2022. 6. 21. 16:59ㆍNaver BoostCamp AI Tech 3기
Abstract
Open domain question answering을 위한 generative model들은 external knowledge에 의지하지 않는 채로 경쟁력이 있음을 증명해 왔다. 비록 이러한 접근법이 유망한 방법이지만, 파라미터가 수십억 개에 달하는 모델을 요구하는 방법이며, 이는 train 및 query를 하는 데에 비용이 많이 들게 된다. 이번 논문에서는, 연구팀에서 이러한 모델들이 얼마나 많이 text passage(잠재적으로 정답을 포함하고 있는)들을 retrieving 하는 데에 이점이 있는 지를 조사한다. 연구팀은 Natural Questions and TriviaQA open benchmark들에서 SOTA를 달성하였다. 흥미롭게도, 연구팀은 이 방법을 사용한 성능이 retrieved된 passage들의 숫자를 증가시킬 때 성능이 매우 상승한다는 것을 관찰하였다. 이는 sequence-to-sequence model들이 여러 개의 passage들로부터 정답을 효율적으로 모으고 결합하는 유연한 framework를 제공한다는 증거이다.
1 Introduction
최근에, 여러 연구들에서, 사실을 담은 정보는 매우 엄청난 양의 데이터로 훈련된 언어 모델들로부터 추출될 수 있음을 보여왔다. 이러한 관찰과 자연어 처리 모델의 pre-training의 발전을 바탕으로 하여, Roberts et al. (2020)은 open domain question answering을 위한 generative model을 도입하였다. External knowledge에 의지하지 않은 채로, 이 방법은 여러 benchmark들에서 경쟁력 있는 결과를 얻어냈다. 그러나, 이 방법은 파라미터가 수십억 개에 달하는 모델을 요구하며, 이는 왜냐하면 모든 정보가 weight 내에 저장되어야 할 필요성 때문이다. 이는 모델들에 query 및 train에 드는 비용을 크게 한다. 이번 논문에서는, 연구팀에서 이 방법이 Wikipedia와 같은 external source of knowledge에 접근하는 데에 있어서 얼마나 많이 이점이 있는 지를 조사한다.
이전에는 open domain question answering의 관점에서 extractive model들과 함께 retrieval 기반의 접근법들이 고려되었다. 이 경우에는, support document들을 retrieving 함으로써 시스템이 시작되며, 이는 answer를 이 document들로부터 extracting하기 전에 진행된다. 다른 retrieval 기술들이 고려되어 왔는데, TF/IDF 기반의 sparse representation을 사용하거나 또는 dense embedding을 사용하는 것이다. 정답을 extract 하는 모델들은 ELMo 또는 BERT와 같은 contextualized word representation 기반이며, answer를 span으로써 예측한다. 여러 passage에서 정답을 합치고 결합하는 것은 extractive model들을 사용할 때에는 직관적이지 못하며, 이 한계를 다루기 위해 여러 기술들이 제안되어 왔다.
이번 논문에서는, 연구팀에서는 open domain question answering을 위한 generative modeling 및 retrieval에서의 흥미로운 발전을 바탕으로, 2개의 world에서의 장점들을 모두 가지는 간단한 접근법을 소개한다. 이 방법은 2개의 단계로 진행된다. 1단계는 sparse 또는 dense representation을 사용하여 supporting passage들을 retrieving하는 것이다. 그리고 2단계는 sequence-to-sequence model이 answer를 생성해내며, 이때 input으로는 question + retrieved passage들을 받게 된다. 개념적으로는 간단하지만, 이 방법은 TriviaQA와 NaturalQuestions benchmark들에서 새로운 SOTA를 달성하였다. 특히, 연구팀에서는 이 방법의 성능이 retrieved되는 passage들의 숫자가 증가하면 매우 크게 향상된다는 것을 보인다. 연구팀에서는 이것이 extractive model들과 비교하여서, generative model들이 여러 passage에서 정답을 결합하는 것을 잘한다는 증거라고 생각한다.
