2022. 2. 3. 23:41ㆍNaver BoostCamp AI Tech 3기
Abstract
Deep Neural Network(DNN, 깊은 신경망, 딥러닝)은 어려운 task 학습에서 완벽한 성능을 보여준 모델이다. 비록 DNN은 label이 있는 거대한 training set이 있을 때에는 좋은 성능을 보여주지만, sequence를 sequence에 mapping하는 경우에는 사용될 수가 없다. 이번 논문에서는, sequence 학습에 대한 일반적인 end-to-end 접근법을 보여준다. 그리고 이 sequence 학습에 대해서 sequence 구조에는 최소한의 가정을 하게된다. 이 논문에서 연구팀은 input sequence를 고정된 차원의 vector에 mapping시키기 위해서 여러 층의 LSTM(Long-Short Term Memory)을 사용하고, 이 vector로부터 target sequence(output sequence)를 decode하기 위해서 또 다른 여러 층의 LSTM을 사용하게 된다. 이 연구팀의 주요 결과는 WMT-14 데이터셋에 대해 진행한 영어 -> 프랑스어 번역 task에서 LSTM을 이용한 번역은 전체 test set에 대해 BLEU score 34.8을 얻었고, 여기서 이 LSTM의 BLEU score는 Out-Of-Vocabulary(OOV, 단어 목록에서 없는 단어를 의미함) 단어들에 의해 감점이 된 점수이다. 게다가, 이 LSTM은 긴 문장들을 큰 어려움 없이 소화하였다. 이와 비교를 위해서 살펴보면, Statistical Machine Translation(SMT, 통계 기계 번역, 1949년에 도입되었고, 딥러닝 기반 번역 이전에 가장 널리 연구된 방식임) system은 같은 데이터셋에 대해서 BLEU score 33.3을 얻었다. 여기서, 이 LSTM을 앞서 언급한 SMT system에 의해 생성된 1000개의 hypothesis들을 rerank할 때 사용했는데, 이때 BLEU score는 36.5까지 상승하였고, 이는 이전의 state-of-the-art(최신식의, 주로 딥러닝 분야에서는 최고 성능을 의미함)와 근접한다. 이 LSTM은 또한 단어의 순서에 민감하고, 비교적 능동태와 수동태에 불변한(덜 민감하다 봐야할듯함) sentence representation(문장에 대한 문맥 정보를 vector에 표현하는 것)과 sensible한 phrase를 학습하였다. 마지막으로, 이 연구팀은 모든 source sentence들(input sequence를 의미)(target sentence는 제외) 내의 단어의 순서를 뒤집는 것이 LSTM의 성능을 현저하게 상승시켰다는 것을 발견하였다. 이는 왜냐하면 이렇게 순서를 뒤집는 것이 source sentence와 target sentence 사이의 많은 short-term dependency를 도입하며, 이는 최적화 문제를 더 쉽게 만들어주기 때문이다.
1 Introduction
Deep Neural Networks(DNN)은 speech recognition(음성 인식)이나 visual object recognition(시각적 개체 인식)등과 같은 어려운 문제(task)에서 엄청난 성능을 달성한 어마어마하게 강력한 머신러닝 모델이다. DNN이 강력한 이유는 바로 이 DNN은 적당한 스텝 수로 임의의 병렬 계산이 가능하기 때문이다. DNN의 위력에 대한 놀라운 예시 중 하나는 quadratic size가 [27]인 hidden-layer 2개만 사용하여서 N-bit 숫자들을 정렬한 것이다. 비록 neural network들이 기존의 statistical model(통계 모델)들과 연관되어 있지만, neural network는 난해한(복잡한) 계산을 학습하게 된다. 게다가, label이 있는 training set에서 이 network의 parameter들을 특정하기 위한 충분한 정보를 가지고 있다면, supervised backpropagation을 통해서 이 커다란 DNN은 학습될 수 있다. 그래서, 만약에 이 커다란 DNN에서 좋은 성능을 낼 수 있는 parameter setting이 존재한다면, supervised backpropagation을 통해 이 parameter setting을 찾아내고 주어진 문제를 해결할 수 있을 것이다.
그러나 이 DNN의 유연성과 성능에도 불구하고, DNN은 input과 target이 고정된 차원의 vector로 현명하게(sensibly) 잘 encode가 될 수 있는 문제에만 적용될 수 있다. 이건 아주 중요하게 여길 한계점인데, 왜냐하면 많은 중요한 문제들은 length가 사전에 알 수 없는 sequence들로 표현이 되기 때문이다. 예를 들어, speech recognition(음성 인식)과 machine translation(기계 번역)은 sequential problem이다. 이와 비슷하게, question answering(QA, 질의응답) 또한 질문을 표현하는 word의 sequence를 대답을 표현하는 word의 sequence에 mapping하는 것으로 볼 수 있다. 그러므로, domain에 상관없이 sequence를 sequence에 mapping하는 방식이 유용할 것이란 것은 자명하다.
