2022. 7. 6. 21:12ㆍNaver BoostCamp AI Tech 3기
ABSTRACT
BERT와 같은 Masked language modeling(MLM) pre-training 방법들은 input을 몇몇 [MASK] 토큰으로 교체함으로써 손상시키고, 모델이 원래 토큰을 만들어내도록 훈련시킨다. 비록 이 방법들이 downstream NLP task들로 전이시킬 때 좋은 결과를 창출하지만, 이 방법들이 효과적이기 위해서는 일반적으로 많은 계산량이 요구된다. 대안책으로, 연구팀에서는 더 sample-efficient한 pre-training task인 소위 “replaced token detection”을 제안한다. 이는 input을 masking하는 대신에, 몇몇 토큰들을 작은 generator network 내에서 샘플링 된 그럴 듯한 대체어로 교체한다. 철저한 실험을 통해서 이 새로운 pre-training task가 MLM보다 더 효과적이라는 것을 증명하였는데, 왜냐하면 이 task는 모든 input token들에 대해 정의되기 때문이다. (MLM은 masked된 작은 subset에 국한된다.) 결과적으로, 연구팀의 접근법을 통해 훈련 된 contextual representation들이 동일한 모델 사이즈, 데이터, 계산량의 조건에서 대체로 BERT의 방식으로 훈련된 것들을 성능에서 압도한다. 이 장점들은 특히 규모가 작은 모델들에게 주효한데, 예를 들어 연구팀에서는 모델을 GPU로 4일 동안 훈련시켰으며, 이 모델이 30배 더 큰 계산량으로 훈련 된 GPT의 성능을 GLUE natural language understanding benchmark에서 성능에서 압도하였다. 연구팀의 접근법은 또한 큰 규모에서도 잘 동작하는데, RoBERTa 및 XLNet의 4분의 1 이하의 계산량으로 경쟁 할만한 성능을 보였으며, 동일한 계산량의 경우에는 성능 면에서 압도하였다.
1 INTRODUCTION
현재 language에 대한 SOTA representation 학습법은 denoising autoencoder들을 학습하는 것(Vincent et al., 2008)으로 볼 수 있다. 이 학습법들은 unlabeled input sequence에서 대략 15% 정도의 작은 subset을 선택한 이후에, 이 토큰들을 mask하거나(BERT, Devlin et al., 2019), 이 토큰들에 attention을 취하여서(XLNet; Yang et al. (2019)), original input을 회복하도록 network를 훈련시킨다. 비록 bidirectional representation들을 학습하기 때문에 기존 language-model pre-training보다 더 효과적이지만, 이러한 MLM 접근법은 상당한 계산 cost를 초래한다. 왜냐하면 network는 오직 example 당 15%의 token들로부터만 학습하기 때문이다.
대안책으로, 연구팀에서는 “replaced token detection”이라는 pre-training task를 제안하며, 이 task에서는 모델이 “그럴 듯 하지만 인조적으로 생성된 토큰”들로부터 real input 토큰들을 구별해내도록 학습한다. Masking 대신에, 연구팀의 방법은 input의 몇몇 토큰을 proposal distribution(제안 분포, Rejection Sampling(기각 샘플링, 원하는 target 분포에서 직접 샘플링 하기 어려울 때 효율적으로 샘플링하기 위해 사용되는 방법)에서 쉽게 샘플을 생성할 수 있도록 임의로 설정한 분포를 의미한다. Uniform distribution, normal distribution 등이 이용될 수 있다.)으로부터 나온 샘플들로 교체하여 손상시키며, 여기서 proposal distribution은 전형적으로 small masked language model의 output이다. 이러한 손상 과정은 pre-training 시에는 인조적인 [MASK] 토큰을 볼 수 있지만, downstream task에서 fine-tuned 될 때에는 [MASK] 토큰을 볼 수 없는 BERT 내의 mismatch 문제를 해결하였다.(XLNet은 문제 없음) 그 후에는 network를 discriminator로써 훈련시키는데, 모든 토큰에 대해서 기존의 토큰인 지, 교체된 토큰인 지를 예측하도록 훈련된다. 이와는 대조적으로, MLM은 network를 손상된 토큰들이 원래 어떤 토큰이였는지를 예측하는 generator로써 훈련한다. 연구팀의 discriminative task의 주요 장점은 모델이 small masked-out subset에서 학습하는 대신에 모든 input token에 대해 학습한다는 것과, 이로써 계산량에서 더 효율적이라는 것이다. 비록 연구팀의 접근법이 GAN의 discriminator를 훈련시키는 것을 연상시키지만, 연구팀의 방법은 손상된 토큰을 만들어내는 generator가 GAN을 text에 적용시키는 것이 어렵다는 이유로(Caccia et al., 2018) maximum likelihood를 통해 훈련된다는 점에서 adversarial(적대적)하지 않다는 점이 있다.
연구팀은 이 방법을 “ELECTRA”(Efficiently Learning an Encoder that Classifies Token Replacements Accurately)라 이름 지었다. 이전의 연구에서와 같이, 연구팀은 이 방법을 통해 downstream task들에서 fine-tuned될 수 있는 Transformer의 text encoder들(Vaswani et al., 2017)을 pre-train시키는 데에 적용하였다. 일련의 ablation 실험들을 통해서, 연구팀은 모든 input position에서 학습을 하는 것이 ELECTRA가 BERT보다 훨씬 더 빨리 학습되도록 한다는 것을 보였다. 연구팀은 또한 ELECTRA가 완전히 훈련될 때에 downstream task들에서 더 높은 정확도를 얻음을 보였다.
