2022. 4. 25. 13:56ㆍNaver BoostCamp AI Tech 3기
MRC에 대해 간략하게 묘사할 수 있는 사진이다.

MRC는 Machine Reading Comprehension의 줄임말로, 기계 독해를 의미한다. 마치 국어 비문학 문제처럼, 지문이 주어지면 그 지문을 읽고, 질문에 대한 답변을 하는 것이다.
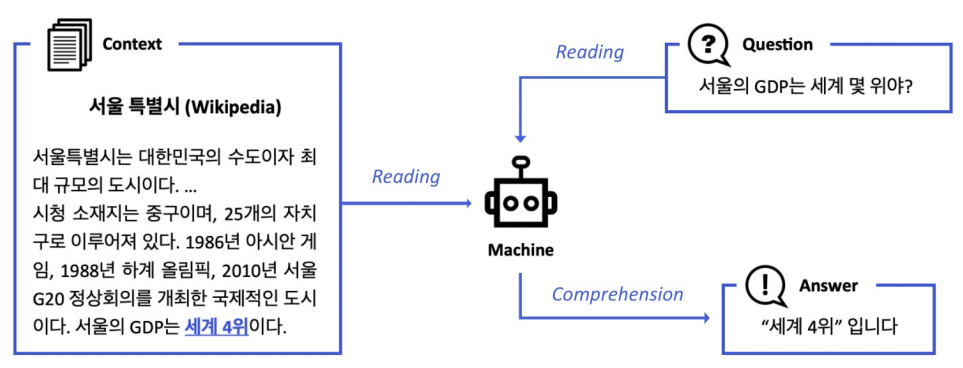
이 MRC는 크게 3가지 종류로 나눌 수 있다.
1) Extractive Answer Datasets
2) Descriptive/Narrative Answer Datasets
3) Multiple-choice Datasets
여기서 1) Extractive Answer Datasets의 경우는 question에 대한 답이 주어진 context 내의 span으로 주어진다. 앞으로 진행할 MRC 대회의 경우 이 1)에 속한다고 볼 수 있다. 예시 데이터셋으로 SQuAD 및 KorQuAD가 있다.
2) Descriptive/Narrative Answer Datasets의 경우는 span이 아닌 일반적인 sentence로 출력해내는 형태이다. 예시 데이터셋으로 MS MARCO, Narrative QA가 있다.
3) Multiple-choice Datasets의 경우는 여러 개의 선택지 중 question에 대한 답을 고르는 객관식 형태라 볼 수 있다. MRC에 완전 적합한 형태라고 볼 수는 없는 데이터셋으로, MCTest, RACE 등이 있다.
Challenges in MRC
MRC task에서 극복해야할 challenge들은 다음과 같다.
1) 단어의 구성이 정확히 일치하지는 않되, 의미가 동일한 경우 똑같이 이해를 할 수 있어야 한다. (Paraphrasing)
2) 지문에서 반드시 질문에 대한 답을 찾을 수 있는 것은 아니다. 이 경우 답을 찾지 못한다고 말할 수 있어야 한다. (Unanswerable questions)
3) 한 지문에서만 답을 찾을 수 없을 수도 있다. 여러 지문에서 종합적인 추론을 통해 질문에 대한 답을 할 수 있어야 한다. (Multi-hop reasoning)
MRC의 평가 방법
1) Exact Match
정확히 답과 일치하는 지로 평가하는 metric으로, 오직 맞다(1점) 틀리다(0점)으로 판단하게 된다. 위에서 언급된 Extractive Answer Datasets 및 Multiple-choice Datasets에 적합한 metric이 된다. 이때, (Number of correct samples) / (Number of whole samples)로 계산할 수 있다.
2) F1 score
Exact Match보다는 좀 더 유연한 형태의 metric으로, token overlap을 통해 평가한다. 다음 그림과 같은 차이점이 있다.

3) ROUGE-L / BLEU
이 metrics은 Descriptive/Narrative Answer Datasets에 적합하며, overlap을 통해 평가한다. ROUGE-L은 LCS(Longest Common Sequence) 기반으로 평가된다.
Unicode & Tokenization
Unicode는 전 세계 문자를 각각 하나의 숫자에 매핑할 수 있도록 한 문자셋이다.
인코딩은 이 문자를 컴퓨터에 맞게 이진수로 변환하는 것으로, 문자마다 가변적으로 바이트를 할당하는 UTF-8이 제일 많이 사용된다. 한글은 3byte를 차지한다.
파이썬에서는 다음과 같이 다룰 수 있다.

Unicode 중 한국어에서 중요한 점은, 완성형과 조합형이 따로 있다는 것이다. 완성형은 글자 하나가 각각 하나의 숫자에 매핑되지만, 조합형은 한 글자를 초성, 중성, 종성으로 나누어서 각각 나타내고 더하는 형태이다.

Tokenizing은 text를 token 단위로 나누는 것이며, 한국어는 공백보다는 subword 또는 morpheme 단위로 나누는 것이 더 적절하다. 여기서 subword 단위의 경우는 BPE(Byte Pair Encoding) 알고리즘을 통해 나눌 수 있다.
KorQuAD
LG CNS에서 AI 언어지능 연구를 위해 만든 QA / MRC 데이터셋이다. 데이터셋 제작 시 SQuAD v1.0의 수집 방식을 벤치마크하여 제작한 것으로, 표준성을 보장할 수 있다.
간단하게 huggingface의 datasets에서 다음과 같이 불러올 수 있다.

KorQuAD 데이터셋은 json형태이며, 다음과 같이 title, question, id, context, answers로 나오게 된다.

'Naver BoostCamp AI Tech 3기' 카테고리의 다른 글
| [MRC] 03. Generation-based MRC (0) | 2022.04.27 |
|---|---|
| [MRC] 02. Extraction-based MRC (0) | 2022.04.26 |
| BART: Denoising Sequence-to-Sequence Pre-training for NaturalLanguage Generation, Translation, and Comprehension (0) | 2022.03.31 |
| KLUE: Korean Language Understanding Evaluation (0) | 2022.03.26 |
| RoBERTa: A Robustly Optimized BERT Pretraining Approach (0) | 2022.03.24 |