Sequence로 인하여 DNN은 challenge를 맞이하게 되었는데, 왜나하면 DNN의 경우에는 input과 output의 차원을 알아야하고, 고정되어야 하기 때문이다. 이번 논문에서, LSTM 아키텍처의 직관적인(복잡하지 않은, straightforward) 적용을 통해 일반적인 sequence to sequence 문제를 해결할 수 있다는 것을 보여줄 것이다. 이 아이디어는 바로, 하나의 LSTM을 한 번에 한 timestep씩 input sequence를 읽는 데 사용하고, 이를 통해 커다란 고정된 차원의 vector representation을 얻게 된다. 그리고 이 vector로부터 output sequence를 추출하기 위해서 또 다른 LSTM을 사용하게 된다. 자세한 그림은 다음과 같다.
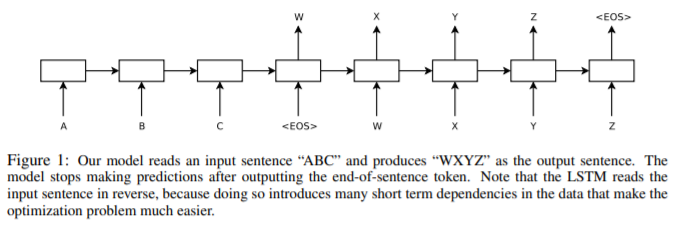
여기서 두번째 LSTM은 input sequence에 의해 영향을 받는 것을 제외하고, 반드시 recurrent neural network 언어 모델이여야 한다. LSTM은 일시적인 장기 의존성을 가지는 data에 대해 학습을 잘할 수 있기 때문에, input과 이에 상응하는 output 사이의 적지 않은 시간의 지연을 가지는 이 문제에서, LSTM을 사용하는 것은 적절하다 볼 수 있다.
지금까지 neural network를 이용하여 일반적인 sequence to sequence 학습을 하는 문제를 해결하려 했던 수많은 관련된 시도들이 있었다. 이 연구팀의 접근법은 Kalchbrenner and Blunsom과 가까이 연관되어 있는데, 이들은 처음으로 전체 input sentence를 vector로 mapping하려는 시도를 하였었다. 또한 Cho et al.에서의 접근법과 매우 유사하다. Graves는 새로운 미분 가능한 attention 메커니즘을 소개하였는데, 이 메커니즘은 neural network가 input에서의 다른 파트들에 focus 할 수 있게 만들어주고, 이 아이디어의 훌륭한 변종이 Bahdanau et al.에 의해서 기계 번역에 성공적으로 적용되었다. The Connectionist Sequence Classification(입력 음성 프레임 시퀀스와 타겟 단어/음소 시퀀스 간에 명시적인 얼라인먼트(alignment) 정보 없이도 음성 인식 모델을 학습할 수 있는 기법, CTC와 연관 있어 보임)은 neural network를 사용하여 sequence에 sequence를 mapping하는 또 다른 인기있는 테크닉이며, 이 테크닉은 input과 output 사이의 monotonic alignment(n번째의 Input에 대해 몇번째의 Output을 주목해야 하는지 계산하는 방식)를 가정한다고 한다.
이 연구에서 주요한 결과는 다음과 같다. WMT-14에서의 영어 -> 프랑스어 번역 task에서는, BLEU score 34.81을 얻어냈고, 이는 단순한 left-to-right beam-search decoder를 사용하여 5개의 deep LSTM(각각 380M개의 parameter를 가짐) ensemble로부터 translation을 직접 뽑아낸 것이다. 이는 지금까지 neural network를 통해 직접 뽑아낸 translation의 결과들 중 제일 좋게 나온 결과이다. 비교를 위해 살펴보면, 이 데이터셋에 기반하여 만든 SMT baseline의 BLEU score는 33.30이다. 여기서 34.81 BLEU score는 80k 단어들의 vocabulary와 LSTM에 의해 얻어진 점수이며, 그래서 이 점수는 vocabulary의 80k 단어 중 없는 단어가 들어간 문장에 대한 translation에서는 감점을 받았다. 이 결과로 알 수 있는 것은, 비교적 덜 최적화 된 neural network 아키텍처(즉, 개선의 여지가 훨씬 많이 있는 아키텍처)가 완전한(앞과 대조하여 보면 개선의 여지가 거의 없다고 볼 수 있는 아키텍처) phrase-based SMT system을 성능에서 압도했다는 것이다.