대부분의 현재의 pre-training 방법들은 효과적인 성능을 위해선 거대한 양의 계산을 요구하며, 이는 cost 및 accessibility에 대한 우려를 높인다. 더 많은 계산량으로 pre-training하는 것이 거의 항상 더 좋은 downstream 정확도로 이어지기 때문에, 연구팀에서는 절대적인 downstream 성능 뿐만 아니라 계산 효율성도 pre-training 방법론의 중요한 고려사항으로 여겼다. 이 관점에서, 연구팀은 다양한 사이즈로 ELECTRA 모델들을 훈련시키고 그들의 계산량 대비 성능을 평가하였다. 특히, 연구팀에서는 GLUE natural language understanding benchmark(Wang et al., 2019)에서와 SQuAD question answering benchmark(Rajpurkar et al., 2016)에서 실험을 진행하였다. ELECTRA는 대체로 동일한 모델 사이즈, 데이터, 계산량이라는 조건 하에서 BERT 및 XLNet과 같은 MLM 기반의 방법들을 성능면에서 압도하였다. Figure 1을 보라.
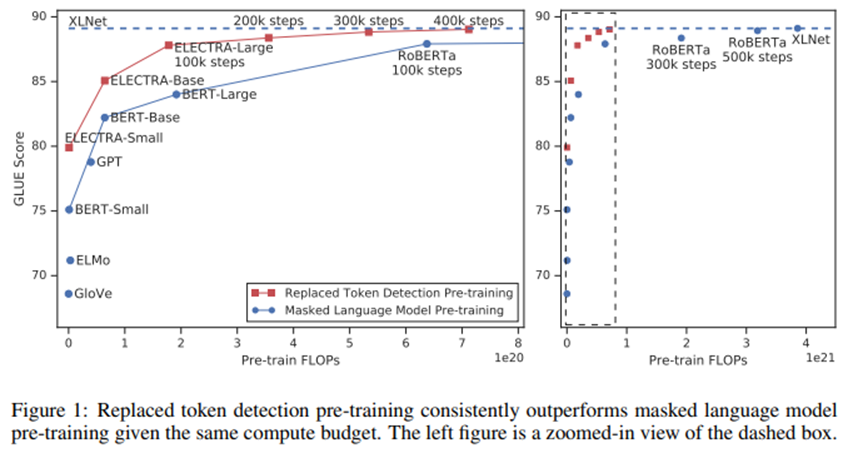
예를 들어, 연구팀은 4일 동안 1개의 GPU로 훈련 가능한 ELECTRA-Small 모델을 만들었다. ELECTRA-Small은 GLUE에서는 비교적 작은 small BERT 모델에 대해 5포인트 정도 앞서며, 심지어 훨씬 더 큰 GPT 모델(Radford et al., 2018)에게도 성능에서 앞선다. 연구팀의 접근법은 또한 대규모에서도 잘 작동하며, 여기서는 ELECTRA-Large를 훈련시켜서 RoBERTa(Liu et al., 2019) 및 XLNet(Yang et al., 2019)과 비교할 만한 성능이 나왔다. 그럼에도 불구하고, 훈련에 대한 계산량이 4분의 1이며 더 적은 파라미터를 가졌다. ELECTRA-Large를 훈련시키는 것은 결과적으로 GULE에서 ALBERT(Lan et al., 2019)의 성능을 압도하는 더욱 더 강력한 모델로 이어졌으며, SQuAD 2.0에서 새로운 SOTA를 달성하였다. 종합해보면, 연구팀의 결과는 challenging한 negative sample에서 real data를 구분하는 discriminative task가 기존의 language representation learning을 위한 generative 접근법들보다 더 compute-efficient하고 parameter-efficient하다는 것을 시사한다.
2 METHOD
연구팀은 우선 replaced token detection pre-training task에 대해 묘사할 것이다. Overview를 위해 Figure 2를 확인해보라. 이 방법에 대한 여러 modeling improvement들을 Section 3.2에서 제안하고 평가한다.

연구팀의 접근법은 2개의 neural network, generator 와 discriminator D를 훈련시키는 것이다. 각각의 network는 우선적으로 input token x = [x1, …, xn] sequence를 contextualized vector representation h(x) = [h1, …, hn]에 map하는 encoder(예를 들어, Transformer network)로 우선적으로 구성되어 있다. Position t가 주어졌을 때(연구팀의 경우 xt = [MASK]이다.), generator는 softmax layer와 함께 특정 토큰 xt를 generate하기 위해 확률을 output으로 낸다.

여기서 e는 token embedding을 의미한다. Position t가 주어졌을 때, discriminator는 토큰 xt가 “real”인지 아닌지를 예측한다. 다시 말해서 이 토큰이 데이터에서 온 건지, generator distribution에서 온 건지를 sigmoid output layer와 함께 예측한다.

