2022. 3. 24. 15:48ㆍNaver BoostCamp AI Tech 3기
Abstract
Language model pretraining은 엄청난 성능 향상으로 연구들을 이끌었지만, 조심스레 다른 접근법들과 비교되고 있다. Training의 계산 비용은 expensive하고, 각기 다른 사이즈의 private dataset들로 훈련되며, hyperparameter 선택은 최종 결과에 엄청난 영향을 끼친다. 많은 주요한 hyperparameter들과 training data size의 영향을 조심스레 비교하는 BERT pretraining에 대한 replication study(이전의 연구들을 약간 다르게 하여 재현, 반복함)를 제시할 것이다. RoBERTa 연구팀에서는 BERT가 많이 undertrained되었으며, 이 BERT 이후에 나온 모든 모델들의 성능을 따라잡거나 역전할 수 있음을 발견하였다. 이 연구팀의 가장 좋은 모델은 GLUE, RACE, SQuAD에서 sota를 달성하였다. 이러한 결과들은 이전에는 간과되었던 디자인들의 선택의 중요성을 강조하며, 최근에 언급된 성능 향상들의 source에 대한 의문을 제기한다. 모델과 코드는 공개한다.
1 Introduction
기존의 ELMo, GPT, BERT, XLM, XLNET과 같은 self-training 방법들이 어떤 측면으로 인하여 성능이 향상되었는지 이유를 설명하기가 어렵다. RoBERTa 연구팀에서는 기존 BERT 모델의 훈련 방식을 개선하여, RoBERTa라는 방법을 제시한다. 이 방법은 기존 BERT 모델 이후의 방법들의 성능을 따라잡거나 추월하는 정도이며, 다음과 같은 변경점들이 있었다.
(1) 더 많은 데이터, 더 거대한 batch로 모델을 더 오랫동안 학습함
(2) next sentence prediction objective를 제거함
(3) 더 긴 sequence로 훈련함
(4) training data에 적용되는 masking pattern을 동적으로 변화시킴
이렇게 개선된 방식으로 훈련 시, GLUE와 SQuAD에 대해 BERT의 결과가 개선되었는데, 더 긴 sequence의 추가적인 데이터로 훈련하여 GLUE leaderboard에서는 88.5를 달성하였다(기존에는 88.4). MNLI, QNLI, RTE, STS-B에 대하여 새로운 sota를 달성하였다. SQuAD와 RACE에 대해서는 기존 sota에 근접하였다. 연구팀에서 강조하는 것은, BERT의 masked language model training objective가 다른 objective들과 비교하면 상당히 괜찮은 objective라는 것이다.
요약을 하자면, 다음과 같다.
(1) BERT design 선택지 및 training 전략을 제시할 것이고, downstream task 성능을 더 높이기 위한 대안책을 제시할 것이다.
(2) CC-News와 같은 새로운 데이터셋을 사용, 이에 대한 결론은 바로 pre-training에 data를 더 사용하면 downstream task의 성능이 증가한다는 것이다.
(3) design을 잘 선택한다면, masked language model pretraining이 objective로써 괜찮다.
2 Background
이번 section에서는 BERT pretraining 및 앞으로 설명할 training choice들에 대한 간단한 overview를 제시할 것이다.
2.1 Setup
BERT의 입력으로는 2개의 segment를 결합한 문장을 input으로 받게 된다. 보통 2개 이상의 문장을 하나의 단일 input sequence로 표현하며, 다음과 같은 형태로 표현한다.
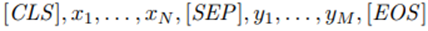
이 sequence의 길이는 parameter로 지정한 maximum sequence length를 넘지 않는다.
모델은 처음에는 거대한 unlabeled text corpus로 훈련, 그 후에는 end-task(downstream-task) labeled data로 fine-tune한다.