마지막으로, 이 연구팀은 LSTM을 또다른 task(Abstract에서 언급됨)에서 SMT baseline의 1000개의 best-list들의 점수를 다시 매기는 데에 사용하였다고 한다. 여기서는, BLEU score 36.5를 달성하였고, 기존 SMT baseline의 점수보다 3.2점 더 높았으며, 기존의 State-of-the-art인 37.0과 상당히 근접하였다.
놀랍게도, 다른 연구자들이 이와 관련된 아키텍처를 사용해 근래에 진행된 연구와는 다르게, 이 LSTM은 매우 긴 문장에 강건했다는 것이다. 이는 왜냐하면 training set과 test set에서 source sentence에서 단어의 순서를 거꾸로 하였기 때문이다.(target은 제외) 이렇게 함으로써, 최적화 문제를 훨씬 더 간단하게 해준 많은 short term dependency들을 도입하였다. 결과적으로, SGD(Stochastic Gradient Descent)는 긴 문장에 대해 무리 없이 LSTM을 학습할 수 있었다. 이 단어의 순서를 뒤집는다는 간단한 트릭이 이 연구에서 기술적인 기여를 한 것이다.
이 LSTM에서의 유용한 특성은 바로 이 LSTM은 가변 길이의 input sentence를 고정된 차원의 vector representation으로 mapping하는 것을 학습한다는 것이다. translation이 source sentence의 의역(paraphrase)인 경향이라는 점에서, 이 translation의 목적은 LSTM이 번역되는 문장의 의미를 담는 sentence representation(이게 결국 vector다)을 찾도록 하는 것이며, 이에 따라 비슷한 의미의 문장들은 서로 가깝고, 반면에 다른 의미의 문장들은 서로 멀게 되는 것이다. 질적 평가는 이 주장을 뒷받침해주고, 이 LSTM 모델은 단어의 순서를 알아차리고, 능동태와 수동태에 똑같이 불변하다는 것을 보여준다.
2 The model
The Recurrent Neural Network(RNN)은 sequence에 대한 feedforward neural network의 자연스러운 일반화이다. input sequence(x1, ..., xT)가 주어졌을 때, 표준 RNN은 다음과 같은 방정식을 반복함으로써, output sequence(y1, ..., yT)를 계산하게 된다.
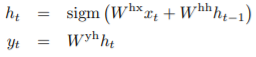
RNN은 input과 output 사이의 alignment를 사전에 알 수 있는 한, 쉽게 sequence에 sequence를 mapping하는 것이 가능하다. 그러나, input과 output sequence들이 서로 다른 길이를 가지고, 복잡하고 비단조로운(non-monotonic) 관계를 가지는 문제 상황에서는 RNN을 어떻게 적용해야 할 지 명확하지 않다.
일반적인 sequence 학습을 위한 간단한 전략은 하나의 RNN을 사용하여서 input sequence를 고정된 차원의 vector에 mapping하는 것이고, 그 후에는 이 vector를 또다른 RNN을 하나 사용하여서 target sequence에 mapping하는 것이다. RNN이 관련된 모든 정보가 제공된 상태에서는 원칙적으로 잘 동작하긴 하지만, 결과적으로 장기 의존성(long term dependencies)으로 인해 RNN을 훈련시키기는 어려울 것이다. 그러나, LSTM의 경우는 이 장기 의존성이 있는 문제를 학습할 수 있다고 알려져 있으므로, 이러한 상황에서는 LSTM이 성공적인 성능을 보일 것이다.
LSTM의 목표는 다음과 같다. 조건부확률 p(y1, ..., yT' | x1, ..., xT)를 추정하는 것이다. 이때, (x1, ..., xT)는 input sequence이고, (y1, ..., yT')는 이 input에 상응하는 output sequence이다. 여기서, input sequence의 길이인 T와 output sequence의 길이인 T'은 서로 다를 수 있다. LSTM은 input sequence (x1, ..., xT)의 고정된 차원의 representation인 v를 얻는다. v는 이 LSTM의 마지막 hidden state를 통해 얻을 수 있다. 그리고 이 v는 표준적인 LSTM-LM(LSTM을 사용한 Language Model)의 초기 hidden state로 사용되고, 이를 통해 (y1, ..., yT')의 확률을 계산한다. 이 과정을 통해서 위에서 언급한 조건부확률을 계산할 수 있다. 이는 다음과 같은 식으로 표현할 수 있다.