Generator는 masked language modeling(MLM)을 수행하기 위해 훈련된다. Input x = [x1, x2, …, xn]이 주어졌을 때, MLM은 우선 정수 1~n 사이의 랜덤한 position의 set을 선택하여 mask하여 m = [m1, …, mk](여기서 k는 주로 토큰 전체의 15%이다.)를 만든다. 선택된 position에서의 토큰들은 [MASK] 토큰이 되고, 연구팀은 이를 x(masked) = REPLACE(x, m, [MASK])로 표기한다. Generator는 이후에 masked-out된 토큰들이 원래 어떤 토큰이였는지 예측하는 법을 학습한다. Discriminator는 generator sample로 교체된 토큰들이 있는 data 내에서 토큰들을 구별하도록 훈련된다. 더 구체적으로는, 연구팀은 masked-out된 토큰들을 generator sample들로 교체하여 x(corrupt)를 만들어내고, discriminator는 x(corrupt)내에서 어떤 토큰들이 original input x에 있던 토큰인지 예측하도록 훈련한다. 공식으로 표현하면, 모델의 input은 다음과 같이 생성된다.

그리고 loss function들은 다음과 같다.

비록 GAN의 training objective와 유사하지만, 몇몇 주요한 차이점이 존재한다. 먼저, generator가 만약에 우연히 올바른 토큰을 생성한다면, 그 토큰은 “fake”가 아닌 “real”로 여겨진다. 연구팀은 이 공식을 발견하여 downstream task들에서 성능을 적당하게 올릴 수 있었다. 더 중요한 것으로, generator는 discriminator를 속이기 위해 adversarially하게 훈련되는 것이 아닌 maximum likelihood로 훈련된다는 것이다. Generator를 adversarially하게 훈련하는 것은 어려운데, 왜냐하면 generator로부터 sampling 하는 것을 통해 backpropagate하는 것은 불가능하기 때문이다. 비록 연구팀에서는 이 문제를 우회하기 위해 generator 훈련에 강화학습을 사용해서 실험해보았지만(Appendix F 참조), 이는 오히려 maximum-likelihood 훈련보다 더 성능이 안좋았다. 마지막으로, generator에 input으로 noise vector를 사용하지 않았는데, 이는 GAN에서와 같다.
그래서 연구팀은 combined loss를 raw text의 거대한 코퍼스 χ를 통해 최소화하게 된다.

연구팀에서는 단일 샘플로 loss들에서 예측값들을 근사시킨다? 연구팀은 generator를 통해 discriminator loss를 backpropagate하지 않는다. (이는 sampling step으로 인해서이다.) pre-training 이후에는, generator를 제거하고 discriminator를 downstream task들에 대해 fine-tune한다.
3 EXPERIMENTS
3.1 EXPERIMENTAL SETUP
연구팀은 General Language Understanding Evaluation(GLUE) benchmark(Wang et al., 2019)과 Stanford Question Answering(SQuAD)(Rajpurkar et al., 2016) 데이터셋으로 평가한다. GLUE는 textual entailment(두 문장이 주어졌을 때, 첫 번째 문장이 두 번째 문장을 수반하는가 혹은 위배하는가?)(RTE, MNLI), question-answer entailment(두 번째 문장이 첫 번째 문장 내의 질문에 대한 대답을 포함하고 있는가?)(QNLI), paraphrase(두 번째 문장은 첫 번째 문장의 paraphrase(의역)인가?)(MRPC), question paraphrase(두 개의 질문은 서로 유사한가?)(QQP), textual similarity(두 개의 문장은 얼마나 유사한가?)(STS), sentiment(감성 분석)(SST), linguistic acceptability(해당 문장은 문법적으로 오류가 있는가?)(CoLA)를 cover하는 다양한 task들을 포함한다. GLUE task에 대해서는 Appendix C에 자세히 나와있다. 연구팀의 평가 metric들은 STS는 Spearman correlation, CoLA는 Matthews correlation, 그 외의 다른 GLUE task들은 정확도를 기준으로 한다. 연구팀은 모든 task에 대해 전반적인 평균 score를 보고한다. SQuAD에 대해서는, SQuAD v1.1과 2.0에 대해 평가하며, 1.1에서는 모델이 question에 답변할 text의 span을 선택하고, 2.0에서는 몇몇 passage로는 대답이 불가능한 질문들이 존재한다. 연구팀은 표준적인 평가 metric인 Exact Match(EM)과 F1 score를 사용한다. 대부분의 실험에서 연구팀은 BERT에서와 같은 data를 pre-train하며, 이는 Wikipedia 및 BooksCorpus(Zhu et al., 2015)로부터 33억개의 토큰으로 이루어져 있다. 그러나, 연구팀의 거대 모델에 대해서는 XLNet(Yang et al., 2019)에서 사용된 데이터로 pre-train하였다. 이는 BERT 데이터셋을 ClueWeb(Callan et al., 2009), CommonCrawl, Gigaword(Parker et al., 2011)로부터 모아진 330억개의 토큰들로 확장한 것이다. 모든 pre-training 및 평가는 영어 data에 기반하며, 미래에 multilingual data에 적용해보면 흥미로울 것이라 생각한다.