2.2 Architecture
너무나도 광범위하게 쓰이는 transformer 아키텍처를 사용하며, 이 논문에서는 L개의 layer를 가지고, 각 block에서는 A개의 self-attention head를 사용하고, hidden dimension은 H로 설정한다.
2.3 Training Objectives
Pre-training 동안에 2가지 objective를 사용하는데, masked language modeling 및 next sentence prediction을 사용한다.
Masked Language Model (MLM)
Input sequence에서 랜덤하게 선택된 token들은 [MASK] 토큰으로 교체된다. MLM의 objective는 masked token들의 예측에 대한 cross-entropy loss이다. uniformly하게 input token 중 15%를 선택하여 교체 후보에 올린다. 이 후보들 중 80%는 실제로 [MASK]로 교체하고, 10%는 그대로 납두며, 나머지 10%는 vocabulary 상에서 랜덤하게 선택한 token으로 교체된다.
원래 구현(원본 BERT)에서는 처음에 random masking이 이루어지고 training동안에 유지되었지만, 실제로는 데이터가 중복되므로 모든 훈련 문장들에 대해 마스크가 항상 동일하지는 않다.
Next Sentence Prediction (NSP)
NSP는 원래 텍스트에서 2개의 segment가 실제 앞뒤 문장인지를 예측하는 binary classification이다. Positive example은 연이은 2개의 문장을 엮어서 만들며, negative example은 각각 다른 document에서 문장을 엮어서 만든다. Positive, negative는 동일한 비율로 샘플링된다.
이 NSP objective는 문장 간의 관계를 추론해야 하는 Natural Language Inference 같은 downstream task들의 성능을 높이기 위해 디자인되었다.
2.4 Optimization
Adam optimizer를 사용하는데, beta1 = 0.9, beta2 = 0.999, epsilon = 1e-6, L2 weight decay = 0.01이다. 학습률은 첫 10,000 step동안은 상승하여 peak를 찍고, 이후 선형적으로 감소한다. 모든 layer 및 attention weight에 대해 0.1의 dropout을 적용하며, GELU activation을 사용한다. 모델 훈련 시 update는 1,000,000번, mini-batch size는 256, maximum length T = 512이다.
2.5 Data
BOOKCORPUS와 English WIKIPEDIA를 통해 학습하였고, 압축해제한 text의 크기는 16GB였다.
3 Experimental Setup
이번 section에서는, 연구팀의 BERT replication study에 대한 실험 setup을 묘사한다.
3.1 Implementation
BERT를 FAIRSEQ로 다시 구현하였다. Hyperparameter는 Section 2에서 주어진 대로 따랐으며, 단 peak learning rate와 warmup step은 각각 따로 tuned 되었다. 그리고 training 시 Adam epsilon term에 민감하다는 것을 발견하였고, 이를 tuning하여 더 좋은 성능을 얻기도 하였다. 그리고 더 큰 batch size로 훈련 시 안정성을 높이기 위해 beta2 = 0.98이 좋다는 것을 발견하였다.
Maximum sequence length는 512이며, 첫 90%의 update 동안에는 sequence length를 줄이지 않으며, full-length sequence로만 훈련한다.
DGX-1 machine들로 mixed precision floating point arithmetic으로 훈련하며, 각 machine에는 8개의 32GBNvidia V100 GPU를 인피니밴드(고성능 컴퓨팅과 기업용 데이터 센터에서 사용되는 스위치 방식의 통신 연결 방식)로 상호연결 하였다.
3.2 Data
BERT-style의 pretraining은 많은 데이터양에 의존하며, 데이터양이 커진 결과 end-task의 성능 향상으로 이어질 수 있다. 그러나 모든 추가적인 데이터셋들이 공개적으로 released된 것은 아니다. 연구팀에서는 실험을 위해 데이터의 전반적인 퀄리티와 양을 맞추면서 최대한 데이터를 모았다.
