2022. 3. 10. 22:23ㆍNaver BoostCamp AI Tech 3기
Abstract
Natural language understanding(NLU, 자연어 이해, 컴퓨터가 사용자의 실제 의미를 추론함)은 textual entailment(두 문장이 주어졌을 때, 첫 번째 문장이 두 번째 문장을 수반하는가 혹은 위배되는가?), question answering(질의 응답), semantic similarity assessment(문서, 용어 사이의 유사성을 평가함), document classification(문서 분류, 문서에 레이블을 할당하는 것임)등의 다양하고 넓은 범위의 task들로 이루어진다. 비록 거대한 unlabeled text corpora들이 방대하게 존재하지만, 이 구체적인 task들을 학습하기 위한 labeled data는 부족하며, 이로 인해 구분되어서 훈련된 모델들이 적절한 성능을 내보이는 것이 어려워진다. 이번 연구팀에서는 이러한 task들에서의 많은 gain들이 unlabeled text의 다양한 corpus로 언어 모델을 generative pre-training하고, 그 후 각각의 구체적인 task에 대해 discriminative한 fine-tuning을 함으로써 얻어질 수 있다는 것을 증명한다. 이전의 접근법들과는 다르게, 연구팀에서는 model architecture의 변화는 최소한으로 요구하면서, 효율적인 transfer를 달성하기 위한 fine-tuning 동안에 task-aware input transformation을 이용하게 된다. 연구팀에서는 이 접근법이 NLU의 넓은 범위에 benchmark들에 대해 효율적이다는 것을 증명한다. 여기서 나오는 일반적인 task-agnostic(어떤 task가 올지 알 수 없다는 의미로 쓰인 듯 하다. Pre-training 부분을 의미하는 듯함)한 model은 각각의 task에 대해 구체적으로 만들어진 아키텍처를 사용하는 개별적으로 훈련된 모델들의 성능을 압도하며, 이 중 연구된 12개의 task 중 9개에서는 state-of-the-art를 달성할 정도이다. 예를 들어, 연구팀에서는 commonsense reasoning(상식 추론, 인간이 매일 마주치는 일상적인 상황의 유형과 본질에 대해 추정하는 인간과 같은 능력)(Stories Cloze Test)에서 8.9% 만큼의 상승과, question answering(RACE)에서는 5.7%, 그리고 textual entailment(MultiNLI)에서는 1.5% 만큼의 상승을 달성하였다.
1 Introduction
Raw text로부터 효율적으로 학습하는 능력은 NLP에서 supervised learning에 대한 의존도를 완화시키는 데에 매우 중요하다. 대부분의 딥러닝 방법들은 많은 양의 manually하게 labeled된 data가 요구되며, 이는 annotated된 resource의 부족으로 고통받는 많은 domain들에서의 그들의 적용성을 제한하는 결과로 이어진다. 이러한 상황에서, unlabeled data로부터 언어적인 정보를 끌어낼 수 있는 model들은 더 많은 annotation을 모으는 것(아마 시간이 더 오래 걸리고, 비용도 많이 들)에 대한 귀중한 대안책이 된다. 게다가, 많은 supervision이 가능한 상황(annotated data가 많은 그런 상황)에서도, unsupervised한 fashion(방식)으로 좋은 representation을 학습하는 것은 커다란 성능 향상을 제공할 수 있다. 이에 대한 가장 설득력 있는 증거는 NLP task들의 성능을 올리기 위해 pre-trained word embedding들을 광범위하게 사용한 예시들이 있다.
그러나, unlabeled text로부터 word-level의 정보 이상의 것을 끌어내는 것은 2가지 주요 이유로 어렵다. 첫번째, transfer에 유용한 text representation을 학습하는 데에 어떤 종류의 최적화 objective들이 제일 효율적인 지가 불명확하다. 최근의 연구에서는 language modeling, machine translation, discourse coherence(담화 응집성, 문장들이 어떻게 연결되어 있는지에 대한 것)와 같은 다양한 objective들이 다른 task들에서 나머지 다른 방법들을 성능에서 압도하는 것을 봐왔다. 두 번째로, 학습된 representation들을 target task로 transfer하는 가장 효율적인 방법에 대해 통일된 것이 없다. 기존 테크닉들은 복잡한 learning scheme을 사용하고 보조적인 learning objective들을 추가하여 모델 아키텍처에 task-specific한 변화를 가하는 것을 포함한다. 이 불확실성들은 언어 처리에 대해 효율적인 semi-supervised learning 접근법을 개발하는 것을 어렵게 하였다.