연구팀의 모델 아키텍처와 대부분의 하이퍼파라미터들은 BERT와 같다. GLUE에서의 fine-tuning을 위해서, 연구팀은 ELECTRA의 맨 윗단에 단순한 linear classifier들을 추가한다. SQuAD에 대해서는, ELECTRA의 맨 윗단에 XLNet의 question-answering module을 추가하며, 이는 BERT의 classifier보다 조금 더 정교한데, 이는 start 및 end position들을 독립적으로 예측하기 보다는 결합하여 예측한다는 점에서 그러하며, SQuAD 2.0에 대해서는 “answerability”에 대한 classifier가 추가되었다. 평가 데이터셋 중 몇몇은 작은데, 이는 fine-tuned model들의 정확도가 랜덤 시드에 의존하여 매우 다양할 수 있다는 것을 의미한다. 그러므로 각 결과는 같은 pre-trained checkpoint에서 10번의 fine-tuning 진행 결과의 중간값을 보고한다. 이렇게 명시되지 않은 것들은, dev set에 대한 결과들이다. 더 자세한 training detail 및 hyperparameter 값들에 대해서는 appendix를 참조하라.
3.2 MODEL EXTENSIONS
연구팀은 모델에 대한 여러 확장법들을 제안하고 평가함으로써 개선시켰다. 특별히 명시되어 있지 않다면, 이 실험들은 BERT-Base와 동일한 모델 사이즈 및 훈련 데이터를 사용한다.
Weight Sharing
연구팀은 generator 및 discriminator 간의 weight들을 공유함으로써 pre-training의 효율성을 개선시키는 것을 제안하였다. 만약 generator와 discriminator가 동일한 사이즈라면, 모든 transformer weight들은 묶일 수 있다. 그러나, 연구팀은 small generator를 갖는 것이 더 효율적이라는 것을 발견하였는데, 이 경우에는 generator와 discriminator 간에는 오직 token embedding 및 positional embedding들만 공유한다. 이 경우에는 연구팀은 embedding으로 discriminator의 hidden state의 크기를 사용한다. Generator의 “input”과 “output” token embedding들은 BERT와 같이 항상 묶인다.
연구팀은 generator가 discriminator에서와 같은 크기일 때 weight tying 전략들을 비교했다. 연구팀은 이 모델들을 500k step 동안 훈련시켰다. GLUE 스코어들은 weight tying이 없으면 83.6이며, token embedding들에 대해 tying 시 84.3, 그리고 모든 weight들을 tying 시 84.4를 달성하였다. 연구팀은 ELECTRA가 masked language modeling이 이 representation들을 학습하는 데에 특히 효과적이기 때문에 token embedding을 tying하는 것에서 이점을 얻는다고 가정하였다. (tying을 하지 않는 MLM에서) Discriminator는 오직 input에 존재하거나 generator에 의해 샘플링 된 토큰들만 update하는 반면에, generator의 vocabulary에 대한 softmax는 densely하게 모든 token embedding들을 update한다. 반면에, 모든 encoder의 weight들을 tying하는 것은 성능 개선이 거의 일어나지 않았지만, generator와 discriminator가 동일한 사이즈가 되야 한다는 엄청난 단점을 발생시켰다. 이러한 발견에 기초하여, 이번 논문에서 앞으로의 실험들에서는 tied embedding만을 사용할 것이다.
Smaller Generators
만약 generator와 discriminator가 동일한 사이즈라면, ELECTRA를 훈련시키기 위해서는 오직 masked language modeling으로 훈련시킬 때보다 2배 정도의 계산을 해야할 것이다. 연구팀은 이러한 요인을 줄이기 위해 더 작은 generator를 사용할 것을 제안한다. 구체적으로, 연구팀은 다른 하이퍼파라미터들은 유지하면서 layer size들만 줄여 모델을 작게 만든다. 또한 극단적으로 단순한 “unigram” generator(훈련 코퍼스 내에서 토큰의 빈도에 따라 fake 토큰들을 샘플링한다.)를 사용할 것을 연구하였다. 각기 다른 크기이 generator 및 discriminator들의 GLUE 스코어는 Figure 3의 왼쪽에 나타나있다.

모든 모델들은 500k step 동안 훈련되며, 이는 더 작은 generator들이 training step 당 계산량을 덜 요구하기 때문에 계산량 측면에서 불리하다. 그럼에도 불구하고, 연구팀에서는 모델들이 discriminator의 사이즈의 1/4-1/2의 사이즈의 generator들인 경우에 가장 잘 동작함을 발견하였다. 연구팀에서는 generator를 너무 강하게 가져가는 것이 discriminator에게 있어서 discriminator가 학습을 효과적으로 하는 것을 막는, too-challenging한 task를 제기하는 것이 아니냐는 추측을 하였다. 특히, discriminator는 실제 data distribution보다는 generator를 모델링하는 데에 많은 파라미터를 사용해야만 할 것이다. 이 논문에서 뒤에 나오는 실험들에서는 주어진 discriminator 사이즈에 맞는 가장 좋은 generator 사이즈를 사용할 것이다.
Training Algorithms
마지막으로, 연구팀에서는 비록 성능 향상으로 이어지지는 못했지만, ELECTRA를 위한 다른 training 알고리즘들을 연구해볼 것이다. 제안된 training objective들은 generator와 discriminator를 결합하여 훈련한다. 연구팀은 다음의 two-stage 훈련 과정을 통해 실험한다.
1. 오직 Loss(MLM)으로 n step 동안 generator만 훈련시킨다.
2. Discriminator의 weight를 generator의 weight로 초기화한다. 그 후에 generator의 weight들은 frozen한 채 n step 동안 Loss(Disc)으로 discriminator를 훈련시킨다.