5개의 영어 corpora를 고려하는데, size, domain 등이 다양하며 압축하지 않은 크기는 총 160GB를 넘는다. 다음과 같은 corpora를 사용한다.
- 원래 BERT에 사용된 BOOKCORPUS 및 English WIKIPEDIA를 사용한다. (16GB)
- CommonCrawl News 데이터셋의 영어 부문에서 모은 CC-NEWS, 데이터는 6300만개의 영어 뉴스 기사를 포함한다. (필터링 이후에는 76GB)
- GPT-2에서 소개된 WebText corpus를 다시 구축하여 나온 오픈소스인 OPENWEBTEXT가 있다. (38GB)
- “A Simple Method for CommonSense Reasoning”에서 소개된 STORIES를 사용한다. 여기서 CommonCrawl data의 부분집합을 필터링하여 Winograd schemas에서의 story-like style의 데이터셋이 되었다. (31GB)
3.3 Evaluation
이전의 연구들을 참고하여 downstream task들에 대해 다음 3개의 benchmark를 사용하여 연구팀의 pre-trained model을 평가한다.
GLUE
GLUE benchmark는 자연어 이해 system을 평가하기 위한 9개의 dataset의 모음이며, 여기서 평가할 task들은 single-sentence classification 또는 sentence-pair classification task들로 취급할 수 있다. GLUE를 제작한 쪽에서는 training data, development data, submission server, leaderboard를 제공하여 그들의 system을 private held-out test data에 대해 평가할 수 있게 구축하였다.
Section 4에 있을 replication study를 위해, single-task training data로 pre-trained model을 fine-tuning 한 이후의 development set에 대한 평가 결과를 보고한다. Fine-tuning 과정은 기존 BERT의 과정을 따른다.
Section 5에서는 public leaderboard로부터 얻은 test set에 대한 평가 결과를 보고한다. 이 결과들은 여러 task-specific한 modification에 의존적이며, 자세한 것은 Section 5.1에 묘사한다.
SQuAD
SQuAD에서는 context와 question의 paragraph를 제공한다. Task는 바로 context에서 관련된 span을 추출하여 question에 대해 대답하는 것이다. 연구팀에서는 SQuAD V1.1과 SQuAD V2.0으로 평가하며, V1.1에서는 context에 answer가 항상 존재하며, V2.0에서는 몇몇 question들이 context 내에 없어서 task가 더 어려워지게 된다.
SQuAD V1.1에서는 BERT에서와 같은 span prediction 방법을 사용하며, SQuAD V2.0에서는 question이 대답 가능한지를 판별하는 binary classifier를 추가하며, 훈련 시 classification loss와 span loss를 합함으로써 결합하여 훈련한다. 평가 시에는, 오직 대답 가능한 것으로 분류된 문제들만 span indices를 예측하게 된다.
RACE
RACE task는 대규모의 독해 dataset으로, 28,000개의 지문과 대략 100,000개의 질문이 있다. 이 데이터셋은 중국에서 중학생 및 고등학생을 대상으로 한 영어지문에서 수집되었다. RACE에서는, 각 지문은 여러 개의 질문들과 연관된다. 모든 질문에 대해서, task는 사지선다에서 답을 찾는 것이다. RACE는 다른 독해 데이터셋들보다 훨씬 긴 지문을 가지며, 추론을 요구하는 질문의 비중도 매우 크다는 특징이 있다.
4 Training Procedure Analysis
이번 section에서는 BERT를 pre-training 시 성공적이였던 선택지들을 소개한다. 모델 아키텍처는 오리지널과 동일하며, 명시적으로 BERT_BASE는 L = 12, H = 768, A = 12, 총 110M parameters이다.
