2022. 4. 26. 18:27ㆍNaver BoostCamp AI Tech 3기
질문과 답변이 항상 주어진 지문 내에 존재하여 span을 추출해내는 것이다.
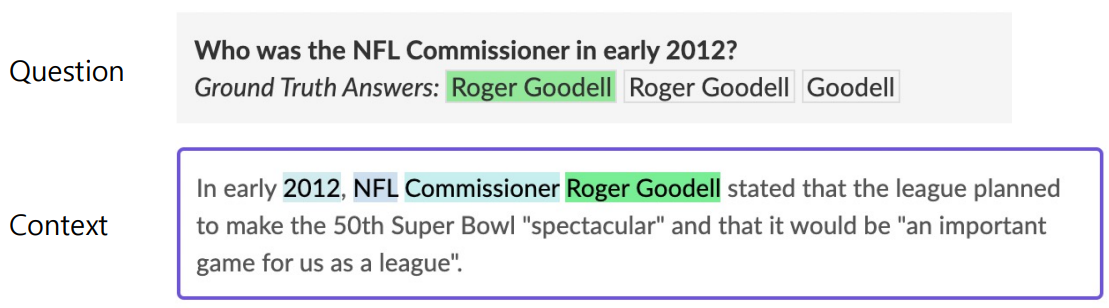
Extraction-based MRC는 EM(Exact Match) 및 F1-score로 평가받는다.
개략적인 Extraction-based MRC는 다음과 같이 나타낼 수 있다.

Preprocessing
Tokenization
텍스트를 토큰 단위로 자르는 것으로, 한국어는 주로 띄어쓰기, 형태소(morpheme), 서브워드(subword)가 기본 토큰 단위로가 되며, 특히 OOV 문제를 해결할 수 있는 서브워드 알고리즘인 BPE(Byte-Pair Encoding)을 많이 사용한다.
Special Tokens
[CLS], [SEP], [PAD] 등 BERT 내에서 주로 사용되는 스페셜 토큰들을 사용한다.
Attention Mask
입력 시퀀스에서 attention 할 부분을 명시하기 위하여 사용되며, 주로 attention이 필요없는 [PAD] 토큰들에는 0을, 그 외에는 1을 부여한다.
Token Type IDs
입력이 2개 이상의 시퀀스인 경우 모델이 각 시퀀스를 구분하기를 유도하기 위해 사용한다.
Fine-tuning
모델의 output으로 각 token이 시작일 확률 및 끝일 확률을 뽑아내어서 cross-entropy loss를 통해 훈련한다.

Post-processing
불가능한 답은 제거한다. (end position < start position, 정답이 question에서 나옴, answer가 max_length보다 긴 등등)
각각 start/end에 대한 score에서 top-k를 뽑아내어, 가능한 조합을 만들어낸다. 그리고 그 조합들 중에서 제일 점수가 높은 조합으로 answer를 낸다.
'Naver BoostCamp AI Tech 3기' 카테고리의 다른 글
| Dense Passage Retrieval for Open-Domain Question Answering (0) | 2022.04.28 |
|---|---|
| [MRC] 03. Generation-based MRC (0) | 2022.04.27 |
| [MRC] 01. MRC Intro & Python Basics (0) | 2022.04.25 |
| BART: Denoising Sequence-to-Sequence Pre-training for NaturalLanguage Generation, Translation, and Comprehension (0) | 2022.03.31 |
| KLUE: Korean Language Understanding Evaluation (0) | 2022.03.26 |