. 연구팀의 가장 좋은 model은 같은 mini-batch 내의 gold passage들과 1개의 BM25 negative passage를 사용한다. 특히, 같은 배치 내의 gold passage들을 negative로 재사용하는 것은 좋은 성능을 내면서 계산을 효율적으로 만들어줄 수 있다.
In-batch negatives
Mini-batch 내에 B개의 question들을 가지고 각각의 question은 각각의 passage와 관련이 있다고 하자. Q와 P를 (B x d)의 batch size가 B인 question과 passage embedding matrix라고 하자. S = QP^T를 (B x B)의 similarity score들의 matrix라 하고, 여기서 각 row는 question이며, B개의 passage와 pair로 되어 있다. 이 방법으로, 연구팀은 각 batch 내에서 B^2의 (qi, pj) question/passage pair들로 계산을 재사용하고 효율적으로 훈련한다. 어떠한 (qi, pj) pair도 i = j이면 positive하며, 그 외에는 negative하다. 이는 각 batch에서 B개의 training instance를 생성해내고, 여기서 B - 1개는 각 question에 대한 negative passage이다.
In-batch negative 기법은 training example들의 숫자를 증강시키며, dual-encoder model의 학습에 대한 효율적인 전략임을 증명해왔다.
4 Experimental Setup
이번 section에서는, experiment에 사용하였던 data를 묘사하며, 기본적인 setup을 묘사한다.
4.1 Wikipedia Data Pre-processing
(Lee et al., 2019)를 따라서, 영어 Wikipedia를 answering question을 위한 source document로 사용하며, DrQA에 release된 pre-processing code를 사용하여 Wikipedia dump의 semi-structured data들을 제거한다. 이는 table, info-boxes, list 및 disambiguation page 등이다. 이후 각 article을 다수의 disjoint text block(단어는 100개)(passage)로 나누며, 이것이 basic retrieval unit이 되며, 최종적으로 21,015,324개의 passage가 나왔다. 각 passage는 Wikipedia article의 제목이 앞에 붙으며, [SEP] token과 함께 붙는다.
4.2 Question Answering Datasets
Natural Questions (NQ)
이 데이터셋은 end-to-end question answering을 위해 설계되었다. 실제 Google search queries로부터 question들이 모아졌고, answer들은 annotator들에 의해 Wikipedia article 내에서 span으로써 매겨졌다.
TriviaQA
이 데이터셋은 Web에서부터 모아진 trivia question 및 answer들의 집합의 모음이다.
WebQuestions (WQ)
이 데이터셋은 Google Suggest API를 사용하여 선택된 question들로 구성되며, answer들은 Freebase 내의 entities이다.
CuratedTREC (TREC)
이 데이터셋은 TREC QA tracks 및 다양한 웹 source로부터 question들을 얻었으며, unstructured corpora로부터 open-domain QA를 하는 의도로 이루어졌다.
SQuAD v1.1
이 데이터셋은 reading comprehension을 위한 인기있는 benchmark dataset이다. annotator들은 Wikipedia paragraph를 배정받고, 이 text로부터 대답할 수 있는 question을 쓰도록 요청 받았다. 비록 SQuAD는 ODQA research를 위해 이전에 사용되어 왔지만, 많은 질문들은 주어진 paragraph 내에서 context의 부재로 인해 부적합하다. 연구팀에서는 여전히 이전 연구들과 공정한 비교를 위해 이 데이터셋을 포함시킨다.
Selection of positive passages
TREC, WebQuestions, TriviaQA에만 question과 answer pair가 제공되므로, 연구팀에서는 BM25에서 가장 높게 랭크된 passage를 positive passage로 사용하였다. 만약 top 100개의 retrieved passage 내에 정답이 없다면, question은 버려진다. Table 1에는 모든 dataset에 대한 training/dev/test set에 대한 것들을 보여준다.

8 Conclusion
이번 연구에서는, dense retrieval이 ODQA에서 traditional한 sparse retrieval을 압도하고 잠재적으로 대체할 수 있음을 증명했다. 비록 단순한 dual-encoder approach가 놀랍게도 잘 작동할 수 있지만, 연구팀에서는 dense retriever를 성공적으로 훈련시키기 위한 중요한 요소들을 보여주었다. 게다가, 연구팀의 경험적인 접근 및 ablation studies는 더 복잡한 model framework 혹은 similarity function들이 추가 점수를 내는 것은 아니라는 것을 시사한다. 향상된 retrieval performance의 결과로, 연구팀은 여러 개의 ODQA benchmark에서 새 sota를 달성하였다.
'Naver BoostCamp AI Tech 3기' 카테고리의 다른 글
| Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering (0) | 2022.06.21 |
|---|---|
| User Guide for KOTE: Korean Online Comments Emotions Dataset (0) | 2022.05.26 |
| [MRC] 03. Generation-based MRC (0) | 2022.04.27 |
| [MRC] 02. Extraction-based MRC (0) | 2022.04.26 |
| [MRC] 01. MRC Intro & Python Basics (0) | 2022.04.25 |