4.1 Static vs. Dynamic Masking
Section 2에서 언급한 대로, BERT는 랜덤 마스킹 및 토큰 예측을 하게 되는데, 기존의 BERT 구현에서는 이 랜덤 마스킹을 data preprocessing에서 진행하게 된다. 따라서, 단일 static mask를 사용하게 되는 것이다. epoch마다 같은 mask를 사용하는 것을 방지하기 위해, training data를 10배 중복시켜서 각 sequence들이 10가지 다른 방식으로 masked 되고, 총 40 epoch 동안 학습되도록 하였다. 결과적으로, training 동안 각 sequence에 대하여 같은 mask는 4번 정도 보였다.
이 방법과 dynamic masking을 비교할 것인데, dynamic masking은 모델에 sequence를 투입할 때 마다 masking pattern을 만드는 방식이다. 이는 더 많은 step 또는 더 거대한 데이터셋으로 pre-training 시 중요해진다.
Results
Table 1은 기존의 BERT_BASE와 연구팀에서 static masking 및 dynamic masking으로 다시 구현한 BERT의 결과를 비교한 것이다.

결과는, static masking으로 재구현한 결과는 original BERT 결과와 비슷하며, dynamic masking은 static masking과 비슷하거나 좀 더 좋았다.
이 결과를 토대로, 남은 실험들에서는 dynamic masking을 사용할 것이다.
4.2 Model Input Format and Next Sentence Prediction
오리지널 BERT pre-training 과정에서는, 모델은 2개의 segment를 결합한 input을 보게 되는데, 여기서 각 segment가 같은 document에서 연속으로 왔을 확률과 서로 다른 document에서 왔을 확률이 각각 0.5이다. Masked language modeling objective 뿐만 아니라, 모델은 보조적인 NSP loss를 통해서 이 segment들이 연속된 것인지 아닌지를 판단하는 task를 훈련 받게 된다.
NSP loss는 오리지널 BERT 훈련 시 중요한 요소로 가정되었다. 기존에는 이 NSP task를 제거하면 특정 downstream-task들에 대해 치명적인 성능 저하가 있다고 말했지만, 최근 연구들에서는 이 NSP loss의 필요성에 의문을 제기해왔다.
이 불일치를 더 잘 이해하기 위해, training에 대한 여러 대안책들과 비교를 해보았다.
SEGMENT-PAIR+NSP
오리지널 BERT의 형태이다. 각 input은 segment의 쌍을 가지며, 각 segment에는 여러 자연어 문장을 가질 수 있지만, 총 길이는 512 이하여야 한다.
SENTENCE-PAIR+NSP
각 input은 자연어 문장들의 쌍을 가지며, 하나의 document에서 연속으로 샘플링되거나, 각기 다른 document에서 샘플링된다. 이 input들은 512 token보다 매우 적으므로, SEGMENT-PAIR+NSP와 총 token 수가 비슷해지도록 batch size를 증가시킨다. NSP loss는 유지한다.
FULL-SENTENCES
각 input은 1개 혹은 그 이상의 document들에서 연속으로 샘플링된 전체 sentence들이 묶인 형태이며, 총 길이는 최대 512 token이다. Input이 document간의 경계를 넘길 수도 있다. 만약 document의 끝에 도달하면, 다음 document에서 샘플링을 재개하며 document 사이를 구분하는 추가적인 separator token을 삽입한다. NSP loss는 제거한다.
DOC-SENTENCES
FULL-SENTENCES와 비슷하게 input이 구성되는데, 차이점은 여기서는 document 간의 경계를 넘을 수 없다는 것이다. Input이 document 끝 근처에서 샘플링되면 아마 512 token보다 짧아질 것이며, 이 경우는 FULL-SENTENCES와 총 token 수를 비슷하게 맞추기 위해 batch size를 동적으로 증가시킬 것이다. NSP loss는 제거한다.
Results
Table 2에서 위에 언급한 4가지 setting에 대한 결과를 보여준다.