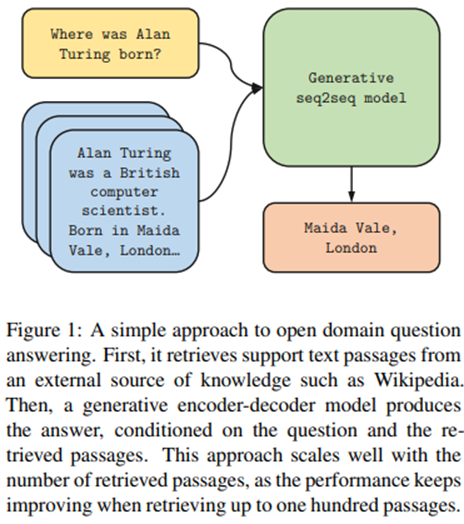
2 Related work
Open domain question answering은 general domain의 question들에 대답하는 task로, 여기서 정답은 system의 input으로 주어지지 않는다. 이 task는 NLP에서 오랫동안 남아있는 문제였으며, 최근에 다시 주목을 받기 시작하였다. Chen et al. (2017)에서는, answer에 대응하는 span의 형태로 강력한 supervision을 learning system에 이용하였다. Chen et al. (2017)에서는 처음에 Wikipedia로부터 support document를 retrieving한 이후에 그 document로부터 answer를 extracting하는 방식으로 문제를 해결하였다. 시스템에 gold span이 주어지지 않고 answer만 주어지는 환경을 해결하기 위한 다른 방법들이 제안되었다. Clark and Gardner(2018)에서는 answer에 대응하는 모든 span에 대한 global normalization을 사용하는 방법을 제안하였고, 후에는 BERT 기반 모델들에 적용되었다. Min et al. (2019a)에서는 이 환경에서 noisy supervision을 해결하기 위해 hard expectation-maximization 기반의 방법을 소개하였다. Wang et al. (2018b)에서는 다른 paragraph들에서 answer들을 합치기 위한 기술을 묘사하였는데, confidence와 coverage score를 사용한다.
Passage retrieval은 open domain question answering에서 중요한 단계이며, QA system을 향상시키기 위한 활발한 연구가 이루어지는 분야이다. 초기에는, TF/IDF 기반의 sparse representation들이 support document들을 retrieve하기 위해 사용되었다(Chen et al., 2017). Lee et al. (2018)에서는 BiLSTM 기반의 paragraph들을 rerank하는 supervised learning 방법들을 소개하였으며, Wang et al. (2018a)에서는 강화학습을 통해 ranking system을 훈련하였다. QA system에서 retrieval step을 향상시키는 2번째 접근법은 Wikipedia 도는 Wikidata graphs와 같은 추가적인 정보를 사용하는 것이다. 최근에는, 여러 연구들에서 전적으로 dense representation과 approximate nearest neighbors에 기반한 retrieval system들이 기존의 접근법들과 경쟁할 만하다는 것을 보였다. 이러한 모델들은 question-answer pair의 형태로 weak supervision을 통해 훈련될 수 있거나(Karpukhin et al., 2020), 또는 cloze task를 통해 pretrained되고 end-to-end로 finetuned될 수 있다. (Guu et al., 2020; Lee et al. 2019)
Generative question answering은 NarrativeQA, CoQA, ELI5와 같은 answer들을 generate할 것을 요구하는 dataset들의 이전 연구들에서 가장 많이 고려되었던 방법이다. 이 dataset들은 support document 내에 일치하는 span이 없도록 answer가 생성되었으므로, 결과적으로 abstractive model을 요구하게 된다. Raffel et al. (2019)에서는 generative model들이 정답이 span으로 존재하는 SQuAD와 같은 reading comprehension task들과 경쟁력이 있음을 보였다. Roberts et al. (2020)에서는, open domain question answering을 위한 additional knowledge 없이 거대한 pretrained generative model들을 사용할 것을 제안하였다. 이번 연구와 가장 근접한 것으로는, Min et al. (2020)과 Lewis et al. (2020)에서 open domain question answering을 위한 retrieval augmented generative model들을 소개하였다. 연구팀의 접근법은 이러한 연구들과는 다른데, generative model이 retrieved된 passage들을 처리하는 과정에서 다르다. 이는 많은 숫자의 document로 scale할 수 있게 하여, 거대한 양의 evidence를 통한 이점을 얻을 수 있다.