이 방정식에서, 각각의 p(yt | v, y1, ..., yt-1) 분포는 vocabulary내의 모든 단어들에 대한 softmax로 표현이 된다. 이 연구팀은 Graves로부터의 LSTM 공식을 사용한다. 여기서 주목해야할 점은, 각각의 문장은 문장의 끝을 의미하는 특별한 토큰인 <EOS>(End-Of-Sequence) 토큰으로 끝나야 한다는 것이다. 이 토큰은 가능한 모든 길이의 sequence들의 분포를 정의할 수 있게 해준다. 전반적인 scheme은 위에서 요약된 Fig.1에 있으며, 그 그림에서 보여지는 LSTM은 "A" "B" "C" "<EOS>" 의 representation을 계산하고 있다. 그리고 이 representation으로 "W" "X" "Y" "Z" "<EOS>"의 확률을 계산하는 데에 사용한다.
이 연구팀이 사용한 실제 모델은 위에서 언급한 모델과는 중요하게 3가지 부분에서 차이점이 있다. 첫 번째는, 모델에서 2개의 서로 다른 LSTM을 사용했다. 하나는 input sequence를 위해서, 나머지 하나는 output sequence를 위해서인데, 이렇게 하는 정도로는 무시할 수 있을 정도의 연산량의 모델 parameter 수를 증가시키면서, 반면에 LSTM을 다양한 언어 pair들에 대해 동시에 훈련시킬 수 있게 된다. 두 번째는, deep LSTM이 shallow LSTM의 성능을 상당히 압도하는 것을 발견하였고, 그래서 4층으로 이루어진 LSTM을 사용하였다. 세 번째는, input sequence의 단어의 순서를 뒤집는 것이 매우 가치가 있다는 것을 발견했다. 예를 들어, 문장 a b c를 문장 α, β, γ로 mapping 하는 것 대신에, LSTM은 문장 c b a를 문장 α, β, γ로 mapping 하도록 요구된다. 여기서 문장 α, β, γ는 실제로는 문장 a b c를 표현한 것이다. 이 방식을 이용하면, a는 α와 근접하게 되고, b는 β와 근접하게 되며, 이런 식으로 나아간다. 이것은 SGD가 input과 output 사이에 서로 "establish communication"을 하기 쉽게 만들어준다. 이 간단한 데이터 변환 방식이 LSTM의 성능을 비약적으로 상승시켜 주었다.
3 Experiments
이 연구팀은 WMT'14 기반 영어 -> 프랑스어 기계 번역 task에 위에서 언급한 방법론을 2가지 방식으로 적용하였다. 하나는 관련 SMT system 없이 input sentence를 직접 번역한 것이고, 다른 하나는 SMT baseline의 n개의 best list들의 점수를 다시 매기는 데에 사용하였다. 이제부터 이 번역 방식들의 정확도에 대해 말하고, 예시 translation들을 보여주고, sentence representation들의 결과를 시각화 할 것이다.
3.1 Dataset details
이 연구팀은 WMT'14 영어 -> 프랑스어 데이터셋을 사용하였다. 연구팀에서는 348M개의 프랑스어 단어와 304M개의 영어 단어로 이루어진 12M개의 문장들 중에서 잘 선택된 subset으로부터 이 모델을 훈련시켰다. 이 translation task와 이 특정 훈련 데이터셋을 선택한 이유는 baseline SMT의 1000개의 best list와 함께 토큰화된 훈련 데이터셋과 테스트 데이터셋을 사용하기 위해서이다.
기존의 언어 모델은 각 단어의 vector representation에 의존하기 때문에, 이 연구팀에서는 양쪽 언어에 대한 고정된 vocabulary를 사용하였다. source language에서 가장 빈번한 16만개의 단어를 사용하였고, target language에서 가장 빈번한 8만개의 단어를 사용하였다. 모든 OOV 단어들은 특별한 토큰인 "UNK" 토큰으로 대체되었다.
3.2 Decoding and Rescoring
이번 실험에서의 핵심에는 많은 문장 쌍들에 대한 거대한 deep LSTM을 훈련시키는 것이 포함되었다. 연구팀에서는 이 deep LSTM을 조건부확률 p(T | S)의 로그확률을 극대화하는 방식으로 훈련시켰는데, 여기서 T는 올바른 translation, S는 source sentence이다. 그래서, training의 objective는 다음과 같다.

여기서 왼쪽에 있는 S는 training set을 의미한다. 훈련이 완료되면, LSTM에 의하여 가장 그럴 듯한 translation을 찾음으로써 output을 배출해낸다.