먼저, 기존에 쓰였던 SEGMENT-PAIR를 SENTENCE-PAIR와 비교하는데, 둘 다 NSP loss는 유지하였지만, 후자는 단일 문장들을 사용한다. 여기서 알 수 있는 것은, 개별 문장을 사용하는 것은 downstream task 성능에 해가 되며, 연구팀에서는 이 이유를 모델이 long-range dependencies를 학습하지 못하기 때문이라고 가정한다.
그 다음은 FULL-SENTENCES와 DOC-SENTENCES를 비교하는데, 여기는 둘 다 NSP loss를 제거하였다. 여기서 알 수 있는 것은, 이 setting이 기존의 BERT_BASE 결과를 압도하며, NSP loss를 제거한 것이 downstream task들의 성능에 맞먹거나 살짝 앞선다는 것이다. 이는 기존 연구 결과와는 대조적인 결과이다. 아마 오리지널 BERT에서는 SEGMENT-PAIR 형태로 유지한 채로 NSP loss를 제거해서 그러한 결과를 얻었을 수도 있을 것 같다.
마지막으로, DOC-SENTENCES가 FULL-SENTENCES보다 조금 더 좋다는 것을 발견하였다. 그러나, DOC-SENTENCES는 batch size가 각각 달라지는 결과로 이어지므로, 앞으로의 실험에서는 비교를 더 쉽게 하기 위해 FULL-SENTENCES를 사용할 것이다.
4.3 Training with large batches
이전 연구들에서, 매우 큰 사이즈의 mini-batch로 훈련 시, 학습률이 적절히 증가된다면, optimization 속도와 end-task 성능이 상승한다는 것이 보여졌다. 최근 연구에서는 이것을 BERT에도 적용 가능하다는 것을 보였다.
오리지널 BERT에서는 BERT_BASE를 batch size 256으로 1M step 만큼 훈련시켰다. 이는 gradient accumulation을 이용하면 계산 비용 측면에서, batch size 2000으로 125K step으로 훈련하는 것, 또는 batch size 8000으로 31K step으로 훈련하는 것과 동일하다.
Table 3에는 epoch 수는 유지하면서, batch size를 증가하는 것으로 인한 BERT_BASE의 perplexity와 end-task 성능을 비교한다.

여기서 관찰할 수 있는 것은, 더 큰 batch로 훈련하는 것이 masked language modeling objective에 대한 perplexity와 end-task accuracy의 성능을 개선시킨다는 것이다. 큰 batch는 또한 distributed data parallel training으로 병렬화 하기 더 쉬우며, 앞으로의 실험들에서는 훈련 시 batch size를 8000으로 한다.
“Large Batch Optimization for Deep Learning: Training BERT in 76 minutes”의 논문에서는 특히 BERT를 훈련 시 batch size를 더욱 더 크게 하여 32000으로 하였다.
4.4 Text Encoding
BPE는 character-level과 word-level 사이의 hybrid representation으로, 자연어 corpora에서 거대한 vocabulary를 다룰 수 있게 해준다. 서브워드는 통계적인 분석 방식을 통해 추출한다.
BPE vocabulary의 크기는 다양하지만, 거대하고 다양한 corpora를 모델링 시 Unicode character들이 상당 부분을 차지하게 된다. 오리지널 BERT에서는 Unicode character 대신 byte를 기본 서브워드 유닛으로 사용하는 현명한 BPE 구현 방식을 소개하였다. Byte 방식은 vocabulary size를 50K 정도로 작게 유지할 수 있으며, unknown token 없이 encode가 가능하다.
오리지널 BERT 구현에서는 character-level BPE vocabulary(30K)를 사용하며, 휴리스틱한 tokenization과 함께 전처리 이후 학습된다. 이번 논문에서는 이를 따라서 비슷하게 BPE vocabulary size만 50K로 늘리고 나머지는 동일하게 하여 진행한다. 이는 BERT_BASE, BERT_LARGE에 대해 각각 15M개와 20M개의 추가적인 파라미터를 추가하는 것이다.