3 Method
이번 section에서는, 연구팀의 open domain question answering에 대한 접근법을 묘사한다. 총 2단계로 진행되는데, support passage들을 retrieving한 후에 이들을 sequence-to-sequence model로 처리한다.
Retrieval.
Support passage들의 retrieval를 위해서, 연구팀에서는 2가지 방법을 고려한다. BM25(Robertson et al., 1995)와 DPR(Karpukhin et al., 2020)이다. BM25에서는, passage들은 bag of words로 표현되며, ranking function은 term과 inverse document frequencies를 기반으로 한다. 연구팀에서는 Apache Lucene(open-source search software를 개발하는 프로젝트로, 여기서 core한 프로젝트로 Lucene Core가 있는데, 이는 indexing 및 search feature를 제공하는 Java library이다.)로부터의 구현체를 default parameter로 사용하고, SpaCy를 사용하여 question 및 passage들을 tokenize한다. DPR에서는, passage 및 question들은 dense vector representation들로 표현되며, 2개의 BERT network를 사용하여 계산된다. Ranking function은 query representation 및 passage representation 사이의 내적이다. Retrieval은 FAISS library를 통해 approximate nearest neighbor들을 사용하여 수행된다.
Reading.
Open domain QA를 위한 generative model은, T5 또는 BART(Raffel et al., 2019; Lewis et al., 2019)와 같이 unsupervised data로 pretrained된 sequence-to-sequence network에 기반을 둔다. 이 모델은 input으로써 question 및 support passage들을 받고, answer를 generate한다. 더 구체적으로는, 각각의 retrieved된 passage와 각 제목은 question과 함께 concatenated되며, encoder에 의하여 다른 passage들로부터 독립적으로 처리된다. 연구팀에서는 “question:”, “title:”, “context:”라는 special token들을 question과, 각 passage의 title, text 이전에 붙여주었다. 마지막으로, decoder는 모든 retrieved된 passage들의 representation의 concatenation에 대한 attention을 수행한다. 이 모델은 결국 decoder 만으로 evidence fusion을 수행하며, 연구팀에서는 이를 Fusion-in-Decoder라고 명명한다.

encoder에서는 passage들을 독립적으로 처리하지만, decoder에서는 함께 결합하여 처리함으로써, 이 방법은 Min et al. (2020)과 Lewis et al. (2020)에서와는 다르다. encoder에서 passage들을 독립적으로 처리하는 것은 context들의 숫자를 크게 scale하는 것을 가능하게 하며, 이 이유는 바로 한번에 오직 1개의 context에 대해 self attention을 수행하기 때문이다. 이는 모델의 계산 시간이 passage의 숫자에 따라 quadratically하게(O(N^2))가 아닌 선형적으로 증가(O(N))한다는 것을 의미한다. 반면에, decoder에서 passage들을 결합하여 처리하는 것은 여러 passage에서 evidence를 더 잘 합치도록 만들어준다.
4 Experiments
이번 section에서는, 연구팀은 open domain QA를 위한 Fusion-in-Decoder에 대한 경험적인 평가에 대해 보고한다.
Datasets.
연구팀은 다음과 같은 dataset들에 대해 고려하며, Lee et al. (2019)에서와 같은 환경을 사용한다.
NaturalQuestions (Kwiatkowski et al., 2019)는 Google search queries에 대응하는 question들을 포함한다. 이 dataset의 open-domain 버전은 5개 이상의 token이 있는 answer들은 버림으로써 얻어졌다.
TriviaQA (Joshi et al., 2017)은 trivia and quiz-league 웹사이트들로부터 모아진 question들을 포함한다. TriviaQA의 unfiltered 버전이 open-domain question answering에 사용된다.
