2022. 3. 14. 01:06ㆍNaver BoostCamp AI Tech 3기
Abstract
Question answering, machine translation, reading comprehension, summarization과 같은 자연어 처리 task들은 전형적으로 task-specific한 데이터셋으로 supervised learning의 방식으로 접근한다. 연구팀에서는 언어 모델들이 수백만개의 웹페이지들의 새로운 데이터셋인 WebText로 훈련될 때 supervision없이 이 task들을 학습하기 시작한다는 것을 증명한다. Document에 question이 더해진 조건에서, 언어 모델로 생성된 answer들은 CoQA 데이터셋에서 55 F1 score를 달성하는데, 이는 baseline system들 중 4분의 3정도와 성능이 비슷하거나, 더 높아진 결과이다.(127,000개 이상의 training example도 사용하지 않고 말이다.) 이 언어 모델의 수용력은 zero-shot(훈련 시 한번도 downstream의 data를 보지 않고 훈련하는 경우? Unseen data에 대해 unseen class를 예측하는 것이라고도 함) task transfer의 성공에 있어서 필수적이고 이 수용력을 증가시키면 task들에서 log-linear하게 성능이 향상된다. 연구팀의 가장 거대한 모델인 GPT-2는 1.5B(15억)개의 파라미터를 가진 Transformer로, zero-shot 세팅이며 언어 모델링 dataset 8개 중 7개에서 state-of-the-art를 달성한다. 그렇지만 여전히 WebText에 대해서는 underfitting이다. 이 모델의 샘플들은 이러한 개선 사항들을 반영하고 일관성이 있는 텍스트 단락을 포함한다. 이러한 발견들은 각 task들을 수행하는 방식을 그들 자체의 자연스럽게 발생하는 demonstration으로부터 배우는, 그러한 언어 처리 system을 만들기 위한 유망한 방법을 제시하는 바이다.
1 Introduction
머신 러닝 system들은 현재 거대한 데이터셋, 고용량의 모델들, supervised learning들을 사용하여 훈련되는 task들에 잘 동작한다. 그렇지만, 이러한 system들은 다루기 힘들고, 데이터 분포 및 task specification 내의 조그마한 변화에도 민감하다. 현재의 system들의 특징은 유능한 generalist라기 보다는 편협한 expert라는 느낌이다. (일반화가 잘 되지 않고, 특정 분야 task에만 최적화가 된 것 같은 느낌이다.) 연구팀에서는 많은 task들을 수행할 수 있는 조금 더 일반화된 system으로 이동하고 싶으며, 결국에는 각 task에 대해 훈련 데이터셋을 manually하게 생성하고 labeling할 필요가 없게 만들고 싶다.
ML system을 만드는 지배적인 접근법은 원하는 task에 대해 올바른 행동을 보이는 훈련 데이터셋을 모으고, 이 행동들을 모방하기 위해 system을 훈련시키고, 그 다음에는 분포는 동일하되 독립적인 데이터셋으로 이 성능을 측정하는 방식으로 진행된다. 이 방식은 편협한 expert들의 성능을 향상시키는 데에는 잘 동작해왔다. 그러나, captioning model, reading comprehension system, image classifier에서 다양하게 가능한 input으로 인해 나오는 종종 error 있는 행동들이 바로 이 접근법의 한계점을 강조해주고 있다.
연구팀에서 의심하는 점은 single domain 데이터셋으로 single task를 훈련시키는 방식이 널리 퍼져 있는 것이 바로 현 시점의 system들에서 관찰되는 일반화의 부족의 주요 원인이라는 것이다. 현재의 아키텍처들을 가지고 robust한 system들로 나아가는 것은 넓은 범위의 domain과 task들로 훈련하고 성능을 측정할 것을 요구한다. 최근에는, 이를 연구하기 위해서 GLUE나 decaNLP과 같은 여러 benchmark들이 제안되었다.
Multitask learning은 일반화 성능을 높이기 위한 유망한 framework이다. 그러나, NLP에서 multitask 훈련은 여전히 초기 상태에 머무른다. 최근의 연구에서는 성능의 향상은 미미하며 현재까지 가장 야심 찬 2가지 시도에서는 각각 10개와 17개의 (dataset, objective) 쌍으로 훈련한 것이다. Meta-learning(다른 task를 위해 학습된 모델을 이용해, 적은 데이터셋을 가지는 다른 task도 잘 수행할 수 있도록 학습시키는 방식)의 관점에서, 각각의 (dataset, objective) 쌍은 분포에서 샘플링 된 single training example이다. 현재의 ML system들은 일반화를 잘 시키는 function을 induce(유도)하기 위해서 수백개에서 수천개의 example이 필요하다. 이는 multitask 훈련이 현재의 접근법들로 위 사항을 실현하기 위해서는 그만큼 많고 효율적인 training 쌍이 필요하다는 것을 의미한다. 현재의 테크닉들로 이 방법을 brute force하기 위해 요구되는 정도로 데이터셋을 생성하고 objective를 디자인하는 것을 지속하는 것은 매우 어려울 것이다. 이는 multitask learning을 수행하기 위해 추가적인 setup을 탐색하도록 만든다.