초기에 이루어진 실험들에서는 이 encoding들 사이의 작은 차이점을 밝히고, 결과적으로 오리지널 BERT의 encoding 성능이 일부 end-task에서 더 안좋은 성능을 기록한다고 말했다. 그럼에도 불구하고, 그 사소한 성능 저하 정도는 이 universal한 encoding의 장점이 덮을 수 있다고 보며, 그래서 남은 실험들에서는 이 BPE encoding을 사용할 것이다.
5 RoBERTa
이전 Section에서 다루었던 BERT pre-training에 대한 변경점들을 총 통합하여 보는 section이다. 이 변경점들을 다 합쳐 개선한 BERT를 이제 Robustly optimized BERT approach, 줄여서 RoBERTa라고 부를것이다. RoBERTa는 다음과 같은 변경점들이 있다.
- dynamic masking (Section 4.1)
- FULL-SENTENCES without NSP (Section 4.2)
- large mini-batches (Section 4.3)
- larger byte-level BPE (Section 4.4)
추가적으로, 이전 연구들에서 잘 강조되지 않았던 중요한 2가지 요소 역시 짚고 넘어간다.
(1) pre-training에 사용되는 data
(2) data를 통과하는 training 숫자
예를 들어, XLNet 아키텍처는 오리지널 BERT보다 10배 많은 데이터에, optimization step은 절반에 batch size는 8배 더 크게 훈련된다. 따라서, BERT와 비교하면 4배 더 많은 sequence를 보게 된다.
모델링 선택에서 이 요소들이 중요한 이유를 설명하기 위해, RoBERTa 훈련은 BERT_LARGE 아키텍처를 따라 훈련하는 것으로 시작한다. (L = 24, H = 1024, A = 16, 355M parameters) pre-train은 오리지널 BERT에서 사용된 BOOKCORPUS + English WIKIPEDIA 데이터셋으로 100K step만큼 훈련하며, 1024개의 V100 GPU들로 대략 하루 동안 훈련하였다.
Results
이 결과가 Table 4에 나와있다.

테이블에서 알 수 있듯이, training data를 잘 control한 모델 디자인을 선택하면 오리지널 BERT_LARGE 결과에서 크게 개선된 결과를 얻을 수 있다.
다음으로, Section 3.2에서 언급된 3개의 추가 데이터셋(총 160GB)을 결합하여 훈련한 RoBERTa에서 성능이 모든 downstream task들에 대하여 향상되었다. 데이터 사이즈와 다양성이 중요하다는 것을 다시금 증명했다.
마지막으로, RoBERTa를 훨씬 더 오래 pre-train하는 것으로, 100K에서 300K, 500K로 늘렸다. 그 결과, 또 다시 기존보다 성능이 더더욱 향상된 것을 확인할 수 있다. 심지어, 가장 많이 훈련한 500K도 아직 overfitting이 아닌 것으로 보이며, 추가 훈련으로 성능 향상의 여지가 남아있다 볼 수 있다.
논문의 남은 부분에서는, 가장 성능이 좋은 RoBERTa 모델 (pre-train을 500K번 실시함)을 3개의 benchmark인 GLUE, SQuaD, RACE에 대하여 평가할 것이다.
5.1 GLUE Results
GLUE에서는 2개의 fine-tuning setting을 고려한다. 첫번째 setting은 (single-task, dev)로 각 GLUE task들에 대해 분리하여 RoBERTa를 각각 fine-tune한다. Hyperparameter는 batch size는 {16, 32}에서, learning rate는 {1e-5, 2e-5, 3e-5}에서 제한적으로 탐색하며, 훈련 중 첫 6% step 동안은 linear warmup을 하고, 이후 linear decay로 0에 수렴한다. 총 10 epoch를 fine-tune하며, dev set에 대해 각 task를 평가하여 early stopping을 수행한다. 나머지 hyperparameter들은 pre-training과 동일하게 유지한다. 이 setting에서는 각 task에 대해 5번의 랜덤 초기화를 거쳐 나온 중간값을 결과로 보고한다.