연구팀에서는 단순한 left-to-right beam search decoder(beam search는 각각의 timestep에서 가장 그럴듯한 k개의 sequence를 선택하여 탐색해나가는 기법임)를 사용하여 가장 그럴 듯한 translation을 찾아낸다. 이 decoder는 부분 가설(partial hypotheses)들의 작은 숫자 B를 유지하는데, 여기서 부분 가설은 일부 translation의 prefix이다. (무슨 말인지 모르겠다 잘) 각각의 timestep에서 빔 안에 있는 각각의 부분 가설들을 vocabulary 내의 모든 가능한 단어들과 함께 확장해나간다. 이는 가설의 숫자를 매우매우 크게 증가시키므로, B를 제외한 모든 가설은 discard 하게 되었다. 여기서 B는 model의 log 확률에 의하여 가장 그럴듯한 가설들이다. 가설에 <EOS> 토큰이 추가되자마자, 그 가설은 beam에서 제거되고, 완성된 hypothesis의 조합에 추가된다. 이 decoder가 적절하면서도, 구현하기가 간단하다. 놀랍게도, 이 연구팀의 system에서는 beam의 size가 1일때 마저도 잘 동작하였고, beam의 size가 2이면 beam search의 장점을 극대화할 수 있었다.
이 연구팀은 또한 LSTM을 baseline system에 의해 생성된 1000-best list들을 점수를 다시 매기는데에 사용하였다. n-best list들을 점수를 다시 매기기 위해서, LSTM과 함께 모든 가설들의 log 확률을 계산하였고, 이 가설들의 점수와 LSTM의 점수의 even average를 얻게 되었다.
3.3 Reversing the Source Sentences
LSTM이 장기 의존성을 가진 문제를 해결하는 데에 능력이 있는 와중에, 이 연구팀에서는 source sentence들의 순서가 거꾸로 뒤집어 진 경우에 LSTM이 훨씬 더 잘 학습한다는 것을 알아냈다. (단, target sentence는 그대로이다.) 이렇게 뒤집음으로써, LSTM의 test perplexity(PPL, 언어 모델을 평가하기 위한 평가 지표)가 5.8에서 4.7로 감소하였고, translation의 test BLEU score는 25.9에서 30.6으로 상승하였다. 즉, 성능이 향상된 것이다.
비록 이 연구팀에서도 이 현상에 대한 완벽한 설명을 하지는 못하지만, 이 연구팀에서는 이것이 데이터셋에 대해 많은 단기 의존성을 도입함으로써 발생했다고 생각한다. 일반적으로, source sentence와 target sentence를 결합하면, source sentence의 각 단어들은 target sentence의 상응하는 단어들과 서로 멀리 떨어져 있게 된다. 결과적으로, 이 문제는 커다란 “minimal time lag”를 가지게 된다. source sentence의 단어들을 뒤집음으로써, source 언어와 target 언어 간의 상응하는 단어들 사이의 평균 거리가 변화하는 것은 아니다. 그러나, source 언어에서 처음 몇 개의 단어는 target 언어의 첫 몇 개의 단어들과 매우 가깝게 되며, 이 문제에서 minimal time lag는 매우 매우 감소하게 된다. 그러므로, backpropagation은 source 문장과 target 문장 사이의 “establishing communication” 시간을 더 쉽게 가지고, 이에 따라서 결과적으로 전반적인 성능의 향상이 나오게 된다.
처음에는, 이 연구팀에서는 input sentence를 뒤집는 것은 그저 target sentence의 초기 부분만 더 확실히 예측하는 것에 그치고, 그 이후의 부분들은 예측이 더 불확실할 것이라고 생각했었다. 그러나, 뒤집어진 source sentence을 토대로 학습된 LSTM은 일반 문장으로 학습된 LSTM보다 긴 문장에서 훨씬 더 좋은 성능을 보여줬고, 이는 input sentence의 문장을 뒤집는 것이 LSTM에서 더 좋은 메모리 효율을 보여준다고 할 수 있다.