명심할 점은 이 과정에서는 generator와 discriminator가 동일한 사이즈를 가져야 한다는 것이다. 연구팀은 discriminator의 weight initialization 없이는 generator가 discriminator보다 훨씬 먼저 시작했기 때문에, discriminator가 가끔 과반수 이상을 전혀 학습하지 못한다는 것을 발견하였다. 반면에 결합하여 훈련하는 것은 generator가 약하게 시작하지만, 훈련을 통해 점점 나아지는 curriculum을 자연스럽게 discriminator에게 제시한다. 연구팀은 또한 GAN에서와 같이 generator를 adversarially하게 훈련하는 것을 발견하였고, 이는 generator로부터 sampling의 discrete operation들을 수용하기 위해 강화학습을 사용한다. 자세한 사항은 Appendix F를 보라.
결과는 Figure 3의 오른쪽에 나타나있다. Two-stage training 동안에, downstream task 성능은 generative에서 discriminative objective로 변경한 이후에 특히 향상되었지만, joint training을 압도하지는 못했다. 여전히 BERT를 앞서긴 하지만, 연구팀은 adversarial training이 maximum-likelihood training보다는 떨어진다는 것을 발견하였다. 그 이상의 분석에서는 이 gap이 adversarial training에서의 2가지 문제점으로 인해 발생한다고 제시한다. 첫 번째로, adversarial generator는 단순히 masked language modeling에서는 더 성능이 안 좋다. 이는 masked language modeling에서 58%의 정확도를 달성한 반면, Maximum Likelihood Estimation으로 훈련된 generator는 65%의 정확도를 달성하였다. 연구팀은 이 더 나쁜 정확도가 generating text의 거대한 action space에서 동작 시 강화학습의 poor sample efficiency가 주 원인이라 믿는다. 두 번째로, adversarially하게 훈련 된 generator는 low-entropy output distribution을 만드는데, 이 분포에서 대부분의 확률질량이 1개의 토큰에 몰려있으며, 이는 generator의 sample에 다양성이 거의 없다는 것을 의미한다. 이 2가지 문제는 이전 연구에서 text에 대한 GAN에서 관찰된 것들이다.(Caccia et al., 2018)
3.3 SMALL MODELS
이번 연구의 목표는 pre-training의 효율성을 개선시키는 것이기에, 연구팀에서는 단일 GPU로 빠르게 훈련이 가능한 작은 모델을 개발하였다. BERT-Base의 하이퍼파라미터들로 시작하여서, 연구팀은 sequence length를 512에서 128로 줄이고, batch size를 256에서 128로 줄이고, 모델의 hidden dimension size를 768에서 256으로 줄이고, token embedding은 768에서 128로 줄였다. 공정한 비교를 위해서, 연구팀은 또한 동일한 하이퍼파라미터들을 사용하여 BERT-Small 모델을 훈련하였다. BERT-Small을 1.5M step 동안 훈련하여서, ELECTRA-Small과 동일한 training FLOPs(Floating point Operations Per Second, 컴퓨터가 1초 동안 수행할 수 있는 부동소수점 연산의 횟수)를 사용하며, 이때에 ELECTRA-Small은 1M step 동안 훈련되었다. BERT에다가, 연구팀은 language modeling 기반의 resource를 덜 잡아먹는 2가지 방법인 ELMo(Peters et al., 2018)과 GPT(Radford et al., 2018)에 대해 비교한다. 또한 BERT-Base와 비슷한 base-sized ELECTRA 모델의 결과를 나타낸다.
결과는 Table 1에 나타나있다.

추가적인 결과는 Appendix D에 나타나 있으며, 더 많은 계산량으로 훈련된 더 강력한 small-sized 및 base-sized 모델들을 포함한다. ELECTRA-Small은 주어진 사이즈에서 현저하게 잘 동작하며, 더 많은 계산량 및 파라미터들을 사용하는 다른 방법들보다 더 높은 GLUE 스코어를 달성하였다. 예를 들어, 비슷한 BERT-Small 모델보다 5 포인트 높은 점수를 달성하였으며, 심지어 이보다 훨씬 더 큰 GPT 모델의 성능을 압도하였다. ELECTRA-Small은 훈련을 통해 대부분 수렴하였고, 여전히 합리적인 성능을 달성한 채 모델 훈련 시간이 더 적었다. (6시간 정도) 더 거대한 pre-trained transformer들로부터 distilled 된 작은 모델들이 또한 좋은 GLUE 스코어를 달성할 수 있지만, 이 모델들은 처음에 더 거대한 teacher model을 pre-train하기 위한 상당한 계산량을 요구한다. 이 결과들은 또한 적정한 사이즈에서 ELECTRA의 강력함을 증명한다. Base-sized ELECTRA 모델은 대체로 BERT-Base의 성능을 압도하며 심지어 84.0 GLUE 스코어를 달성한 BERT-Large의 성능마저 압도한다. 연구팀은 비교적 더 적은 계산량으로 좋은 결과를 달성한 ELECTRA의 능력이 NLP의 pre-trained 모델들을 개발하고 적용하는 데의 accessibility를 넓힐 것이라고 희망한다.