현재 language task들에 있어 가장 잘 수행하는 system들은 pre-training과 supervised fine-tuning을 이용한다. 이 접근법은 transfer의 더욱 더 flexible한 형태로 나아가는 트렌드와 함께 기다란 역사를 가진 방식이다. 처음에는, word vector가 학습되었고 이것이 task-specific한 아키텍처들의 input으로 사용되었고, 그 다음에는 recurrent network의 contextual representation이 transfer되었고, 최근의 연구에 와서는 task-specific한 아키텍처가 더 이상 필요하지 않고, 많은 self-attention block들을 transfer하는 것으로 충분하다는 결론에 이르렀다.
이 방법들은 여전히 task를 수행하기 위해서 supervised training을 요구한다. 최소한의, 또는 아예 supervised 데이터가 이용이 불가능할 때, 다른 쪽의 연구에서는 언어 모델이 commonsense reasoning 및 sentiment analysis와 같은 특정한 task들을 수행할 가능성을 증명하였다.
이번 논문에서, 연구팀은 이 2가지 연구를 연결하고 transfer의 조금 더 일반화된 방법의 트렌드를 지속한다. 연구팀에서는 언어 모델들이 zero-shot 세팅에서 down-stream task들을 수행할 수 있다는 것을 증명하며, 이때 어떠한 파라미터 또는 아키텍처의 변화 없이 가능하다는 것을 보일 것이다. 연구팀은 zero-shot 세팅에서 넓은 분야의 task들을 수행할 언어 모델의 능력을 강조함으로써 이 접근법이 잠재력이 있다는 것을 증명할 것이다. Task에 따라서 경쟁력 있는 결과, 또는 state-of-the-art 결과를 달성한다.
2 Approach
GPT-2 접근법의 핵심은 language modeling이다. Language modeling은 보통 example (x1, x2, …, xn) (각각은 가변 길이의 sequence인 (s1, s2, …, sn)으로 이루어짐) unsupervised distribution을 추정하는 것으로 나타내어진다. 언어는 자연적이고 순차적인 순서를 가지므로, 조건부확률의 곱으로 결합확률을 분해하는 것이 일반적이다.
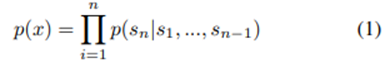
이 접근법을 통해서 p(x) 뿐만 아니라 p(sn-k, …, sn | s1, …, sn-k-1) 형식의 조건에서도 tractable(다루기 쉬운) 샘플링과 추정이 가능하다. 최근 몇 년 동안에는, 이러한 조건부확률들을 계산할 수 있는 모델들의 표현력에 엄청난 성능 향상이 있어왔으며, 예를 들어 self-attention 아키텍처의 Transformer등이 있다.
단일 task 수행을 학습하는 것은 p(output|input)의 conditional distribution을 추정하는 확률 framework로 표현할 수 있다. General한 system은 많은 다른 task들을 수행할 줄 알아야 하므로, 같은 input에 대해서라도, input 뿐만이 아닌 수행 되어야할 task도 조건에 들어가야만 한다. 즉, p(output|input, task)를 모델링 해야한다. 이는 multitask 및 meta-learning setting에서 다양하게 공식화 되어왔다. Task conditioning은 주로 아키텍처 level에서 구현되는데, 예를 들어 task specific한 encoder-decoder나 알고리즘 레벨에서 구현한 inner and outer loop optimization framework of MAML 등이 있다. 그러나, 언어는 task, input, output 모두를 symbol의 sequence로 특정화하는 유연한 방법들을 제공한다. 예를 들어서, 번역 task 훈련에서의 example로 다음과 같은 sequence가 작성될 수 있다. (translate to French, english text, french text). 비슷하게, 독해 task 훈련에서의 example로는 다음과 같이 작성될 수 있다. (answer the question, document, question, answer). McCann et al. (2018)에서는 단일 모델인 MQAN을 훈련시켜서, 이러한 형태의 example로 많은 다른 task들을 수행하고 추론하는 것이 가능하다는 것을 증명하였다.
Language modeling은 또한 원칙적으로는 McCann et al. (2018)에서의 task를 어떤 symbol이 예측되어야 하는 지에 대한 output의 명시적인 supervision 없이 학습시킬 수 있다. Supervised objective는 unsupervised objective와 동일하며, 단지 sequence의 subset에서 평가된다는 것을 제외하고는, unsupervised objective의 global minimum은 또한 supervised objective의 global minimum과 같다. 이러한 약간 달라진 상황에서(?)는, 원칙적으로 사용된 training objective로써의 density estimation(밀도 추정, 데이터로부터 변수의 확률분포를 추정하는 것, 즉 변수의 확률밀도함수를 추정하는 것임)에 대한 관심이 조금 밀려나게 되었다. 대신에, 해결해야할 문제는, 우리가 실제로 이 unsupervised objective를 수렴하게 최적화할 수 있느냐 없느냐로 바뀌었다. 예비적인 실험들에서는, 충분히 거대한 language model들은 이런 toy-ish한 setup에서 multitask learning을 수행할 수 있지만, 명시적인 supervised learning보다는 그 학습 속도가 훨씬 느리다는 것을 확인하였다.