3.4 Training details
연구팀에서는 LSTM 모델들이 비교적 훈련이 쉽다는 것을 알아냈다. 연구팀은 4개 layer의 deep LSTM을 사용하였고, 각 layer는 1000개의 cell이 있고 1000개 차원의 word embedding이 있고, input vocabulary는 16만개의 단어로 이루어지고, output vocabulary는 8만개의 단어로 이루어져 있다. 연구팀에서는 deep LSTM을 shallow LSTM의 성능을 상당히 압도한다는 것을 알아냈고, 여기서 각각의 추가적인 layer는 거의 10% 정도의 perplexity를 감소시켰고, 이는 아마 훨씬 큰 hidden state 때문일 것이다. 연구팀은 각각의 output에 대해 8만개의 단어에 대한 naïve softmax를 사용하였다. 최종적으로 LSTM은 380M개의 parameter를 가지고 있고, 이 중 64M개는 순수 재귀적인 connection들이다.(32M개는 “encoder” LSTM의 parameter이고, 나머지 32M개는 “decoder” LSTM의 parameter이다.) 훈련의 완전한 세부사항은 다음과 같다.
- LSTM의 모든 parameter들은 -0.08~0.08의 범위를 갖는 균일분포로 초기화하였다.
- 모멘텀을 사용하지 않고 SGD를 사용하였고, 학습률은 0.7로 고정이였다. 5 epoch가 지난 후에는, epoch의 절반이 지날 때 마다 학습률을 절반으로 줄이기 시작하였다. 모델은 총 7.5 epoch 동안 훈련하였다.
- gradient를 위해서 128개의 sequence들의 batch(batch_size=128)을 사용하였고, gradient를 batch의 size인 128로 나누었다.
- 비록 LSTM이 vanishing gradient 문제를 겪지 않는 편이지만, 대신에 exploding gradient 문제를 겪을 수 있다. 그러므로, 연구팀에서는 gradient의 norm이 threshold를 초과하게 되는 경우, norm을 조정해주는 강한 제약을 가했다. 각 훈련 배치마다, s = ||g||2를 계산하였고, 여기서 g는 128로 나누어지는 gradient이다. 만약 s > 5이면, g = 5g / s를 통해 g를 수정한다.
- 각각 다른 문장은 다른 길이를 가진다. 대부분의 문장은 짧은 반면(보통 길이가 20~30), 몇몇 문장은 길다.(길이가 100을 넘어감) 그래서 훈련 문장 중 랜덤하게 고른 128개의 문장의 mini-batch는 많은 짧은 문장이 있고 몇몇 긴 문장이 있을 것이다. 그리고 결과적으로 mini-batch 내의 많은 계산들은 낭비될 것이다. 이 문제를 다루기 위해서, 연구팀에서는 mini-batch 내의 모든 문장들이 거의 같은 길이가 되도록 하였고, 이로 인해 속도가 2배 빨라졌다.
3.5 Parallelization
1개의 GPU로 위에서 언급한 configuration으로 deep LSTM을 C++로 구현했을 때, 초당 대략 1700개의 단어들을 처리한다. 이는 연구팀의 목적에 비해 매우 느린 편이였으며, 그래서 연구팀은 8-GPU 기계를 사용하여 모델을 병렬화 하였다. LSTM의 각 layer는 각각 다른 GPU에 의해 실행되었고, 계산이 완료되는 대로 다음 GPU(다음 layer)로 activations를 전달하였다. 이 모델에서는 LSTM이 4개의 layer가 있으며, 각각의 layer는 분리된 GPU에 위치하였다. 남은 4개의 GPU는 softmax를 병렬화 하는 데에 사용하였고, 그래서 각각의 GPU는 1000 x 20000 행렬을 곱하는 역할을 하였다. 최종적인 구현은 size가 128인 mini-batch에 대하여 초당 6300개의 단어를 처리하는 속도를 얻었다. 이 구현에서 훈련은 대략 10일 정도 진행되었다.
3.6 Experimental Results
BLEU score에 관한 표의 이야기들이므로 생략함.


3.7 Performance on long sentences
놀랍게도 LSTM은 긴 문장들에 대해 잘 동작했으며, figure 3에 양적으로 잘 묘사되어 있다. Table 3는 긴 문장들과 그 translation들의 여러 예시를 보여준다.


3.8 Model Analysis
이 모델에서의 매력적인 특징들 중 하나는 단어의 sequence를 고정된 차원의 vector로 변환하는 능력이다. Figure 2에서는 몇몇 학습된 representation들을 시각화 하고 있다. 이 figure는 representation이 단어들의 순서에 민감한 반면에, 능동태를 수동태로 바꾼 것에는 덜 민감하다는 것을 명확히 보여주고 있다. 2차원의 projection은 PCA를 사용하여 얻어냈다.

4 Related work
neural network를 기계 번역에 적용하는 것에 관한 많은 연구가 있다. 지금까지, RNN-Language Model(RNNLM) 또는 Feedforward Neural Network Language Model(NNLM)을 기계 번역 task에 적용하는 가장 간단하고 효율적인 방식은 강력한 MT baseline의 n-best list들을 rescore하는 것이며, 이는 translation의 quality를 신뢰성 있게 향상시켜준다.
