2022. 1. 28. 13:36ㆍNaver BoostCamp AI Tech 3기
collections 모듈 : List, Tuple, Dict에 대한 Python Built-in 확장 자료 구조(모듈)
deque : Stack & Queue를 모두 지원하는 자료구조, rotate 및 reverse 등의 Linked List에 있는 특성 역시 지원이 된다. 기존 List 형태의 함수 역시 지원이 된다.




append는 일반 List에서 처럼 deque의 오른쪽에 원소를 추가한다. appendleft는 deque의 왼쪽에 원소를 추가한다.
rotate를 사용하게 되면, 현재 원소들의 위치를 기준으로 argument만큼 오른쪽으로 밀게 된다. 맨 오른쪽에 도달 시 맨 왼쪽으로 돌게 된다. 여기서는 rotate(2)이므로 2칸씩 회전하는 것이다.
reversed는 deque 전체를 뒤집는 것으로 맨오른쪽부터 맨왼쪽까지 순서가 뒤바뀐다. extend는 deque의 오른쪽에 원소가 추가되며, extendleft는 왼쪽으로 추가되는데, 원소의 순서가 뒤집혀서 붙게 된다는 특징이 있다.
중요한 점은, deque은 일반 List보다 효율적인 자료구조(메모리 구조가 효율적임)가 제공되어서, 처리 속도가 더 빠르다!
OrderedDict : dictionary와 달리 입력 순서를 보장하는 자료구조이지만.. Python 3.6부터는 일반 dictionary도 순서가 보장이 되므로, 큰 의미 없는 자료구조이다.
defaultDict : 일반 dictionary와 달리 dict type의 값에 기본값을 지정한다. dict에 없는 원소를 탐색 시 기본값을 출력해준다. 하나의 사용 예시로, 한 텍스트에 단어가 몇개가 있는지 셀 때 사용할 수 있다.
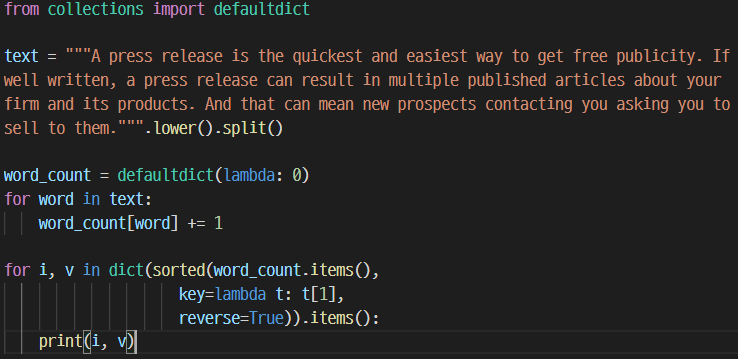

text를 소문자로 전부 바꾸고, 공백을 기준으로 토큰화하였다. word_count라는 defaultdict를 만들고, 기본값은 0으로 하였다. 이러면 각 단어별로 기본값은 처음에 0이며, 단어가 등장 시 1씩 값이 올라가므로 빈도수의 dictionary가 만들어진다. 이후에는, 이 dictionary를 빈도수의 내림차순으로 정렬한 이후에 출력하여 가장 많이 나온 단어 순으로 출력된다.
이에 대해서 좀 더 조사한 결과 다음과 같다.
- defaultdict(lambda: "원하는 기본값") 이렇게 사용하는 것을 StackOverflow에서 추천하고 있다.
- defaultdict(int)는 기본값 0, defaultdict(list)는 기본값 [], defaultdict(set)은 기본값은 ()으로 된다.


이런 식으로 사용할 수 있다. 존재하지 않던 key에 접근 시 그때부터는 기본값으로 defaultdict에 (key, value)로 들어가게 된다.
Counter : Sequence type의 data element의 개수들을 dict 형태로 반환해주는 자료구조. str, dict type, keyword parameter 들 모두 다 처리 가능하다.




이런 식으로 사용할 수 있다. 여기서 elements()는 iterator이다.
추가로 조사한 것은 다음과 같다.


Counter에 for문으로 접근 시 key값이 iterate된다. 그리고 Counter에 자체적으로 most_common() 메소드가 존재하며, parameter가 없으면 빈도의 내림차순으로 전체 다, parameter 값을 주면 그 숫자만큼 빈도 상위 몇 개를 뽑아온다.
그 외에도, set의 연산을 지원해준다.