비록 이는 위에서 묘사된 잘 구성된 setup에서부터 “language in the wild”(위와는 대조적으로 정교하게 구성되지 않은 setup을 의미하는 듯함)의 난장판으로까지의 거대한 step이지만, Weston (2016)은, dialog의 측면에서, 자연어로부터 직접적으로 학습할 수 있는 system을 개발할 필요성에 대해 주장하고, 이에 대한 개념을 증명해냈다. Dialog가 매력적인 접근법이지만, 지나치게 제한적이라는 점에서 우려스럽다. 인터넷은 상호 대화의 필요없이 수동적으로 이용 가능한 방대한 양의 정보를 가지고 있다. 연구팀의 추측은, 충분한 능력을 가진 language model이 획득 방법에 관계 없이 자연어 sequence에서 나타난 task들을 더 잘 예측하기 위해서, 추론하고 수행하는 법을 학습할 것이라는 거다. 만약 language model이 이를 수행할 수 있다면, 사실상, 이것은 unsupervised multitask learning을 수행하는 것이 될 것이다. 연구팀에서는 이 경우가 맞는지 아닌지를 다양한 task들에서 zero-shot setting인 상태에서 language model들의 성능을 분석함으로써 테스트할 것이다.
2.1 Training Dataset
대부분의 이전 연구들에서는 text의 단일 domain에서 language model들을 훈련시켰는데, 뉴스 기사, 위키피디아, 소설책 등이였다. GPT-2의 접근법에서는 가능한 다양한 domain과 context들에서 task들의 자연어 demonstration을 모으기 위해 가능한 거대하고 다양한 데이터셋을 구축한다.
다양하고 거의 무제한의 text로 유망한 source는 ‘Common Crawl’과 같은 웹 스크래핑이다. 이 아카이브들은 현재 존재하는 language modeling 데이터셋들보다 훨씬 더 규모가 크지만, 아주 중요한 데이터 품질 issue가 존재한다. Trinh & Le (2018)에서는 그들의 연구에서 commonsense reasoning을 위해 Common Crawl을 사용했지만, 많은 document에서 대부분의 내용물이 unintelligible하다고 말했다. GPT-2 연구에서도 초기 실험에서는 Common Crawl에 관련된 비슷한 데이터 이슈들을 관찰하였다. Trinh & Le (2018) 연구에서의 가장 좋은 결과는 Common Crawl의 작은 부분집합을 사용하여서 달성되었는데, 이는 target 데이터셋과 가장 유사했던 document 일부가 포함되어 있었다. 비록 이 방식이 특정 task의 성능을 향상시키기 위한 pragmatic한(화용론적인, 상황과 맥락에 따른 의미를 연구하는 언어학의 분야를 의미한다고 함) 접근법이지만, GPT-2에서는 수행 되어야할 task들에 대한 가정을 미리 하는 것을 회피하려고 하였다.
대신에, GPT-2에서는 document의 품질을 강조한 새로운 웹 스크래핑을 만들었다. 이를 위해 오직 사람에 의해 판별된 웹페이지들만 스크랩하였다. manually하게 전체 웹 스크래핑을 필터링 하는 것은 매우 비용이 많이들 것이므로, 시작점으로써, Reddit의 모든 외부 참조 링크를 스크랩하였는데, 이때 최소 추천 3개를 받은 것들만 스크랩하였다. 이는, 다른 사용자들이 이 링크가 흥미롭고, 교육적이고, 아니면 단지 재밌는지 아닌지에 대한 휴리스틱한 indicator로 생각될 수 있는 방법이다.
그렇게 하여 나온 최종 데이터셋인 WebText는 이 4500만개의 링크들의 text 부분집합을 포함한다. HTML response로부터 text를 추출하기 위해서, 연구팀에서는 Dragnet과 Newspaper content extractor들을 섞어서 사용하였다. 이 논문에서 제시된 모든 결과들은 WebText의 예비 버전을 사용하며, 여기에는 2017년 12월 이후에 생성된 링크들은 포함하지 않는다. 또한 중복 제거 및 일부 휴리스틱 기반의 정제후에 총 40GB의 text에 대해 800만개가 조금 넘는 document들을 포함한다. WebText로부터는 Wikipedia문서들은 전부 제거하였는데, 이는 다른 데이터셋들에 대한 공용적인 data source이며, test evaluation task들과 함께 훈련 데이터의 overlapping으로 인해 분석이 복잡 해질 수 있기 때문이다.
2.2 Input Representation
일반적인 language model(LM)은 어떠한 string이라도 확률을 계산할 수 있어야 하고 생성할 수 있어야 한다. 현재의 거대한 규모의 LM들은 lower-casing, tokenization, out-of-vocabulary token 등과 같이 model이 처리 가능한 string의 공간을 제약하는 pre-processing 단계를 포함한다. 유니코드 string들을 UTF-8 바이트들의 sequence로 현명하게 처리하는 것이 이러한 요구사항을 충족하지만, 현재의 byte-level LM들은 거대한 규모의 데이터셋(예를 들어 One Billion Word Benchmark)으로 훈련되는 word-level LM들과 비교하면 밀리는 상황이다. GPT-2에서는 WebText를 통해 표준적인 byte-level LM들을 훈련시키는 시도에서, 이러한 비슷한 성능 격차를 관찰하였다.