3.4 LARGE MODELS
연구팀은 현재 SOTA인 대규모 pre-trained Transformers에서 replaced token detection pretraining task의 효과를 측정하기 위해서 거대한 ELECTRA 모델들을 훈련시켰다. 연구팀의 ELECTRA-Large 모델들은 BERT-Large와 동일한 사이즈이지만 훨씬 더 오랫동안 훈련된다. 특히, 연구팀은 모델을 하나는 400k step 동안 훈련시키며(ELECTRA-400K; RoBERTa의 pre-training 계산량의 대략 1/4), 다른 하나는 1.75M step 동안 훈련시킨다.(ELECTRA-1.75M; RoBERTa와 계산량이 비슷하다.) 연구팀은 batch size로 2048을 사용하고 XLNet pre-training data를 사용한다. 주목할 점은 XLNet data는 RoBERTa 훈련 시 사용된 data와 비슷하지만, 비교가 완전하게 direct하지는 않다는 것이다. baseline으로써, ELECTRA-400K와 동일한 훈련 시간 및 하이퍼파라미터들을 사용하여 연구팀만의 BERT-Large 모델을 훈련시켰다.
GLUE dev set에서의 결과가 Table 2에 나타나있다.
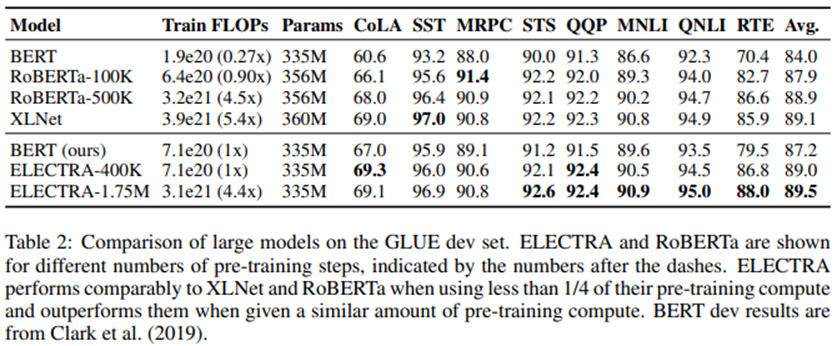
ELECTRA-400K는 RoBERTa 및 XLNet과 비슷한 성능을 수행한다. 그러나, ELECTRA-400K는 RoBERTa 및 XLNet 훈련 시보다 1/4 이하의 계산량이 소모되었고, 이는 ELECTRA의 대규모에서의 sample-efficiency 이점을 증명하는 것이다. ELECTRA를 더 오랫 동안 훈련하는 것(ELECTRA-1.75M)은 대부분의 GLUE task에서 다른 모델들을 앞서는 결과로 이어졌다. 반면에 여전히 pre-training 계산량은 더 적었다. 놀랍게도, 연구팀의 baseline BERT 모델의 스코어는 RoBERTa-100K보다 낮았으며, 이는 연구팀의 모델들이 더 많은 하이퍼파라미터 tuning 또는 RoBERTa 훈련 data를 사용한 것으로 인한 이점이라는 것을 제시한다. 비록 모델을 위해 사용된 추가적인 trick들로 인해 이런 비교들이 같은 조건하의 비교라고 하기엔 부족하지만(Appendix B를 보라.), ELECTRA의 이점은 GLUE test set에서도 계속된다.(Table 3을 보라.)

SQuAD에 대한 결과는 Table 4에 나타나있다.

GLUE에서의 결과와 일치하게, ELECTRA 스코어들이 동일한 계산 리소스들이 주어진 masked-language-modeling 기반 방법들보다 더 좋았다. 예를 들어, ELECTRA-400K는 RoBERTa-100k 및 BERT baseline의 성능을 앞섰고, 비슷한 양의 pre-training 계산량을 사용한다. ELECTRA-400K는 또한 RoBERTa-500K와 성능이 비슷한 반면, 계산량은 1/4 이하로 사용한다. 놀랍지 않게도, ELECTRA를 더 오래 훈련시키는 것이 결과를 더욱 개선시켰다. ELECTRA-1.75M은 이전 모델들보다 SQuAD 2.0 benchmark에서 더 높은 점수를 기록한다. ELECTRA-Base 또한 좋은 결과를 내놓으며, 대체로 BERT-Base 및 XLNet-Base보다 더 좋은 점수를 기록하며, 심지어 대부분의 metric들에서 BERT-Large도 앞선다. ELECTRA는 일반적으로 SQuAD 1.1보다는 SQuAD 2.0에서 더 잘 동작한다. 아마 모델이 그럴 듯한 “fake”들에서 “real” 토큰들을 구별해내는 “replaced token detection”이 특히 SQuAD 2.0의 answerability classification(모델이 fake unanswerable question들로부터 answerable question들을 구별해내야만 한다.)에 전이가 잘 되기 때문일 것이다.
3.5 EFFICIENCY ANALYSIS
연구팀은 training objective를 토큰들의 작은 subset에 두는 것이 masked language modeling을 비효율적으로 만든다고 제시하였다. 그러나, 이것이 사실인 것이 완전히 분명한 것은 아니다. 전반적으로, 모델은 오직 적은 숫자의 masked 토큰들을 예측하지만, 많은 숫자의 input 토큰들을 여전히 받는다. ELECTRA이 이점이 어디서 오는지 더 잘 이해하기 위해서, 연구팀은 BERT와 ELECTRA 사이의 디딤돌(stepping stones)들의 집합으로 디자인 된 다른 pre-training objective들을 비교한다.