SQuAD v1.1 (Rajpurkar et al., 2016)은 reading comprehension dataset이다. Wikipedia로부터 extracted된 paragraph가 주어졌을 때, annotator들은 question을 작성하도록 요구 받았고, 이에 대한 answer는 대응하는 paragraph에서 나온 span이다.
Lee et al. (2019)의 방식을 따라서, 연구팀에서는 validation을 test로써 사용하고, validation을 위해서 training set의 10%를 보존한다. 연구팀은 NQ 및 TriviaQA에 대해서는 2018년 12월 20일자 기준, SQuAD에 대해서는 2016년 12월 21일자 기준의 Wikipedia dump들을 사용한다. 연구팀은 Chen et al. (2017); Karpukhin et al. (2020)에서와 동일한 preprocessing을 적용하며, 이를 통해 100개의 단어로 이루어진 passage들이 되며, 서로 겹치지 않는다.
Evaluation.
예측된 answer들은 standard exact match metric (EM)을 통해 평가된다. Generated된 answer는 normalization 이후에 인정 가능한 정답들의 리스트 중 어떤 정답이라도 match된다면 정답으로 간주된다. 이 normalization 단계는 lowercasing(소문자화) 및 관사, 문장부호, 중복된 공백문자를 제거하는 것으로 구성된다.
Technical details.
연구팀은 모델들을 pretrained된 T5 model들로 초기화하며, 이는 HuggingFace Transformers library에서 이용 가능하다. 연구팀은 2개의 model size를 고려하는데, 각각 base와 large이며, 각각 parameter 개수는 220M, 770M이다. 연구팀은 각 dataset에 대해 독립적으로 model들을 fine-tune하며, Adam을 사용하며, 학습률은 10^-4로 고정이고, dropout 비율은 10%이다. 연구팀은 모델을 총 10000번의 gradient step, batch size=64, 그리고 64개의 Tesla V100 32휴를 사용하여 훈련시킨다. 연구팀은 모델들을 매 500 step마다 평가하여 Exact Match score를 기반으로 하여 validation set에 대해 가장 좋았던 순간을 선택한다. NaturalQuestions와 SQuAD로 훈련하는 동안에, 연구팀은 answer들의 리스트에서 target을 샘플링 하였으며, 반면에 TriviaQA로 훈련하는 동안에는, unique한 human-generated answer를 사용한다. TriviaQA에서는, 대문자인 answer들은 각 단어의 첫 글자를 제외하고 소문자로 바꾸어 normalized 되었으며, 이는 Python 내의 “title”이라는 string method(공백을 기준으로 각 단어들의 첫 글자는 대문자, 나머지는 소문자로 만들어주는 메소드이다.)를 사용하여 수행했다. Training과 testing 모두에서, 연구팀은 100개의 passage들을 retrieve하고 이들을 250개의 word piece들로 truncate한다. Karpukhin et al. (2020)의 결과를 따라서, passage들은 NQ와 TriviaQA에서는 DPR을 통해 passage들을 retrieve하며, SQuAD에서는 BM25를 통해 retrieve한다. 연구팀은 greedy decoding을 사용하여 answer들을 generate한다.
Comparison to state-of-the-art.
Table 1에서, 연구팀은 Fusion-in-Decoder를 통해 얻어진 결과와 기존 open domain question answering에서 쓰인 접근법들과 비교한다.