Byte Pair Encoding(BPE)는 character-level과 word-level language modeling 사이의 실용적인 중간 지점이며, 자주 등장하는 symbol sequence들에 대한 word-level input과 덜 등장하는 symbol sequence들에 대한 character-level input들 사이의 효율적인 interpolation(보간)을 한다. 이름과는 다르게, 참조되는 BPE 구현들에서는 보통 byte sequence들이 아닌 Unicode code point들에서 동작한다. 이러한 구현들은 모든 Unicode string들을 모델링하기 위해 Unicode symbol들의 전체 공간을 요구한다. 결과적으로 multi-symbol token들이 추가되기 전에는 13만개 이상의 base vocabulary가 만들어진다. 이는 보통 사용되는 BPE로 만들어진 32000~64000개의 token vocabulary들과 비교하면 엄청나게 크다. 이와 대조적으로, byte-level의 BPE는 base vocabulary로 256 사이즈만을 요구한다. 그러나, byte sequence에 BPE를 직접 적용하는 것은 sub-optimal한 merge로 이어지게 되는데, 이는 token vocabulary를 만들기 위한 휴리스틱 기반의 greedy frequency BPE를 사용하기 때문이다. 연구팀에서는 ‘dog’와 같은 흔한 단어들의 많은 버전을 BPE가 담고 있는 것을 관찰했는데, ‘dog.’, ‘dog!’, ‘dog?’와 같은 바리에이션들이 많이 있었다. 이로 인해 제한된 vocabulary slot과 model capacity의 sub-optimal한 할당의 결과로 나타난다. 이를 방지하기 위해서, 어떤 byte sequence에 대해서도 character 카테고리를 가로질러 merge하는 것은 방지한다. (쉽게 말해서, 영어는 영어와, 한글은 한글이랑만 merge하는 것임) 연구팀에서는 여러 개의 vocab token들에 걸쳐 최소한의 단어의 fragmentation만 추가하면서 압축의 효율성을 크게 향상시키는 예외적인 공간을 추가한다. (_나 ##같은걸 붙이는 듯함)
이 input representation은 word-level LM의 경험적인 장점과 byte-level 접근법의 일반성을 결합할 수 있게 해준다. GPT-2에서의 접근법이 어떠한 Unicode string에 대해서도 확률을 부여할 수 있기 때문에, 이것은 GPT-2의 LM들을 pre-processing, tokenization, vocab size 및 데이터셋에 상관없이 평가 가능하게 해준다.
2.3 Model
GPT-2의 LM으로는 Transformer 기반의 아키텍처를 사용한다. 모델은 크게는 OpenAI GPT-1 모델의 세부사항을 따르는데, 몇가지 변경점이 있다. Layer Normalization이 각 sub-block의 input으로 옮겨졌는데, 이는 pre-activation residual network와 비슷하다. 그리고 추가적인 layer normalization이 마지막 self-attention block 후에 추가되었다. 초기화는 모델의 깊이와 함께 residual path의 누적과 관련하여 변화하였다. 연구팀에서는 residual layer의 초기 가중치에 1 / root(N)을 곱하는데, 여기서 N은 residual layer의 개수이다. Vocabulary는 50257로 확장되었다. 또한 context size를 512에서 1024 token으로 증가시켰고, 더 큰 batch size인 512가 사용되었다.
3 Experiments
연구팀에서는 대략적으로 로그 간격이 균일한(?) 4개의 LM들을 벤치마크하고 훈련시켰다. 이 아키텍처들은 Table 2에 묘사되어 있다.

가장 작은 모델은 original GPT(GPT-1)와 동일하며, 두번째로 작은 모델은 BERT의 가장 큰 모델과 동일하다. 여기서 가장 큰 모델인 GPT-2는 GPT-1보다 훨씬 더 많은 parameter를 가진다. 각 모델의 학습률은 WebText에서 5% 정도 뽑은 sample로 평가하여 가장 좋게 나온 perplexity로 manually하게 설정되었다. 모든 모델들은 여전히 WebText에 대해 underfitting된 상태이며, 그러므로 여전히 훈련 시간을 더 쓴다면 held-out perplexity가 개선될 여지가 있다.
3.1 Language Modeling
Zero-shot task transfer의 초기 단계로써, 연구팀에서는 WebText LM의 zero-shot domain transfer에서, 훈련받은 주요 task인 language modeling에서 어떻게 수행되는지 흥미로워 한다. GPT-2가 byte-level에서 동작하고 손실이 있는 pre-processing 또는 tokenization을 요구하지 않으므로, 연구팀에서는 GPT-2를 어떠한 language model benchmark로도 평가할 수 있다. Language modeling dataset에 대한 결과들은 canonical(규범적인) 예측 단위(주로 character, byte, word 등) 당 average negative log probability(maximum likelihood estimation에서 언급되는 손실함수를 의미하는 듯함, 크로스 엔트로피?)의 scaled version 혹은 exponentiated version(지수를 사용함)으로 보고된다. 연구팀은 WebText LM에 따라서 데이터셋의 로그확률을 계산하고 이를 canonical unit의 개수로 나누어서 동일한 양을 평가하게 된다. 이 데이터셋들 중 상당수에 대해, WebText LM들은 상당한 out-of-distribution에서 테스트될 것이며, 표준화된 text를 공격적으로 예측해야 하며, 연결이 끊어진 문장 부호 및 축약과 같은 tokenization artifact, 뒤섞인 문장들, 그리고 심지어는 WebText에서 매우 희귀한 <UNK> 토큰(400억 바이트 중 26번만 등장함)을 예측해야 한다. 연구팀은 주요 결과를 Table 3에서 보고하고 있다.