ELECTRA 15%
이 모델은 ELECTRA와 동일한데, 차이점은 discriminator loss가 오직 input에서 masked out된 15%의 토큰에서만 온다는 것이다. 다시 말해서, discriminator loss인 L(Disc)에서의 합은 1에서 n이 아닌 i ∈ m에 대해 이루어진다.
Replace MLM
이 objective는 masked language modeling과 동일한데, 차이점은 [MASK] 토큰으로 교체하는 대신, generator 모델에서 나온 토큰들로 교체된다. 이 objective는 pre-training 시에는 모델에 [MASK] 토큰을 노출하지만, fine-tuning 시에는 노출하지 않는 불일치를 해결함으로써 ELECTRA의 이점이 어느 정도인지 테스트한다.
All-Tokens MLM
Replace MLM에서와 비슷하게, masked 토큰들은 generator sample들로 교체된다. 게다가, 이 모델은 masked out된 토큰들 만이 아니라, input 내의 모든 토큰들이 원래 어떤 토큰인지 예측한다. 연구팀은 이것이 각 토큰에 대한 복사 확률 D를 sigmoid layer를 사용하여 출력하는 명시적인 copy mechanism으로 이 모델을 훈련시키는 것이 결과를 개선시켰다는 것을 발견하였다. 이 모델의 output distribution은 input 토큰들에 대해 D weight를 부여하고 MLM softmax output의 (1 - D)배이다. 이 모델은 필수적으로 BERT 및 ELECTRA의 combination이다. 주목해야 하는 것은 generator replacement 없이는, 모델은 trivially하게 [MASK] 토큰에 대해서는 vocabulary에서 예측을 내고, 그 외의 토큰에 대해서는 input을 복사하도록 학습한다는 것이다.
결과는 Table 5에 나타나있다.

먼저, 연구팀은 ELECTRA가 단순히 subset에서보다 모든 input 토큰들에 대해 loss가 정의될 때 훨씬 더 이점이 있다는 것을 발견하였다. ELECTRA 15%가 ELECTRA보다 훨씬 성능이 낮게 동작했다. 두 번째로는, BERT의 성능이 pre-train 및 fine-tune 사이의 [MASK] 토큰들의 mismatch로 인해 약간 성능에 손해를 본다는 것으로, Replace MLM이 BERT의 성능을 소폭 앞선다. 연구팀에서는 BERT는 이미 pre-train 및 fine-tune 사이의 불일치에 대해 도움이 될 trick을 이미 포함하고 있다고 주목했다. Masked 토큰들은 10%는 랜덤 토큰으로 교체되며 10%는 동일하게 유지되기 때문이다. 그러나, 연구팀의 결과는 이 단순한 휴리스틱들은 이 문제를 완전히 해결하기에 충분치 않다고 제시한다. 마지막으로, subset 대신 전체 토큰에 대해 prediction을 만드는 All-Tokens MLM은 BERT 및 ELECTRA 사이의 대부분의 격차를 줄인다는 것을 발견하였다. 종합적으로, 이 결과들은 ELECTRA의 성능 개선의 많은 부분은 모든 토큰으로부터 학습하는 것에 기인할 수 있고, 더 적은 부분으로는 pre-train 및 fine-tune 사이의 mismatch를 완화하는 것에 기인할 수 있다는 것을 제시한다.
All-Tokens MLM에서 보는 ELECTRA의 성능 개선은 ELECTRA의 이점이 단순히 더 빠른 훈련 그 이상에서 온다는 것을 제시한다. 연구팀은 이를 BERT와 ELECTRA 모델을 다양한 모델 사이즈에서 비교함으로써 더 연구하였다. (Figure 4의 왼쪽을 보라.)

ELECTRA의 이점은 모델이 작아질수록 더 커진다는 것을 발견하였다. 작은 모델들은 훈련을 통해 완전히 수렴하며(Figure 4의 오른쪽을 보라.), ELECTRA가 BERT가 완전히 훈련되었을 때보다 더 높은 downstream 정확도를 달성한다는 것을 보여준다. 연구팀은 ELECTRA가 BERT보다 더 parameter-efficient하다고 추측하는데, 왜냐하면 각 position에서 가능한 토큰들의 full distribution을 모델링 할 필요가 없기 때문이다. 그러나, ELECTRA의 parameter efficiency를 완전히 설명하기 위해서는 더 많은 분석이 필요하다고 믿는다.
