2022. 2. 7. 20:56ㆍNaver BoostCamp AI Tech 3기
Neural Networks(신경망) : 초창기에는 인간의 뇌를 모방하여 만든 계산 시스템이였다. 그러나 비행기의 예시와 같이, 현 시점에서의 Neural Network를 인간의 뇌를 모방했다고 하기에는 무리가 있을 정도로 달라지고 발전하였다. 그래서 신경망을 인간의 뇌라고 하기보다는 다음과 같이 말하는 것이 더 옳을 것 같다,
신경망은, "아핀변환과 비선형변환을 겹쳐 쌓고 쌓아서 탄생한 예측함수"라고 정의 해볼수 있다. 여기서 아핀변환은 선형변환 + 위치변환을 의미한다. 즉, 선형변환과 비선형변환이 쌓여있는 커다란 함수라고 볼 수 있을 것이다.
가장 간단한 신경망의 예시를 살펴보자.
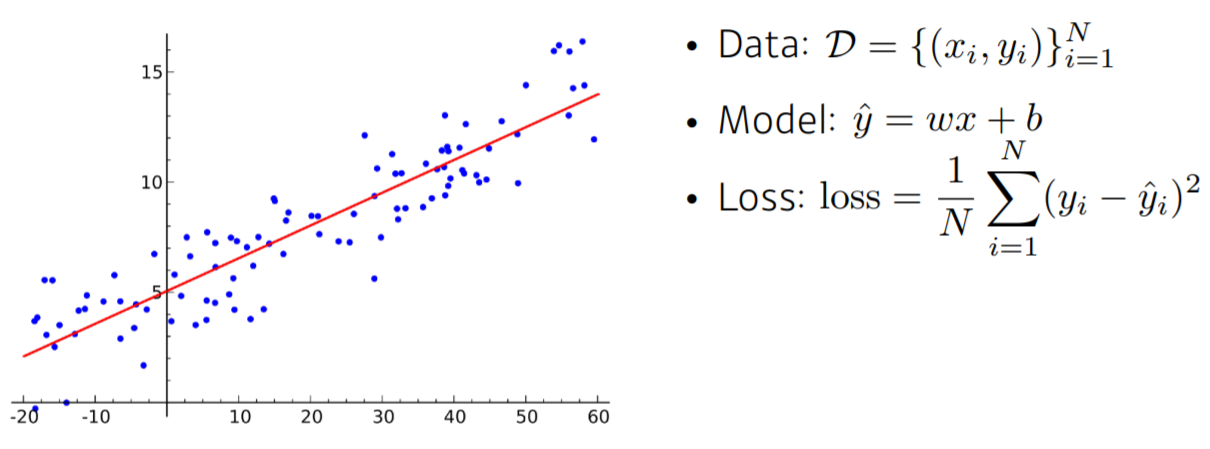
매우매우 간단한 선형 신경망인데, x값을 하나 넣으면 y값을 예측해주는 1차함수 식이 모델이 된다. 여기서 Data는 (x, y) 점이며, 데이터의 개수는 N개이다. Model은 1차함수인 yhat = wx + b이다. Loss는 MSE로 되어있는데, 예측값과 실제 정답(label) 사이의 오차를 제곱하여 합한 것이다. 이 Loss가 작을 수록, 모델이 잘 정답을 예측한다고 볼 수 있다.
그렇다면, 이 모델은 어떻게 훈련시키는 것일까? 학습 방법은 여러 가지가 있는데, 가장 기본인 Gradient Descent를 알아보자. 사실 다른 학습 방법들도 그 근간에는 Gradient Descent를 두고 있기에 매우 중요하다.
먼저, gradient를 구해야 한다. 이 gradient는 쉽게 말하자면 각각의 변수들이 loss에 어느정도 기여를 했나, 즉 얼마나 영향을 미쳤나의 정도로 볼 수 있다. 이 gradient를 구하는 것은 "편미분"이다. loss를 각 변수에 대해 편미분하면 아래와 같은 gradient를 구할 수 있다.
이렇게 구한 gradient를 learning rate(여기서는 stepsize라고 함)를 곱해서 원래의 가중치(변수)에서 빼주는 것이 Gradient Descent이다. 이 방법을 사용하게 되면, loss는 local minima로 수렴하게 된다. 즉, 모델의 성능이 올라가게 된다.