여기서 가역적인 de-tokenizer(tokenization의 역방향, 원래 단어로 만들어줌)를 사용하는데, 가능한 많은 tokenization artifact와 pre-processing artifact를 제거한다. 이 de-tokenizer들은 가역적이여서, 여전히 데이터셋의 로그 확률을 계산할 수 있고, de-tokenizer들은 domain adaptation의 간단한 형태로 생각될 수 있다. 이 de-tokenizer들로 GPT-2로 2.5~5의 perplexity를 달성한다.
WebText LM들은 domain과 dataset들 사이를 잘 transfer하며, zero-shot setting에서 8개의 dataset 중 7개에서 state-of-the-art를 향상시켰다. Penn Treebank와 WikiText-2처럼 훈련 token이 100만~200만밖에 안되는 작은 데이터셋에 대해서 커다란 성능 향상을 이루었다. 또한 long-term dependencies를 측정하기 위해 만들어진 LAMBADA 데이터셋 및 Children’s Book Test에서도 커다란 성능 향상을 이루었다. 그러나, GPT-2는 여전히 One Billion Word Benchmark(1BW)에서는 성능이 크게 떨어졌다. 이는 아마 가장 큰 데이터셋인 동시에 가장 파괴적인 pre-processing(sentence-level shuffling으로 인해 모든 long-range structure를 제거해버린다)의 조합 때문일 것이다.
3.2 Children’s Book Test
The Children’s Book Test (CBT)는 LM들의 단어의 다른 카테고리들에 대한 성능을 평가하기 위해 만들어졌으며, named entities, verbs, nouns, prepositions가 있다. 평가 metric으로 perplexity를 사용하는 것 보다는, CBT에서는 자동적으로 만들어진 cloze test에서의 정확도를 평가 metric으로 사용한다. 여기서 cloze test는 빈칸이 뚫린 단어에 대해 10개의 가능한 선택지가 나오면, 이 중 올바른 것을 예측하는 test이다. Original 논문에서 나왔던 LM 접근법을 따르면서, 연구팀은 각 선택지의 확률과, 이 선택에 따른 나머지 문장의 확률을 계산하고, 이 중 가장 높은 확률을 예측한다. Figure 2에서 보다시피, 모델 사이즈가 커질수록 성능이 서서히 증가하며, 이 테스트에서 인간의 지능과의 엄청났던 격차를 좁히게 되었다.

데이터 overlap 분석 결과, CBT의 test set 책들 중 하나인 The Jungle Book by Rudyard Kipling은 훈련 데이터인 WebText 안에 있던 책이므로, 결과는 큰 오버랩이 없는 validation set에 대한 결과로 보고한다. GPT-2는 common nouns에 대해서는 새로운 state-of-the-art인 93.3%를 달성하며, named entities에 대해서는 89.1%를 달성한다. De-tokenizer는 CBT로부터 PTB(Penn Tree Bank의 tokenizer를 의미하는 듯함) 스타일의 tokenization artifact를 제거하기 위해 적용되었다.
3.3 LAMBADA
LAMBADA 데이터셋은 text에서 long-range dependencies를 모델링하는 system의 능력을 테스트한다. 이 task는 문장들의 마지막 단어를 예측하는 것으로, 이 문장은 인간이 성공적으로 예측하기 위해 적어도 50개의 context token이 필요한 문장이다. GPT-2는 state-of-the-art로 99.8에서 8.6의 perplexity로 달성하였고 이 테스트에서 LM의 정확도는 19%에서 52.66%로 향상시켰다. GPT-2의 error를 조사해보면, 대부분은 문장의 유효한 연속된 부분을 예측하였지만, 유효한 마지막 단어는 아니였다. 이는 LM이 문장의 마지막이 반드시 단어여야 한다는 가정을 사용하지 않는다는 것을 의미한다. Stop-word 필터를 추가함으로써 정확도가 63.24%까지 향상되었고, 이 task에서 전반적인 state-of-the-art를 4%가량 향상시켰다. 이전 state-of-the-art는 다른 제한된 예측 setting을 사용하였는데, 모델의 output들이 context에 등장하는 단어 들에만 국한되었다. GPT-2에게는, 이러한 제한이 도움이 되기보다는 오히려 성능에 해가 된다. 왜냐하면 정답의 19%는 context에 있던 것이 아니였다. 연구팀에서는 데이터셋으로 preprocessing없는 version을 사용한다.