더 최근에는, 연구자들은 source language에 대한 정보를 NNLM에 포함시키는 방법들을 찾아보기 시작하였다. 이런 연구의 예시로는 Auli et al.이 있고, 여기서는 NNLM을 input sentence의 topic model과 결합시킨 예시이며, 이는 rescoring 성능을 향상시켜준다. Devlin et al.도 비슷한 접근법을 따랐으나, 그들은 NNLM을 기계 번역 시스템의 decoder에 사용하였고, decoder의 alignment 정보를 NNLM에게 input sentence의 가장 유용한 정보들을 제공하기 위해 사용하였다. 이러한 접근법은 매우 성공적이였고, 그들의 baseline보다 큰 성능 향상을 얻게 되었다.
이 논문의 연구팀의 연구는 Kalchbrenner and Blunsom과 꽤 관련이 있으며, Kalchbrenner and Blunsom은 input sentence를 vector로 mapping하고 이 vector를 다시 sentence로 mapping하는 시도를 처음으로 한 사람들이다. 그렇지만, 그들은 이 mapping을 CNN을 사용하여 시도했으며, 이는 단어들의 순서 정보를 잃어버리는 결과로 이어졌다. 이 연구와 비슷하게, Cho et al.은 LSTM 같은 RNN 아키텍처를 사용하여 sentence를 vector에 mapping 하였고, 역으로 돌렸다. 그렇지만, 그들의 주요 관심 초점은 그들의 neural network를 SMT system에 통합하는 데에 있었다. Bahdanau et al.은 또한 긴 문장에 대한 안 좋은 성능(Cho et al.이 경험하였음)을 극복하기 위하여 attention 메커니즘을 사용한 neural network로 direct translation을 시도하였었다. 그리고 괜찮은 결과를 얻었다. 비슷하게, Pouget-Abadie et al.은 Cho et al.의 memory 문제를 다루기 위해 source sentence의 조각들을 smooth translation을 만드는 방식으로 번역하는 방법을 시도 했었고, 이는 phrased-based 접근법과 비슷하다. 이 논문의 연구팀은 단순히 source sentence를 거꾸로 뒤집어서 network를 훈련시켰으면 비슷한 성능을 내지 않았을까 하는 생각을 해본다.
End-to-end 훈련은 또한 Hermann et al.의 관심 초점인데, 여기의 model은 input과 output을 feedforward network로 표현하고, 이들을 공간상의 비슷한 점으로 mapping 한다. 그러나, 그들의 접근법은 translation을 directly하게 생성할 수 없고, translation을 얻기 위해서는 미리 계산된 sentence들의 database 내의 가장 가까운 vector를 찾던가, 혹은 sentence를 rescore 해야 한다.
5 Conclusion
이번 연구에서, vocabulary가 제한된 상태에서 거대한 deep LSTM은 대규모 기계 학습 task에 대한 vocabulary의 제한이 없는 standard한 SMT 기반 시스템의 성능을 압도할 수 있다는 것을 보여줬다. 이 간단한 LSTM 기반의 기계 학습에 대한 접근의 성공은, 충분한 훈련 데이터가 주어진 상태에서, 이 방식이 다른 많은 sequence 학습 문제에 대해 잘 동작할 것이라고 암시할 수 있을 것이다.
연구팀에서는 source sentence들의 순서를 뒤집는 방식으로 얻은 엄청난 성능 향상에 놀라워했다. 이들의 결론은, short term dependencies를 엄청 많이 얻을 수 있는 방식으로 문제를 encoding하는 방식을 찾는 것이 중요하다는 것이다. 왜냐하면, 이를 통해서 학습 문제를 매우 간단히 할 수 있어서이다. 특히, fig. 1에서 보였다시피, translation 문제를 순서를 뒤집지 않고 standard한 RNN으로 훈련시키는 것은 불가능했지만, source sentence의 순서를 뒤집으면 standard한 RNN이 쉽게 학습이 가능할 것이라고 생각한다.(그렇지만, 이것은 실험적으로 증명하지는 않은 부분이다.)
또한, 매우 긴 문장들을 성공적으로 번역하는 LSTM의 성능에 놀라워했다. 연구팀은 초창기에는 제한된 memory로 인하여 긴 문장들을 LSTM이 학습하는 것은 실패할 것이라 생각하였고, 다른 연구팀 역시 긴 문장에 대해서는 안 좋은 성능을 보인다고 보고하였다. 그럼에도 불구하고, 데이터셋을 뒤집었을 때 훈련시킨 LSTM은 긴 문장을 번역하는 데에는 문제가 거의 없는 상태이다.