여기서, -와 subtract는 비슷하지만 차이가 있다. a - b 에서 a에는 원소가 없고 b에만 원소가 있다면, 그 원소는 연산에서 제외된다. 그러나, subtract를 사용 시 a.subtract(b)는 a에 뺄셈 결과가 적용이 되며, b에만 원소가 있으면 a에는 그 원소의 값이 0으로 사용된다. 따라서, b의 원소 개수의 마이너스로 나오게 된다.
&와 |는 각각 교집합과 합집합인데, 교집합은 원소의 개수가 작은 쪽으로 나오게 되며(단, 원소 개수가 0이하인 쪽이 있으면 아예 제외되버림), 합집합은 전부 다 나오게 되고, 중복 시 큰 쪽으로 나오게 된다.
Pythonic Code : 파이썬스러운 코드임. 매우 중요함!! 남의 코드에 대한 이해도가 증가하고, 효율성도 조금 더 좋다.
split & join : split은 string type의 값을 기준값으로 나눠서 리스트 형태로 나눈다! join은 반대로 리스트의 값들을 특정 string을 넣어서 합쳐준다.


list comprehension : 기존 List를 사용하여 다른 List를 간단히 만드는 것으로, for + append보다 조금 더 빠르다. 정말 많이 쓰인다!


이렇게 for문이 2중 for문이라면, for i in word_1이 바깥 loop, for j in word_2는 안쪽 loop가 된다.

if문을 저렇게 붙이면 filter를 적용해 준다. for문 뒤에 붙여도 되고, for문과 statement 중간에 두어도 된다. 단, 중간에 두기 위해서는 else문이 있어야만 한다. if문만 있으면 오류가 난다.

만약, [i + j for i in case_1] for j in case_2 이렇게 되면, one-dimensional과는 다르게 two-dimensional 리스트로 나오게 되며, for j in case_2가 바깥쪽 loop가 되고, for i in case_1이 안쪽 loop가 된다.
enumerate & zip : enumerate는 list의 element 추출 시 번호를 붙여서 같이 추출해준다. zip은 묶어주는 역할이다.



lambda : lambda는 익명 함수이다. 함수를 간단하게 정의할 수 있지만, Python 3부터는 권장하지 않는다. 그러나 여전히 많이 쓰인다. 문제점은 다음과 같다.
- 문법이 어렵다.
- 테스트가 어렵다.
- 문서화 docstring이 미비하다.

map : map은 sequence 형 데이터에 각각 함수를 매핑시킬 때 사용한다. 최근에는 map 대신에 list comprehension으로 대체하는 것을 추천하지만, 여전히 많이 쓴다. Python 3 에서는 이를 iterator로 반환해주므로, 값을 확인하려면 list()를 씌워야만 한다.

이렇게 매개변수가 2개 이상이면, map에 여러 개의 인자를 넣을 시, zip처럼 묶어줘서 잘 처리해준다. 결과는 [2, 4, 6, 8, 10]이 나온다.
reduce : 주로 리스트에서의 누적 집계 시 사용되는 함수이다. 자세한 사용법은 다음과 같다.reduce(집계 함수, 순회 가능한 데이터[, 초기값])집계 함수는 2개의 인자를 받아야 한다. 앞의 인자는 누적자(Accumulator)으로, 함수 실행부터 끝까지 누적하는 값이며, 뒤의 인자는 현재값(Current Value)으로, 루프를 돌면서 계속해서 바뀌는 값이다.


만약, 초기값을 설정하지 않으면, reduce의 두번째 인자인 리스트나 튜플의 첫 번째 원소를 초기값으로 결정하여 함수가 진행되게 된다. 이로 인해 오류가 발생할 수 있으므로, 초기값을 명시해주는 것이 훨씬 더 좋은 방법이다.
여기서는 defaultdict를 초기값으로 사용하였는데, defaultdict의 기본값을 []가 아닌 lambda: []로 설정하였다. 이는 defaultdict에는 기본값으로 callable이 가능한 것이 들어가야 하기 때문이다.
여기서, callable의 정의를 조사해보았는데, 다음과 같다.
- __call__ 메소드를 가지고 있는 클래스의 인스턴스
__call__ 메소드는 인스턴스를 호출 시 실행되는 메소드이다. a = ClassA()일 때, a(2, 3) 이런 식으로 호출할 때 __call__ 메소드에 2와 3이 인자로 들어가는 것이다.
조사 결과, lambda는 callable하다. 그러므로, defaultdict 안에 lambda: 리턴값 형태를 자주 사용하는 것이다.
iterable : list나 tuple 등 반복이 가능한 객체를 iterable하다고 한다. 내부적 구현으로 __iter__와 __next__가 사용된다. iter()라는 iterator(iterable 객체의 값을 차례로 꺼내게 해주는 객체)를 통해서, 값을 차례대로 꺼낼 수 있다.