3.4 Winograd Schema Challenge
Winograd Schema challenge는 commonsense reasoning을 수행하는 system의 능력을 측정하기 위해 제작되었으며, text 내의 애매모호함을 해결하는 능력을 측정한다. 최근에는 Trinh & Le (2018)에서 이 challenge에 대해 꽤 커다란 진전이 있었는데, 이는 LM을 사용하여 애매모호함의 해결을 보다 높은 확률로 예측함으로써 가능하였다. GPT-2 연구팀은 이들의 문제 공식화를 따랐고 Figure 3에서 GPT-2 모델들의 성능을 시각화하였다. GPT-2는 state-of-the-art 정확도를 7% 상승시켜 70.70%를 달성한다. 데이터셋은 꽤 작으며, 273개의 example만 존재한다.

3.5 Reading Comprehension
The Conversation Question Answering dataset (CoQA)는 document에 대해 질의자와 응답자 사이의 자연어 대화가 쌍으로 묶인 7개의 다른 domain들의 document들로 구성된다. CoQA는 독해 능력을 테스트하며 또한 대화 history에 의존하는 질문에 대답하는 능력을 평가한다.
Document, 관련 대화의 history, 최종 토큰 A가 주어진 상황에서 GPT-2로부터의 greedy decoding을 한 결과, validation set에서 55 F1 score를 달성한다. 이는 baseline system 4개 중 3개의 성능을 따라가거나 넘어섰으며, 이 baseline들을 훈련하는데에 사용된 127,000개 이상의 QA pair들을 사용하지 않고 달성한 결과이다. Supervised SOTA인 BERT 기반의 system은 인간의 F1 성능인 89에 근접한다. 반면 GPT-2의 성능은 supervised training이 없는 system에서는 매우 흥미롭지만, 그 answer와 error를 일부 점검한 결과, GPT-2는 종종 단순 검색 기반의 휴리스틱을 사용한다는 것을 확인했다.
3.6 Summarization
연구팀은 CNN 및 Daily Mail 데이터셋으로 GPT-2가 summarization task를 수행하는 능력을 테스트한다. Summarization 행동을 이끌어내기 위해 연구팀에서는 TL; DR: text를 기사뒤에 붙인다. 그리고 반복을 줄이고 greedy decoding보다 더 추상적인 요약을 장려하기 위해서 k = 2의 Top-k random sampling을 사용하여 100개의 token을 생성한다. 여기서 이 100개의 토큰 내의 처음으로 생성된 3개의 문장을 요약으로 사용한다. 질적으로는 이 생성된 문장들이 요약과 유사하지만, 주로 기사 내의 최근의 내용물에 집중하거나 구체적인 세부 사항은 헷갈려 하는 것을 볼 수 있다. 예를 들어, 충돌 사고에 얼마나 많은 차가 포함되었는지, 로고가 모자였는지 셔츠였는지 등 말이다. 공용적으로 사용되는 metric인 ROUGE 1, 2, L에서, 생성된 요약들이 겨우 classic한 신경망 baseline들의 성능에 접근하기 시작했고, 기사에서 랜덤하게 선택된 3개 문장과 비교하여 아주아주 약간 성능을 이기는 선에 그친다. GPT-2의 성능은 task에 대한 hint가 사라지면 6.4 포인트 정도 하락하며, 이는 hint가 language model에서 task specific한 행동을 이끌기 위한 능력임을 증명한다.
3.7 Translation
연구팀은 GPT-2가 번역하는 것을 학습하는 지를 테스트한다. 모델이 번역 task임을 추론하는 것을 돕기 위해서, 연구팀은 language model의 example 쌍들의 형태를 “english sentence = French sentence” 형태로 하고 English sentence = 뒤에 나오는 문장은 greedy decoding과 함께 모델에서 샘플링하여 처음으로 생성된 문장을 translation으로 사용한다. WMT-14 English-French test set에서는, GPT-2는 5 BLEU score를 달성하며, 이전 연구에서의 성능보다 떨어지게 나온다. WMT-14 French-English test set에서는, GPT-2는 GPT-2의 매우 강력한 영어 language model을 끌어내어 더 잘 수행할 수 있으며, 11.5 BLEU score를 달성한다. 이는 여러 unsupervised machine translation들의 성능을 압도하지만, 여전히 현재 가장 좋은 unsupervised machine translation 접근법의 33.5 BLEU 보다는 크게 밀린다. 이 task에 대한 성능은 놀라웠다, 왜냐하면 filtering 단계에서 WebText의 영어가 아닌 웹페이지들을 제거했기 때문이다. 이를 확인하기 위해, WebText에 대해 byte-level languade detector를 구동하였는데, 이 detector는 이전의 unsupervised machine translation 연구에서 공통적으로 사용된 프랑스어 단일 corpus보다 500배 적은 10MB의 프랑스어 데이터만을 발견하였다.