이 논문에서는, 연구팀은 unsupervised pre-training과 supervised fine-tuning의 조합을 사용하여 language understanding task들에 대해 semi-supervised한 접근법을 탐색한다. 연구팀의 목표는 광범위한 task들로 매우 적은 adaptation으로 transfer를 할 수 있는 universal한 representation을 학습하는 것이다. 연구팀은 unlabeled text의 거대한 corpus와 manually하게 annotated된 training example들이 있는 여러 데이터셋(target tasks)에 대해 접근한다고 가정한다. 이 준비과정은 unlabeled corpus와 target task들이 같은 domain에 있을 것을 요구하지는 않는다. 2-stage 훈련 과정을 이용한다. 먼저, 신경망 model의 초기 파라미터들을 학습하기 위해 unlabeled data에 대해 language modeling objective를 사용한다. 그 후에는, 이 파라미터들을 target task(일치하는 supervised objective를 사용하여서)로 적용시킨다.
연구팀의 모델 아키텍처를 위해서, machine translation, documentation generation, syntactic parsing(공식적인 문법들로 자연어를 분석하는 과정) 등 여러 task에서 성능이 좋았던 Transformer를 사용한다. 이 모델을 선택함으로써 RNN등과 비교하여 text에서 long-term dependencies를 처리하기 위하여 더 구조화된 memory를 제공하며, 결과적으로 다양한 task들에서 robust한 transfer 성능을 보여준다. Transfer 동안에, 연구팀에서는 traversal-style의 접근법으로부터 나온 task-specific한 input adaptation을 사용하고, 이는 구조화된 text input을 하나의 단일 연속적인 token들의 sequence로 처리한다. 연구팀이 실험에서 증명하듯이, 이러한 adaptation들이 pre-trained model의 아키텍처에 최소한의 변화를 주어 효율적으로 fine-tune 하는 것을 가능하게 한다.
연구팀에서는 그들의 접근 방법을 4가지 종류의 language understanding task로 평가한다. Natural language inference(NLI, 자연어 추론, 모델의 추론 능력을 평가하는 작업으로, 두 문장 사이의 의미관계를 함의, 모순, 중립으로 분류하는 sentence-pair classification의 일종임), question answering, semantic similarity, text classification이 있다. 연구팀의 일반화된 task-agnostic model은 각 task에 대해 개별적으로 만들어진 아키텍처를 이용하는 model들의 성능을 압도한다.
2 Related Work
Semi-supervised learning for NLP
연구팀의 연구는 자연어에 대한 semi-supervised learning의 범주에 폭넓게 포함된다. 이 패러다임(semi-supervised)은 커다란 흥미를 이끌었고, sequence labeling(x1, x2, x3, …의 입력 시퀀스에 대해 y1, y2, y3, … 처럼 레이블을 각각 부여하는 작업임. 대표적으로 tagging 작업이 있음)이나 text classification과 같은 task들에 적용되었다. 가장 초기의 접근법들은 word-level 또는 phrase-level의 statistics를 계산하기 위하여 unlabeled data를 사용하였고, 그 후 이 statistics들이 supervised model의 feature들로 사용되었다. 지난 몇 년 동안, 연구자들은 word embedding을 사용하는 것의 장점을 증명해왔고, 이 embedding들은 unlabeled corpora에서 훈련되며, 다양한 task들에 대해 성능을 향상시키기 위함이다. 그러나, 이러한 접근법들은 주로 word-level의 정보를 transfer하며, 반면에 연구팀에서는 이보다 더 높은 higher-level의 semantic을 잡아내는 것에 초점을 둔다.
Unsupervised pre-training
Unsupervised pre-training은 semi-supervised learning의 특별한 케이스로, 목표는 supervised learning의 objective를 변경하는 것 대신에 좋은 initialization point를 찾는 것이 목표이다. 초기의 연구들에서는 image classification과 regression task들에서의 테크닉의 사용을 탐색하였다. 후의 연구는 pre-training이 regularization scheme(deep neural network에서 일반화 성능을 더 좋게 할 수 있음)처럼 동작한다는 것을 증명하였다. 최근의 연구에서는, 이 방법이 image classification, speech recognition, entity disambiguation, machine translation과 같은 다양한 task들에서 deep neural network들을 훈련시키는 데에 도움을 주기 위해 사용되었다.