두번째 setting인 (ensembles, test)에서는, RoBERTa를 GLUE leaderboard를 통해 test set에 대해 다른 접근법들과 비교한다. GLUE leaderboard에 제출하는 것들은 보통 multi-task fine-tuning을 하고 진행하지만, 연구팀에서 제출하는 모델은 오직 single-task fine-tuning만 했다는 것을 명심해야 한다. RTE, STS, MRPC에 대해서는 MNLI single-task 모델에서 fine-tuning을 시작하는 것이 baseline pre-trained RoBERTa에서 하는 것 보다 낫다는 것을 발견하였다. 조금 더 넓게 hyperparameter를 탐색하였고, ensemble은 task당 5~7개 사이에서 탐색하였다. 자세한 것은 Appendix에 나와있다.
Task-specific modifications
GLUE task들 중 2개는 leaderboard에서 좋은 결과를 내기 위해서 task-specific한 fine-tuning 접근법을 요구한다.
QNLI
GLUE leaderboard에 올라온 최근 방식들은 pairwise ranking formulation을 채택하는데, 이 방식은 training set에서 정답 후보들을 뽑아 낸 다음 서로 비교한 다음, 단일 (question, candidate) pair가 정답으로 분류된다. 이 방식은 task를 단순화 시키지만, BERT와 직접 비교할 수 없다. 이에 따라, 연구팀에서는 BERT와 직접 비교를 위해 pure classification 접근법에 기반하여 development set에 대한 결과를 보고한다.
WNLI
제공된 NLI-format의 data는 다루기 어려우므로, 대신에 Super-GLUE에서 reformatted된 WNLI data를 사용한다. 이 data는 query의 대명사의 span을 알려준다. 연구팀은 RoBERTa를 margin ranking loss(“A Surprisingly Robust Trick for the Winograd Schema Challenge”에서 나옴)를 사용하여 fine-tune한다. 주어진 input sentence에 대해서, spaCY를 사용하여 추가적인 명사구를 문장에서 추출하고 fine-tune하여 긍정적인 대명사구에 부정적인 대명사구보다 더 높은 점수를 부여하도록 하였다. 그러나 그 결과, 기존 제공된 training example의 절반 넘게 제외하여 positive training example만 사용할 수 있었다.
Results
결과를 Table 5에 제시한다.

첫 번째 setting인 (single-task, dev)에서는, RoBERTa가 GLUE task development set에 대해 9개 전부에서 sota를 달성했다. 중요한 것은, RoBERTa는 BERT_LARGE와 동일한 아키텍처 및 masked language modeling pre-training objective를 사용한 것이며, 그럼에도 BERT_LARGE와 XLNET_LARGE 모두를 압도한다는 것이다. 이는 더 평범한 고려 사항인 dataset 크기나 training time과 같은 것들과 비교하여 모델 아키텍처와 pre-training objective의 중요성에 대해 의문을 제기한다.
두 번째 setting인 (ensembles, test)에서는, RoBERTa를 GLUE leaderboard에 제출한 결과 9개 task 중 4개에서 sota를 달성하며, 평균 score는 제일 높게 달성했다. 중요한 것은, 다른 top submission들과 달리 single-task fine-tuning을 했다는 것이다.
5.2 SQuAD Results
SQuAD에 대해서는 훨씬 더 간단한 접근법을 채택하는데, 이전 연구들과는 달리 training data augmentation 없이 오직 RoBERTa를 주어진 SQuAD training data만 사용하여 fine-tune 한다. 학습률 또한 모든 layer에 대해 동일한 학습률을 사용한다.