3.8 Question Answering
Language model 내에 어떤 정보가 있는지 테스트하는 잠재성 있는 방법은 factoid-style question(명사나 phrase 간단한 동사 같은 짧은 answer를 가지는 question들)에 대해 얼마나 자주 올바른 answer를 생성하는 지 평가하는 것이다. 모든 정보가 parameter에 저장되는 neural system(예를 들어 A Neural Conversational Model) 내의 이 행동에 대한 이전 연구에서는 고품질의 평가 데이터셋의 부재로 인한 질적인 결과를 보고했다. 최근에 소개된 Natural Questions 데이터셋은 더 정량적으로 테스트하기 좋은 자원이다. Translation과 비슷하게, language model의 context는 예시 QA pair들로 주어지며, 이는 모델이 데이터셋의 짧은 answer style을 더 잘 추론하도록 돕는다. GPT-2는 SQUAD와 같은 reading comprehension 데이터셋 들에서 일반적으로 사용되는 exact match metric으로 평가했을 때, 4.1%의 질문에 올바르게 대답한다. 비교할 점으로, 가장 작은 모델은 가장 공통적인 대답을 내놓는 매우 간단한 baseline의 정확도의 1.0% 정도밖에 넘지 못한다. GPT-2는 5.3배 더 잘 대답하며, 이는 모델의 capacity가 이러한 task의 neural system의 저열한 성능의 주요 원인이라는 것을 시사한다. GPT-2가 생성된 answer에 부여하는 확률은 잘 보정되고 GPT-2가 가장 자신 있어하는 1%의 질문에 대해 63.1%의 정확도를 가진다. Validation set에서 GPT-2에 의해 생성된 가장 자신 있어하는 30개의 answer는 Table 5에 나타나있다.

GPT-2의 성능은 여전히 30~50% 정도의 open domain question answering system(extractive document question answering과 information retrieval을 같이 쓰는)의 성능들보다 훨씬 훨씬 더 밀린다.
4 Generalization vs Memorization
Computer vision에서의 최근의 연구에서는 공용의 이미지 데이터셋이 중복에 가까운 이미지들을 다수 가지고 있다는 것을 보였다. 예를 들어서, CIFAR-10은 train과 test 이미지 간에 3.3% 정도가 겹친다. 이로 인해 머신 러닝 system에서의 일반화 성능을 과대평가하는 결과로 이어지게 된다. 데이터셋의 사이즈가 증가함에 따라 이 문제가 발생할 확률이 높아지며, 이는 WebText에서도 유사한 현상이 발생할 수 있음을 시사한다. 그러므로, test data가 얼마나 많이 training data에도 나타나는 지를 분석하는 것이 중요하다.
이를 연구하기 위해서, GPT-2 연구팀에서는 WebText training set token의 8-gram들을 포함하는 Bloom filter(특정 원소가 집합 내에 존재하는지를 확인하는 확률적 자료구조, 정확도가 100% 보장되는 것이 아님)를 만들었다. Recall(재현율, TP / (TP + FN))을 높이기 위해서, string들은 delimiter로써 단일 공간에 오직 소문자 알파벳들만 포함되도록 정규화되었다. Bloom filter들은 false positive rate가 최대 1 / 10^8이 되도록 제작되었다. 여기에 더해 필터에 의해 0이 검출된 1M string을 생성함으로써, 낮은 false positive rate를 검증하였다.
이 Bloom filter들은 데이터셋이 주어지면 WebText training set에서도 또한 발견되는 8-gram의 퍼센티지를 계산할 수 있게 해준다. Table 6에서는 common LM benchmark들의 test set들의 overlap analysis에 대한 결과를 보여준다.
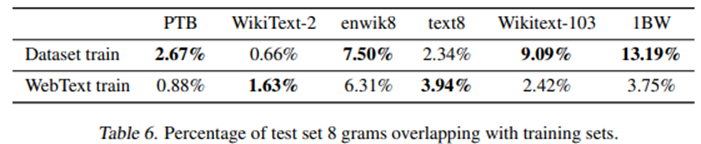
Common LM 데이터셋의 test set들은 WebText train과 1~6% 정도의 overlap을 가지며, 평균 overlap은 3.2%이다. 의외로 많은 데이터셋들이 그들 자체의 training set과 더 큰 overlap을 가지며, 평균 5.9%의 overlap이 있다.
GPT-2의 접근법에서는 recall을 최적화하며, manual하게 overlap들을 점검한 결과에는 많은 common phrase들이 있다는 것이 확인되고, 중복된 데이터로 인한 긴 match들이 있다. 이는 WebText에만 국한된 것은 아니다. 예를 들어, WikiText-103의 test set 역시 training set에 있는 기사가 포함된 것을 발견하였다. Test set에는 60개의 기사만 있는데, 이 중 최소 1.6%는 overlap이 있다. 잠재적으로 더 걱정스러운 것은, 1BW는 거의 13.2% 정도의 overlap이 있다.
Winograd Schema Challenge에서는, WebText training set과 8-gram이 overlap되는 schemata는 10개밖에 없었다. 이 중에 2개는 가짜 match였다. (실제는 8개인 것임) 남은 8개 중, 답을 제공한 context에 등장한 schema는 오직 1개 뿐이였다.
CoQA에서는, news domain의 약 15%의 documnet들이 이미 WebText에 있고 이에 대해 모델에서 약 3 F1 score정도가 더 잘 나왔다. CoQA의 validation set의 metric은 5개의 다른 domain 간의 평균 성능을 보고하고, 연구팀에서는 다양한 도메인에서의 overlap으로 인해 0.5~1 정도의 F1을 얻었다. 그러나, WebText에는 실제 training question이나 answer가 없으며, 이는 CoQA가 WebText 내의 링크들의 cutoff date 이후에 공개되었기 때문이다.