연구팀의 연구와 가장 가까운 부류의 연구에서는 language modeling objective를 사용하는 neural network를 pre-training하는 것과 그 후에는 supervision으로 target task를 fine-tune하는 것을 포함한다. Dai et al., Howard, Ruder는 text classification의 성능을 높이기 위해 이 방법을 따른다. 그러나, 비록 pre-training 단계가 몇몇 언어적인 정보를 capture하는 것을 도와주지만, 여기서 LSTM model들을 사용하는 것은 이들의 예측 능력을 짧은 범위로 제한하게 된다. 이와 대조적으로, 연구팀에서 선택한 transformer network들은 더 긴 범위의 언어적인 구조를 capture하는 것을 가능하게 한다. 게다가, 연구팀에서는 또한 natural language inference, paraphrase detection, story completion을 포함하여 더 넓은 범위의 task들에 대한 연구팀의 model의 효율성을 증명해낸다. 다른 접근법들에서는 pre-trained language model 혹은 pre-trained machine translation model로부터 나온 hidden representation들을 target task의 supervised model 훈련 동안의 보조적인 feature로 사용하게 된다. 이것은 각 분리된 target task에 대해 상당한 양의 새로운 파라미터들을 포함하며, 반면에 연구팀은 transfer 동안에 모델 아키텍처에 최소한의 변화만을 요구하게 된다.
Auxiliary training objectives
보조적인 unsupervised training objective들을 추가하는 것은 semi-supervised learning의 대안책이다. Collobert와 Weston의 초기 연구에서는 semantic role labeling(의미역 결정, 문장 내에 포함된 서술어와 해당 서술어의 수식을 받는 논항간의 의미관계를 결정함) 성능을 높이기 위해서 다양한 보조적인 NLP task인 POS tagging, chunking, named entity recognition, language modeling 등을 사용하였다. 더 최근에 들어서, Rei는 target task objective에다가 보조적인 language modeling objective를 추가하였고, sequence labeling task에 대해 performance gain을 증명하였다. 연구팀의 실험에서도 또한 보조적인 objective를 사용하지만, 이전에 보였다시피, unsupervised pre-training에서 이미 target task들과 관련된 언어적인 측면들을 학습하게 된다.
3 Framework
훈련 과정은 2개의 stage로 구성된다. 첫 번째 stage는 text의 거대한 corpus를 이용하여 high-capacity를 가진 language model을 학습하는 것이다. 이 다음에는 fine-tuning stage로 이어지는데, 여기서는 이 pre-trained 모델을 labeled data를 사용하여 discriminative task들에 적용시킨다.
3.1 Unsupervised pre-training
Token {u1, …, un}에 대한 unsupervised corpus가 주어졌을 때, 다음 likelihood를 최대화하기 위해서 표준적인 language modeling objective를 사용한다.
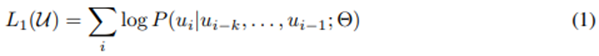
여기서 k는 context window의 크기이며, 조건부확률 P는 파라미터들인 θ와 함께 신경망을 사용하여 모델링된다. 이 파라미터들은 stochastic gradient descent를 사용하여 훈련된다.
연구팀의 실험에서는, language model을 위해 multi-layer Transformer decoder를 사용하고, 이는 transformer의 변형이다. 이 모델은 input context token들에 대해 multi-headed self-attention 연산을 적용하고, 그 후에는 position-wise feedforward layer들을 사용하여 target token에 대한 output distribution을 생성해낸다.
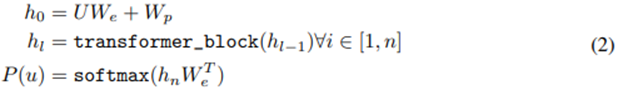
여기서 U(u_-k, …, u_-1)은 token들의 context vector이고, n은 layer의 개수이며, W_e는 token embedding matrix이고, W_p는 position embedding matrix이다.