가장 중요한 것으로, 이 연구팀에서는 간단하고, 직관적이고, 비교적 덜 최적화 된 접근법이 기존의 SMT 시스템을 성능에서 압도한다는 것을 증명하였고, 이로 인해 이후의 연구들은 아마 훨씬 더 좋은 번역의 정확도를 얻어낼 수 있을 것이다. 이러한 결과들은, 이 연구팀의 접근법이 다른 sequence to sequence 문제들에 대해 잘 동작할 것이라고 암시하고 있다.
6 Acknowledgments
감사인사 및 레퍼런스들이므로 생략함.
요약
- sequence에 sequence를 mapping 시키기 위해서, RNN계열의 구조를 encoder와 decoder에 각각 사용하였다. 논문에서는 긴 문장에 대응하기 위해서 그냥 RNN이 아닌 LSTM을 사용하였다.
- encoder에 들어가는 것은 번역을 당하는 언어 이며, 1개의 단어씩 LSTM cell에 재귀적으로 들어가게 된다. 이때, 중요한 것은 문장이 끝나는 지점에는 스페셜 토큰인 <EOS>가 들어가야 한다. 그렇게 해서 <EOS> 토큰이 들어가게 되면, encoder에서 계산된 마지막 hidden state를 vector로 사용하는 것이다.
- vector는 원래 문장의 의미와 문맥을 숫자(vector)로 암호화(encode)시킨 것이다. 이렇게 원래 문장이 vector화 되면, 이 vector를 decoder LSTM의 첫 번째 hidden state로 사용한다.
- decoder는 encoder와는 반대로 번역을 하는 언어의 단어들이 재귀적으로 들어가게 된다. 이를 통해 번역된 단어들이 하나씩 나오다가, <EOS> 토큰을 뱉게 되면, 번역 과정을 종료한다.
- 특이점으로는 encoder에 들어가는 입력 문장의 순서를 뒤집어서 넣으면 성능이 매우 향상되었다는 것이다. 이는 뒤집어버리게 되면, 초반에 입력 문장의 부분과 출력 문장의 부분이 매우 가까워지는 현상이 발생하면서, time-lag를 줄이고 long-term dependency보다는 short-term dependency들로 바뀌게 되면서 초반 backpropagation이 쉬워지게 된다. 그에 따라 올바른 번역의 확률이 올라가는 것 같다.
- 스페셜 토큰들로는 <EOS>와 <UNK>가 있다. <EOS>는 End-Of-Sentence를 의미하며, 문장이 끝나는 지점에 들어가는 토큰이다. <UNK>는 Unknown을 의미하며, Vocabulary에 없는 단어를 마주하게 되면 이 토큰으로 변경하여 들어가게 된다.
- shallow LSTM보다는 deep LSTM이 성능이 더 좋다.
- decoder에서 번역 결과를 탐색할 때는 beam search를 사용하였다고 한다. 이는 NLP에서 많이 사용하는 탐색 방식이라고 하는데, 논문에서의 그림은 가장 높은 확률을 가지는 단어가 다음 입력으로 들어가면서 문장을 뽑아낸다.
- 그런데 이 방식은 greedy search이며, 실제 beam search는 beam-size만큼 개수의 정답 후보들을 유지하면서 문장을 생성해낸다. 예를 들어서, beam size가 5라면, timestep마다 가장 정답이 될 확률이 높은(즉, 조건부확률이 제일 높은) 상위 5개 문장들을 유지한다. 이렇게 timestep마다 가장 높은 확률의 5개의 문장들을 유지하면서 translate 과정이 진행되고, <EOS> 토큰이 나오면 그 문장은 거기서 translate를 종료한다. 그렇게 해서 나온 5개의 문장 중 가장 확률이 높은 문장을 translation의 결과로 배출한다.
- beam-size를 크게 할수록, 정답인 문장을 뽑아낼 확률이 높아지지만, 탐색에 시간이 오래걸리고 메모리를 많이 사용하므로, 적당한 size를 잡아야 한다.
'Naver BoostCamp AI Tech 3기' 카테고리의 다른 글
| [DL Basic] 2강 MLP (0) | 2022.02.07 |
|---|---|
| [Python] 5강 (0) | 2022.02.06 |
| [Python] 4강 (0) | 2022.01.30 |
| [Python] 3강 (1) | 2022.01.28 |
| [Python] 2강 (0) | 2022.01.27 |