SQuAD v1.1에서는 오리지널 BERT와 동일한 fine-tuning 과정을 따른다. SQuAD v2.0에서는 주어진 질문이 대답 가능한지를 분류하는 추가적인 classifier를 삽입하고, 이 classifier는 classification loss와 span loss를 더해서 결합하여 훈련한다.
Results
Table 6에 결과가 나타나 있다.

SQuAD v1.1 development set에서는, RoBERTa는 XLNet의 sota와 맞먹는다. SQuAD v2.0 development set에서는, RoBERTa가 새로운 sota를 달성하며, XLNet보다 EM은 0.4, F1은 0.6 더 앞서게 된다.
또한 public SQuAD 2.0 leaderboard에 RoBERTa를 제출하여 평가해보았는데, 다른 시스템들과 비슷한 결과를 보인다. 그러나, 다른 system들은 추가적인 data에 의존하지만, RoBERTa는 전혀 추가 데이터를 사용하지 않았다.
결론적으로, RoBERTa 모델은 single model submission 중 1개를 제외하고 성능에서 압도했으며, data augmentation에 의존하지 않는 모델 중 가장 점수가 좋다.
5.3 RACE Results
RACE에서는 1개의 지문, 관련 질문, 그리고 사지선다 답 후보가 주어지며, 이 중 올바른 답을 찾는 것이 목적이다.
RoBERTa에서는 각 후보 답들을 각각 질문과 지문을 결합한다. 그러면 사지선다이므로 4개의 sequence가 나오게 되고, 이를 encoding하고 나온 [CLS] representation으로 fully-connected layer에 투입, 나온 결과로 올바른 정답을 예측한다. Question-answer pair가 128 token보다 길면 truncate하며, 만약 필요하다면 지문도 최대 길이가 512 token이 되도록 한다.
RACE test set에 대한 결과가 Table 7에 제시되어 있다. RoBERTa는 middle-school setting과 high-school setting 둘 다에서 sota를 달성한다.

6 Related Work
Pre-training 방법들은 많은 다른 training objective들(language modeling, machine translation, masked language modeling 등)로 디자인 되어 왔고, 기본적인 fine-tuning 방법들이 있으며, 기존 pre-training 방법에 변형 버전 등도 생겨났다. 그러나, 더 새로운 방법들(multi-task fine-tuning, entity embedding, span prediction, multiple variants of autoregressive pre-training)이 성능을 향상시켰다. 또한, 모델이 더 커지고 데이터를 더 많이 사용할수록 성능이 증가한다는 것이 알려졌다. 이번 RoBERTa 논문의 목표는 바로, 약간의 replicate 및 simplify를 통해 BERT의 훈련을 더 잘 tune하여 이와 관련된 방식들의 상대적인 성능 측정 시 더 잘 이해하도록 돕는 참고점이 되는 것이 목표였다.
7 Conclusion
RoBERTa 연구팀에서는 BERT model pre-training 시의 수많은 design 결정들에 대해 평가한다. 연구팀에서는 모델을 더 오랫동안, 더 많은 데이터에 더 큰 batch size, NSP objective 제거, 더 긴 sequence로 훈련, 그리고 training data에 적용되는 masking pattern을 dynamically하게 변화시킴으로써 성능이 대체로 향상될 수 있다는 것을 발견했다. 이 개선된 pre-training 과정을 RoBERTa라 부르기로 하였으며, GLUE에 대한 multi-task fine-tuning이나 SQuAD에 대한 추가적인 데이터 없이 GLUE, RACE, SQuAD에서 여러 sota 기록을 달성하였다. 이 결과들은 이전까지 간과되었던 design 결정의 중요성을 알려주며, BERT의 pre-training objective가 최근 제안되었던 대체 objective들과 여전히 경쟁력이 있다는 것을 제시한다.
연구팀에서는 추가로 새로운 데이터셋인 CC-NEWS를 사용하고 모델에 대한 pre-training 및 fine-tuning 코드를 다음에 공개하고 있다.