3.2 Supervised fine-tuning
Eq.1의 objective로 model을 훈련한 후에, supervised target task에 파라미터들을 adapt한다. Labeled dataset C(각 instance는 input token의 sequence x1, …, xm 및 label y로 구성됨)를 가정하자. input들이 pre-trained model에 통과되어 마지막 transformer block의 activation인 h^m_l이 나오게 되고, 이것은 y를 예측하기 위해 파라미터들인 W_y와 함께 추가된 linear output layer로 들어가게 된다.

이 식은 다음과 같은 최대화 시켜야 할 objective를 제공한다.

추가적으로 fine-tuning에게 보조적인 objective로 language modeling을 포함하는 것이 (a) supervised model의 일반화 성능을 높이고, (b) 수렴을 가속화 함으로써 학습을 돕는다는 것을 발견하였다. 구체적으로는, 다음과 같은 objective를 최적화 시키게 된다. (가중치는 λ)

전반적으로, fine-tuning 동안 요구하는 추가적인 파라미터는 W_y와 delimiter token에 대한 embedding들 뿐이다. (Section 3.3에서 묘사)
3.3 Task-specific input transformations
Text classification과 같은 몇몇 task들에 대해서는, 위에서 묘사된 것처럼 model을 직접적으로 fine-tune할 수 있다. Question answering 또는 textual entailment와 같은 특정 다른 task들은, 정렬된 문장 쌍, 또는 document, question, answer의 triplet(3개의 쌍이라 생각하면 될 것같음)과 같은 구조화된 input을 가진다. Pre-trained 모델이 text의 연속적인 sequence들로 훈련되었기 때문에, 이러한 task들에 적용하기 위해서는 약간의 변화가 요구된다. 이전의 연구에서는 transfer된 representation들의 맨 위의 task specific한 아키텍처들을 학습할 것을 제안하였다. 이런 접근법은 다시 task-specific한 customization을 상당수 도입해야 하며, 이러한 추가적인 아키텍처 구성요소들에 대해서는 transfer learning을 사용하지 않는다. 대신에, 연구팀에서는 traversal-style의 접근법을 사용하며, 여기서는 구조화된 input들을 pre-trained model이 처리할 수 있는 정렬된 sequence로 변환하게 된다. 이러한 input transformation들의 간략한 설명을 밑에서 보여주고, Figure 1에서는 시각화 하였다. 모든 transformation은 랜덤하게 초기화된 start token과 end token인 <s>, <e>를 포함한다.

Textual entailment
Entailment task들에 대해서는, premise p와 hypothesis h token sequence들을 결합한다. 이때 사이에 delimiter token인 ($)를 넣는다.
Similarity
Similarity task들에 대해서는, 비교되는 2개의 문장들의 고유의 순서가 없다. 이를 반영하기 위해서, input sequence가 가능한 문장 순서 2개를 모두 포함하도록 바꾸며(delimiter를 사이에 넣음) 각각을 독립적으로 처리하여 2개의 sequence representation인 h^m_l을 만든다. 이 2개의 representation은 linear output layer에 들어가기 전에 element-wise로 더해진다.
Question Answering and Commonsense Reasoning
이 task들에 대해서는, context document z, question q, 가능한 answer들의 집합 a_k가 주어진다. 각각의 가능한 answer에 대해서 document context와 question을 결합하고, delimiter token을 추가한다. 각 sequence들은 모델을 통해 독립적으로 처리되고, softmax layer를 통해 가능한 answer들에 대한 output distribution을 만들기 위해 정규화된다.
4 Experiments
4.1 Setup
Unsupervised pre-training
Language model을 훈련시키기 위해 BooksCorpus dataset을 사용한다. 이 데이터셋은 Adventure, Fantasy, Romance를 포함한 여러 장르의 출판되지 않은 7000개의 책들을 포함한다. 결정적으로, 길고 연속적인 text를 포함하며, 이를 통해 generative model이 장거리 정보를 조건화 하는 것을 배울 수 있다. 다른 대안 데이터셋으로, 1B Word Benchmark(ELMo와 비슷한 접근법에서 사용됨)는 비슷한 크기의 데이터셋이지만, sentence level에서 섞이게 되며, 이는 장거리의 구조를 파괴한다. 연구팀의 language model은 이 corpus에 대해서는 매우 낮은 token level perplexity인 18.4를 달성한다.