그림과 같이 iter()를 사용하여 iterator를 만들면, Linked List의 형태처럼 값과 다음 값의 주소값을 가진 형태로 데이터 구조를 생각할 수 있다. 이때, iterator 객체는 주소값을 가지고 있고, next()를 통해 순회하게 되면 현재값을 출력해주고, 주소값은 다음 값의 주소값으로 바뀌게 된다. 이를 통해 순회할 수 있게 된다. 중요한 것은 iterable하다고 해서 반드시 iterator라는 것은 아니다. iterator로 만들려면 built-in function인 iter()를 사용해야 한다. 또한, 순회 가능한 마지막 원소에 도달 시, 다음 next()를 실행하면 StopIteration exception이 발생하게 된다.
generator : 간단하게 말하자면 iterator를 만드는 function이다. generator의 가장 큰 특징은 yield라는 키워드를 사용한다는 것인데, 다음과 같다.
- 함수 정의부분에서, yield가 사용된 순간, 그 함수는 일반적인 함수가 아닌 generator로 간주한다.
- yield를 만나는 순간, 그 함수는 그 상태에서 정지된다. 그리고 그 반환값을 next()를 호출한 쪽으로 전달하게 된다. 정지된 다는 것은, 그 함수 내의 지역 변수나 instruction pointer(program counter를 의미)를 그대로 유지하는 것을 의미한다.
- 좀더 편하게 generator를 생성하기 위한 generator expression이 있는데, ()를 사용한다.
예시는 다음과 같다.








위와 같이, yield를 만나면 그 상태에서 해당 함수는 정지되고, next()나 for문 등으로 호출 시 그 정지된 지점에서 재개된다. 또한, list 등의 sequence type을 generator에서 사용 시 for문으로 써도 되지만, Python 3.3부터는 yield from을 사용할 수 있다. 그리고 ()를 사용하여 간단하게 generator를 생성하는 것 또한 가능하다.
generator는 다음과 같은 경우에 사용하면 좋다.- list타입의 데이터를 반환해주는 함수에 좋다. 읽기가 쉽다는 장점이 있고, 중간 과정에서 loop가 중단될 수 있을 때 좋다.- 데이터가 커도 처리에 어려움이 없으므로, 큰 데이터 처리 시 generator expression(()를 사용하기)- 또한 파일 데이터 처리 시에도 generator를 사용하면 좋다.
가변인자(Variable-length) : 개수가 정해지지 않은 변수를 함수의 parameter로 사용하는 것으로, *(asterisk)를 사용하여 나타낸다. 입력된 값은 tuple 형태로 사용하며, 가변인자는 오직 한 개만 맨 마지막 parameter 위치에 사용 가능하다.

키워드 가변인자(Keyword variable-length) : parameter 이름을 따로 지정하지 않고 입력받는 방법으로, *(asterisk)를 2번 사용하여 나타낸다. 입력된 값은 dict type으로 처리되고, 가변인자는 오직 한 개만 기존 가변인자 다음에 사용 가능하다.
가변인자 및 키워드 가변인자는 다음과 같은 순서로 들어와야 한다.

한번 키워드로 받기 시작하면, 그 뒤에는 가변인자로 못받는 것을 주의하자.
*(asterisk) : asterisk는 다음과 같이 쓰인다.
- 곱셈
- 제곱 연산
- 가변 인자
- Unpacking
여기서 unpacking을 살펴보자. tuple, dict 등 자료형에 들어있는 값을 unpacking하는 것이며, 함수의 입력값이나 zip등에 유용히 사용 가능하다.


'Naver BoostCamp AI Tech 3기' 카테고리의 다른 글
| Sequence to Sequence Learning with Neural Networks (1) | 2022.02.03 |
|---|---|
| [Python] 4강 (0) | 2022.01.30 |
| [Python] 2강 (0) | 2022.01.27 |
| [Python] 1강 (0) | 2022.01.27 |
| 좀 늦어버린 티스토리 블로그 오픈! (2) | 2022.01.27 |