연구팀에서는 다음과 같은 사실을 관측하였다. 먼저 Fusion-in-Decoder가 개념적으로는 간단하지만, NaturalQuestion 및 TriviaQA benchmark들에서 기존의 존재하는 방법들의 성능을 압도한다는 것이다. 특히, generative model들은 기존의 extractive model들과 비교하여 여러 passage들로부터 evidence를 합쳐야 하는 경우에 더 잘 동작하는 것으로 보인다. 연구팀의 방법은 또한 다른 generative model들보다 더 잘 동작하며, passage의 숫자를 늘리고 처리함으로써 정확도의 향상을 이끌어 낸다는 것을 보였다. 두 번째로, 연구팀에서는 retrieval을 사용함으로써 generative model에서 additional knowledge를 사용하는 것은 엄청난 성능 향상으로 이끈다는 것이다. NaturalQuestions에서, closed book T5 model은 110억개의 parameter로 36.6%의 정확도를 달성하는 반면, 연구팀의 접근법은 7.7억개의 parameter 및 Wikipedia에다가 BM25 retrieval을 함께 사용하여 44.1%를 달성하였다. 두 방법 모두 정보를 저장하는 데에 대략 같은 양의 메모리를 사용하며, 이는 text based explicit memories(텍스트 기반 명시적 기억?; 명시적 기억은 언어로 서술할 수 있는 기억이라는 의미의 심리학 용어로 나옴)가 knowledge retrieval task들에서 경쟁력이 있음을 시사한다.
Scaling with number of passages.
Figure 3에서는, retrieved된 passage들의 개수에 따른 성능을 보고한다.

특히, 연구팀에서는 다음을 발견하였다. Passage의 개수를 10에서 100으로 늘리는 것이 TriviaQA에서는 6%의 향상을, NaturalQuestions에서는 3.5%의 향상을 이루었다는 것이다. 반면에, 대부분의 extractive model들의 성능은 10~20 passage에서 최고점을 찍는 것으로 보인다. 연구팀은 이것이 sequence-to-sequence mode들이 여러 passage로부터 정보를 결합하는 것을 잘하는 증거라고 믿는다.
Impact of the number of training passages.
이전 section에서, model은 동일한 개수의 passage들로 훈련되고 평가되었다. 훈련 계산 비용을 줄이기 위한 단순한 solution은 더 적은 passage들로 model을 훈련시키는 것이다. Table 2에서는, passage 개수를 달리 하여 훈련하여 얻어진 성능을 보고한다. (테스트 시에는 100개의 passage로 진행된다.)

연구팀에서는 training에 사용되는 passage의 숫자를 줄이는 것이 정확도의 감소로 이어진다는 것을 관찰하였다. 더 나아가, 연구팀에서는 1000 step 동안 100개의 passage를 사용하여 기존 모델들을 finetune하는 것을 제안한다. 이를 통해 정확도 차이를 줄일 수 있으며, 동시에 계산 resource는 훨씬 줄일 수 있다. 결과적으로, NaturalQuestions에서 46.0 EM을 147 GPU 시간을 써서 달성하였고, 이는 100개의 passage로 훈련 시 총 425 GPU 시간이 걸린 것과 비교된다.
5 Conclusion
이번 논문에서, 연구팀은 open domain question answering에 대해 간단한 접근법을 연구하였으며, support passage들을 retrieving한 이후에 이들을 generative model로 처리하는 방법이다. 연구팀에서는 개념적으로 간단하지만, 이 방법이 기존에 있던 방법들과 경쟁력이 있으며, retrieved passage의 개수를 scale하는 것이 용이하다는 것을 보였다. 후속 연구에서는, 특히 support passage의 개수를 크게 scale할 때에 이 model을 더 효율적으로 만들 계획을 하고 있다. 연구팀은 또한 model에서 retrieval을 통합할 계획을 하고 있으며, 전체 시스템을 end-to-end로 학습 시킬 계획을 하고 있다.
References
생략
'Naver BoostCamp AI Tech 3기' 카테고리의 다른 글
| ELECTRA: PRE-TRAINING TEXT ENCODERSAS DISCRIMINATORS RATHER THAN GENERATORS (0) | 2022.07.06 |
|---|---|
| User Guide for KOTE: Korean Online Comments Emotions Dataset (0) | 2022.05.26 |
| Dense Passage Retrieval for Open-Domain Question Answering (0) | 2022.04.28 |
| [MRC] 03. Generation-based MRC (0) | 2022.04.27 |
| [MRC] 02. Extraction-based MRC (0) | 2022.04.26 |