Model specifications
연구팀의 모델은 original transformer 연구를 따른다. 연구팀에서는 masked self-attention head(768차원의 state, attention head는 12개)와 함께 12-layer의 decoder-only transformer를 훈련시켰다. Position-wise feed-forward network를 위해서, 3072차원(768 x 4)의 inner state를 사용하였다. Adam optimization을 사용하였고, 최대 학습률은 2.5e-4였다. 학습률은 0에서부터 첫 2000번의 update 동안은 선형적으로 증가하였고, cosine scheduling을 통해 후에는 0으로 수렴했다. 훈련은 64개의 랜덤하게 샘플링 된 mini-batch들(batch size = 64)로 100 epoch동안 훈련하며, sequence는 512 token이다. Layernorm이 모델 전체적으로 광범위하게 사용되므로, N(0, 0.02)의 단순한 가중치 초기화로 충분하였다. 연구팀에서는 40000번의 merge를 진행한 bytepair encoding(BPE, 서브워드 분리 알고리즘으로 기존의 단어를 분리하고 unigram으로 단어들을 merge하면서 subword가 들어간 vocabulary를 만들게 됨. OOV에 대처 가능) vocabulary를 사용하였고, regularization을 위해서 residual connection, embedding, 그리고 0.1 비율의 attention dropout을 사용하였다. 또한 L2 regularization의 변형된 version을 이용하였고, non bias 또는 gain weights에 대해서 w = 0.01이다.(??) activation function으로는 GELU를 사용하였다. Original 연구에서 제안된 sinusoidal version의 position embedding 대신 학습된 embedding을 사용하였다. BooksCorpus의 raw text를 정제하기 위해 ftfy 라이브러리를 사용하고, 몇몇 문장부호 및 whitespace는 표준화하고, spaCy 토크나이저를 사용한다.
Fine-tuning details
명시되지 않는다면, unsupervised pre-training에서의 hyperparameter 설정을 재사용한다. Classifier에 0.1의 비율의 dropout을 추가한다. 대부분의 task에서는, 학습률 6.25e-5에 batch size는 32로 사용한다. 연구팀의 모델은 빠르게 finetune되며 training에서 3 epoch 정도가 대부분의 경우에 충분했다. training에서 0.2% 이상의 training으로 linear learning rate decay schedule을 사용한다. Λ는 0.5로 설정되었다.
4.2 Supervised fine-tuning
연구팀에서는 natural language inference, question answering, semantic similarity, text classification을 포함한 다양한 supervised task들에 대한 실험을 수행한다. 이 task들 중 몇몇은 현재 released 되어 있는 GLUE multi-task benchmark의 부분으로 이용 가능하다. Figure 1에서는 모든 task와 dataset들에 대한 overview를 제공한다.

Natural Language Inference
NLI는 문장의 한 쌍을 읽고 이 문장의 관계가 entailment, contradiction, neutral 중 어디에 해당하는 지 관계를 판단하는 task이다. Table 2에서는 연구팀의 모델에 대한 다른 NLI task들의 다양한 결과를 상세히 보여주고 이전의 state-of-the-art 접근법들을 보여준다.

결과를 말하자면, 연구팀의 모델이 다른 기존 sota 모델들을 성능에서 압도하고, 복수의 문장에 대해 더 잘 추론하고 언어적인 애매모호함을 처리하는 능력이 있다고 보여진다.
Question answering and commonsense reasoning
단일 문장 혹은 복수 문장의 추론을 요구하는 또다른 task로는 question answering이 있다. Table 3에서 보다시피, 역시 연구팀의 모델이 이전의 최고 기록들을 압도한다. 이를 통해 연구팀의 모델이 장거리 범위의 context들을 효율적으로 처리하는 능력이 있다는 것을 증명한다.

Semantic Similarity
Semantic similarity (paraphrase detection) task는 2개의 문장이 의미적으로 동일한지 아닌지를 예측하는 것이 포함된다. Table 4에서 보다시피 3개의 semantic similarity task 중 2개에서 state-of-the-art 결과를 달성한다.

Classification
마지막으로, 2개의 다른 text classification task로도 평가한다. 결과를 살펴보면, CoLA에서는 이전 최고 기록을 압도하였고, 이는 모델이 innate linguistic bias를 잘 학습한다는 것을 보인다. SST2에서는 이전 SOTA와 겨루어 볼만한 결과가 나왔다. GLUE에서는 이전 최고 기록을 앞서는 결과를 보인다.