4 RELATED WORK
Self-Supervised Pre-training for NLP
Self-supervised learning은 word representations(Collobert et al., 2011; Pennington et al., 2014) 및 더 최근에는 language modeling과 같은 objective를 통해 contextual representations를 학습하는 데(Dai & Le, 2015; Peters et al., 2018; Howard & Ruder, 2018)에 사용되어 왔다. BERT(Devlin et al., 2019)는 거대한 Transformer(Vaswani et al., 2017)를 masked-language modeling task를 통해 pre-train 시킨다. BERT에 대해 수많은 확장들이 있었다. 예를 들어, MASS(Song et al., 2019)와 UniLM(Dong et al., 2019)은 BERT를 generation task들로 확장시켰는데, auto-regressive generative training objective를 추가시켰다. ERNIE(Sun et al., 2019a) 및 SpanBERT(Joshi et al., 2019)는 개선된 span representations를 위해 토큰의 contiguous sequence들을 mask out한다. 이 아이디어는 아마 ELECTRA에 보완적인데, 연구팀은 ELECTRA의 generator auto-regressive task와 “replaced span detection” task를 만들어보면 흥미로울 것이라 생각한다. Input token들을 mask out하는 대신에, XLNet(Yang et al., 2019)은 input sequence가 임의의 순서로 auto-regressively하게 생성되도록 attention weights를 mask한다. 그러나, 이 방법은 BERT와 같은 비효율성으로 고통받는데, 왜냐하면 XLNet은 이 방법으로 오직 15%의 input token만 생성하기 때문이다. ELECTRA처럼, 비록 XLNet은 pre-training 동안에는 2개의 attention “streams”를 사용하고 fine-tuning시에는 1개의 “stream”을 사용하기에 완전히 명확하지는 않지만, XLNet은 [MASK] 토큰을 요구하지 않음으로써 BERT의 pretrain-finetune 불일치를 완화할 것이다. 최근에는, TinyBERT(Jiao et al., 2019)와 MobileBERT(Sun et al., 2019b)와 같은 모델들은 BERT가 더 작은 모델로 효과적으로 distilled될 수 있음을 보여준다. 이와 대조적으로, 연구팀은 inference speed보다는 pre-training speed에 더 초점을 두었고, 그래서 scratch로부터 ELECTRA-Small을 훈련시킨다.
Generative Adversarial Networks
GANs(Goodfellow et al., 2014)는 high-quality의 인조적인 data를 생성하는 데에 효과적이다. Radford et al.(2016)은 downstream task들에서 GAN의 discriminator를 사용할 것을 제안하며, 이는 연구팀의 방법과 유사하다. GANs는 text data에 적용되어 왔는데,(Yu et al., 2017; Zhang et al., 2017) 비록 SOTA 접근법들이 여전히 standard한 maximum-likelihood training에 뒤쳐지고는 있다.(Caccia et al., 2018; Tevet et al., 2018) 비록 연구팀에서는 adversarial learning을 사용하지는 않지만, 연구팀의 generator는 특히 MaskGAN(Fedus et al., 2018)를 연상시키며, 여기서는 generator가 input에서 제거된 토큰들을 채우도록 훈련한다.
Contrastive Learning
넓게 보면, contrastive learning(대상들의 차이를 좀 더 명확하게 보여줄 수 있도록 학습한다.) 방법들은 가짜 negative sample들에서 나온 관측된 data point들을 구별한다. 이들은 text(Smith & Eisner, 2005), images(Chopra et al., 2005), video(Wang & upta, 2015; Sermanet et al., 2017) data를 포함한 많은 modalities에 적용되어 왔다. 대중적인 접근법은 관련된 data point들이 비슷한 embedding space들을 학습하거나(Saunshi et al., 2019) 또는 negative sample들에서 real data point들을 rank하는 모델들을 학습하는 것이다.(Collobert et al., 201;; Bordes et al., 2013) ELECTRA는 특히 Noise-Contrastive Estimation(NCE)(Gutmann & Hyvarinen, 2010)과 관련되어 있으며, 이는 또한 real data point와 fake data point들을 구별하는 binary classifier를 훈련시킨다.
NLP의 가장 초창기 pre-training 방법들 중 하나인 Word2Vec(Mikolov et al., 2013)은 contrastive learning을 사용한다. 사실, ELECTRA는 Negative Sampling을 사용하는 Continuous Bag-of-Words(CBOW)의 규모를 매우 크게 한 것으로 볼 수 있다. CBOW는 또한 주위 context가 주어졌을 때 input token을 예측하고 negative sampling은 learning task를 input token이 data에서 왔는지 proposal distribution에서 왔는지를 구분하는 binary classification으로 바꿔 말할 수 있다. 그러나, CBOW는 transformer보다는 bag-of-vectors encoder를 사용하며, 학습된 generator 대신에 unigram token frequencies에서 비롯된 단순한 proposal distribution을 사용한다.
5 CONCLUSION
연구팀은 “replaced token detection”이라는 language representation learning을 위한 새로운 self-supervised task를 제안하였다. 핵심 아이디어는 small generator network를 통해 만들어진 high-quality의 negative sample들로부터 input token을 구별하는 text encoder를 훈련시키는 것이다. Masked language modeling과 비교하여, 연구팀의 pre-training objective는 더 compute-efficient하고 결과적으로 downstream task에서 더 좋은 성능으로 이어졌다. 이 모델은 비교적 적은 양의 compute를 사용 시에 잘 동작하며, 이는 computing resources에 대해 접근성이 덜한 연구자 및 실무자들에게 pre-trained text encoder들을 개발하고 적용시키는 데에 대한 더 높은 접근성을 제공하리라 희망한다. 또한 NLP pre-training에 대한 더 많은 미래 연구에서 절대적인 성능과 더불어 efficiency 또한 고려하기를 희망하고, compute usage, evaluation metrics 및 parameter count에 대해 우리와 같이 작성하는 노력을 따라 주기를 희망한다.
'Naver BoostCamp AI Tech 3기' 카테고리의 다른 글
| Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering (0) | 2022.06.21 |
|---|---|
| User Guide for KOTE: Korean Online Comments Emotions Dataset (0) | 2022.05.26 |
| Dense Passage Retrieval for Open-Domain Question Answering (0) | 2022.04.28 |
| [MRC] 03. Generation-based MRC (0) | 2022.04.27 |
| [MRC] 02. Extraction-based MRC (0) | 2022.04.26 |