물론, 현실에서 이런 매우 간단한 모델을 사용하지는 않는다. 실제로 신경망에는 위와 같은 선형결합이 들어가게 되는데, 위에서처럼 x 변수 하나만 들어가지 않고, 다음과 같이 들어간다.
y = w1x1 + w2x2 + w3x3 + w4x4 + ... + wnxn + b
이런식으로 n개의 x 변수가 입력으로 들어가게 될 것이다. (이 x들을 각각 feature라고 할 수 있다. dimension이라고도 할 수 있다.) 그러면 이 식을 다음과 같이 행렬곱을 사용해서 깔끔하게 표현하게 된다.

이렇게 선형변환을 하게 되면, 기존의 x의 vector space에서 y의 vector space로 이동시키는 것이라 볼 수 있다. (차원 수부터 달라진다.)

여기서는 단순하게 1층만을 표현하였지만, 이런 구조를 몇개 더 쌓을 수 있다. 이러면 다층 퍼셉트론, 즉 MLP가 되는 것이고, 이것이 딥러닝의 기본이라 할 수 있다.
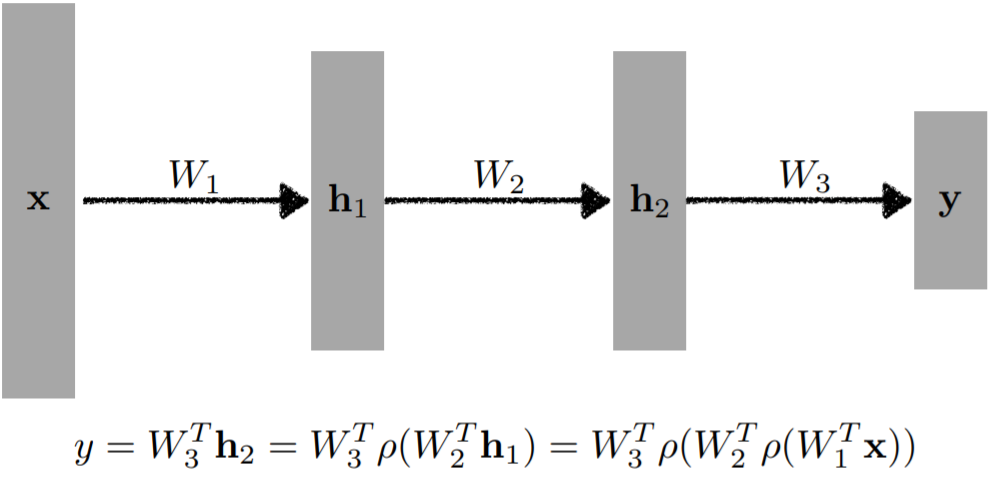
여기서 중요한 것은 단순히 선형 변환만 쌓으면 의미가 없다는 것이다. 선형 변환만 쌓게 되면, 그것은 결과적으로 복잡한 선형 변환을 1번 한 것이랑 차이가 없다. (f(ax + by) = af(x) + bf(y)의 성질 때문) 딥러닝에서는 반드시 "비선형변환"을 틈틈이 넣어서 모델을 복잡하게 해야한다. (정확히는 non-linear하게 만드는 것이다.) 그래야지 모델의 표현 가능한 범위가 커질 수 있게 된다. 이 비선형변환을 하는 것은 보통 활성화함수(activation function)를 씌우는 것으로 진행한다. 활성화함수는 다음과 같이 ReLU, Sigmoid, Hyperbolic Tangent(Tanh)등이 있다.

이 함수들은 다음과 같은 식으로 나타낸다.



출처 : https://ganghee-lee.tistory.com/32
활성화 함수(activation function)종류 및 정리
<활성화 함수 종류> <시그모이드(Sigmoid)> 수식 : output값을 0에서 1사이로 만들어준다. 데이터의 평균은 0.5를 갖게된다. 위 그림에서 시그모이드 함수의 기울기를 보면 알 수 있듯이 input값이 어느
ganghee-lee.tistory.com
그리고 loss에 사용하는 function도 모델에 따라 여러 가지가 있다. 위에서는 MSE를 사용하였는데, 그 외에도 다음과 같은 것들이 있다. MSE는 Mean Squared Error, CE는 Cross Entropy, MLE는 Maximum Likelihood Estimation이다.

'Naver BoostCamp AI Tech 3기' 카테고리의 다른 글
| [DL Basic] 7강 RNN, LSTM, GRU (1) | 2022.02.08 |
|---|---|
| [DL Basic] 3강 Optimization (0) | 2022.02.07 |
| [Python] 5강 (0) | 2022.02.06 |
| Sequence to Sequence Learning with Neural Networks (1) | 2022.02.03 |
| [Python] 4강 (0) | 2022.01.30 |