LAMBADA에서는, 평균 overlap이 1.2%이다. GPT-2는 overlap이 15%를 훨씬 넘는 example들에서 약 2 perplexity 정도가 더 잘 나왔다. 약간의 overlap이라도 있는 모든 example들을 제외한 후에 metric을 다시 계산한 결과 perplexity가 8.6에서 8.7이 되었고, 정확도는 63.2%에서 62.9%로 감소하였다. 전반적인 결과에서 매우 작은 변화가 일어난 이유는, 큰 overlap은 겨우 200개의 example 중 1개 꼴이였기 때문이다.
전반적으로, 연구팀의 분석은 WebText training data와 특정한 evaluation dataset 사이의 overlap이 작지만 꾸준하게 보고된 성능에 가산점을 주었다는 것을 시사한다. 그러나, Table 6에서 강조하듯이, 대부분의 데이터셋들은 training set과 test set 사이의 이미 존재하는 overlap보다 더 큰 overlap은 발견할 수 없다.
얼마나 매우 비슷한 text들이 성능에 영향을 주는지를 이해하고 수량화하는 것은 매우 중요한 research question이다. 더 좋은 중복 제거 테크닉들(scalable fuzzy matching같은)은 또한 이러한 question에 잘 대응할 수 있게 도와준다. 현재, GPT-2 연구팀은 n-gram 사용 기반의 중복 제거를 새로운 NLP 데이터셋에 대해 training과 test set으로 분리할 때의 중요한 검증 단계 및 sanity check(전성 검사, 데이터가 올바른지 체크 하는 검사)로써 사용하길 추천한다.
WebText LM의 성능이 memorization으로 인한 것인지를 판단하는 또다른 잠재성 있는 방법은 그들 자체의 held-out set으로 평가하는 것이다. Figure 4에서 보다시피, WebText의 training set과 test set 둘 다에서의 성능이 비슷하고, 모델 size가 증가할수록 함께 증가한다. 이는 GPT-2가 여전히 많은 부분에서 WebText에 대해 underfitting하다는 것을 시사한다.

5 Related Work
d
6 Discussion
많은 연구들은 supervised 및 unsupervised pre-training 방법들의 representation들에 대한 학습, 이해, 비판적인 평가에 대해 전념해왔다. GPT-2 연구팀의 결과는 unsupervised task learning이 연구해볼만한 유망한 분야라는 것을 시사한다. 이러한 발견들은 잠재적으로 down-stream NLP task들을 위한 pre-training 테크닉들의 널리 퍼진 성공을 설명하는 데에 도움을 줄 것이다. 보였다시피, 이 pre-training 테크닉들 중 하나는 supervised한 adaptation, modification없이 task 수행을 직접적으로 학습하기 시작한다.
Reading comprehension에서의 GPT-2의 성능은 zero-shot setting에서는 supervised baseline들과 견줄만 하다. 그러나, summarization과 같이 다른 task들에 대해서는, 품질 좋게 task를 잘 수행하고 있지만, 성능은 여전히 기초 수준에 머무른다. 연구 결과로는 시사적이지만, 실용적인 측면에 있어서는, GPT-2의 zero-shot 성능은 여전히 실제 사용과는 거리가 있다.
이번 연구팀은 많은 규범적인 NLP task들에 대해 WebText LM들의 zero-shot 성능에 대해 연구해왔지만, 평가될 수 있는 많은 부가적인 task들이 있다. 의심할 여지 없이 GPT-2가 그냥 랜덤 성능과 별반 다를게 없는 많은 실용적인 task들이 존재한다. 심지어는 평가한 것 중에서 공통적인 task들인 question answering이나 translation과 같은 것들에 대해서도, language model들은 그저 trivial한 baseline들만 압도하기 시작했을 뿐이다.
비록 zero-shot 성능이 많은 task들에 대해서 GPT-2의 잠재적인 성능의 baseline을 제시하지만, fine-tuning에 의한 상한선이 어디인지는 명확하지 않다. 일부 task들에서는, GPT-2의 완전히 추상적인 output은 현재 많은 question answering 및 reading comprehension 데이터셋에 대해 state-of-the-art인 extractive pointer network와는 크게 떨어진 상황이다. GPT를 fine-tuning하여 이전에 성공한 사례에 힘입어, 연구팀에서는 decaNLP와 GLUE같은 benchmark들에 대해 fine-tuning하는 것을 조사할 계획을 하고 있으며, 특히 이는 추가적인 training data와 GPT-2의 capacity가 BERT에 의해 증명된 unidirectional representation의 비효율성을 극복할 만큼 충분한지 명확하지 않기 때문이다.
7 Conclusion
거대한 language model이 충분히 크고 다양한 데이터셋으로 훈련받을 때, 이 모델은 많은 domain과 데이터셋에 대해 잘 수행할 능력이 있다. GPT-2는 zero-shot에서 테스트한 language modeling 데이터셋 8개 중 7개에서 state-of-the-art를 달성하였다. GPT-2가 zero-shot setting에서 수행할 수 있는 task들의 다양성은, 충분히 다양한 text corpus의 likelihood를 최대화시키기 위해 훈련된 high-capacity를 가진 모델들이 명확한 supervision의 필요없이 놀라운 양의 task들을 수행하는 방법을 학습하기 시작했다는 것을 시사한다.