전반적으로, 연구팀의 접근법에서 12개의 데이터셋 중 9개에서 새로운 state-of-the-art를 달성하며, 많은 경우에서 앙상블 방법을 압도한다. 이 결과는 또한 다양한 사이즈의 데이터셋에 걸쳐 잘 동작한다는 것을 보이며, STS-B (5700개의 sample)에서 SNLI (55만개의 sample)까지 잘 동작하는 것이다.
5 Analysis
Impact of number of layers transferred
Unsupervised pre-training에서 supervised target task로의 transfer되는 layer의 개수의 영향력에 대해 관찰하였다. Figure 2에서는 transfer되는 layer의 숫자의 기능으로써 MultiNLI와 RACE에서의 연구팀의 방법의 성능을 묘사하고 있다.

연구팀에서는 embedding을 transfer하는 것이 성능을 향상시킨다는 표준적인 결과를 관찰하고 MultiNLI에서 full transfer에 대해서는 각 transformer layer 당 9%까지 향상을 제공한다는 것을 관찰한다. 이는 pre-trained model의 각 layer가 target task를 해결하기 위한 유용한 기능을 보유하고 있다는 것을 보인다.
Zero-shot Behaviors
연구팀에서는 어째서 Transformer의 language model pre-training이 효율적인지 더 잘 알고 싶어했다. 가설은 underlying generative model이 language modeling의 능력을 향상시키기 위해서 많은 task들을 수행하는 법을 학습하고, transformer의 더 구조화 된 attentional memory가 LSTM과 비교하여 transfer를 돕는다는 것이다. 연구팀은 supervised fine-tuning 없이 task들을 수행하는 underlying generative model을 사용하는 여러 개의 휴리스틱 solution들을 만들어 보았다. 이 휴리스틱 solution들의 효율성을 Fig 2 오른쪽에서 시각화한다. 연구팀은 훈련을 거듭하며 이 휴리스틱들의 성능이 안정적이고 꾸준하게 증가하는 것을 관찰하며 이는 generative pretraining이 다양한 task들과 관련된 기능들의 학습을 돕는다고 말할 수 있다. 또한 LSTM은 zero-shot 성능에서 더 높은 분산을 보인다는 것을 관찰하고, 이는 Transformer 아키텍처의 inductive bias가 transfer를 보조한다고 볼 수 있다.
6 Conclusion
연구팀에서는 generative pre-training과 discriminative fine-tuning을 통해 단일 task-agnostic model을 사용하여 강력한 natural language understanding을 달성하는 framework를 제시하였다. 길고 연속적인 text의 다양한 corpus로 pre-training을 함으로써 연구팀의 모델은 중요한 world knowledge와 장기적인 dependencies를 처리하는 능력을 습득한다. 이로써 이 모델은 question answering, semantic similarity assessment, entailment determination, text classification과 같은 discriminative task들을 해결하는 곳에 성공적으로 transfer 되며, 결과적으로 12개의 데이터셋 중 9개에서 state-of-the-art를 달성하여 성능을 향상시켰다. Discriminative task의 성능을 올리기 위하여 unsupervised (pre-)training을 사용하는 것은 머신 러닝 연구의 중요한 목표가 되었다. 이번 연구에서 제시하는 것은, 큰 성능 향상이 가능하며, 그에 대한 힌트로 어떤 모델(Transformers)과 데이터셋(장기 범위의 dependencies를 가지는 text)이 이 접근법과 가장 잘 맞는지를 보여준다. 연구팀에서는 이번 연구가 unsupervised learning으로의 새로운 연구들을 가능하게 하기를 희망하고, NLU와 다른 domain에서, 나아가서 unsupervised learning이 언제, 어떻게 동작하는지에 대한 이해를 향상시키기를 희망한다.
'Naver BoostCamp AI Tech 3기' 카테고리의 다른 글
| RoBERTa: A Robustly Optimized BERT Pretraining Approach (0) | 2022.03.24 |
|---|---|
| Language Models are Unsupervised Multitask Learners (0) | 2022.03.14 |
| Bag of Tricks for Image Classification with Convolutional Neural Networks (0) | 2022.02.22 |
| (Vision Transformer)AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (0) | 2022.02.19 |
| [코드리뷰]BERT (2) | 2022.02.15 |