2022. 2. 22. 20:30ㆍNaver BoostCamp AI Tech 3기
Abstract
Image classification 연구에서 이루어진 최근의 많은 진전들은 훈련 과정의 refinement(정제, 구체화, 여기서는 논문 제목의 trick과 의미가 비슷한 것 같음) 덕택이다. 예시로 data augmentation의 변화와 optimization 방법의 변화 등이 있다. 그러나, 문헌에서는 대부분의 refinement들은 implementation detail로 간략하게 언급되거나, source code 안에서만 볼 수 있다. 이번 논문에서는, 연구팀은 이러한 refinement들의 모음을 조사하고 ablation study를 통해 최종 모델 정확도에 대한 영향을 경험적으로 평가할 것이다. 연구팀에서는 이러한 refinement들을 결합함으로써, 다양한 CNN 모델들을 상당히 향상시킬 수 있다는 것을 보여줄 것이다. 예를 들어, 연구팀은 ResNet-50의 top-1 validation 정확도(ImageNet에 대한 정확도)를 75.3%에서 79.29%로 끌어올린다. 연구팀은 또한 이 image classification의 정확도의 향상이 object detection과 semantic segmentation과 같은 다른 application domain에서의 더 좋은 transfer learning 성능에 이른다는 것을 증명할 것이다.
1 Introduction
2012년 AlexNet의 소개 이후로, deep convolutional neural network는 image classification에 대한 지배적인 접근법이 되었다. 다양한 새로운 아키텍처들이 그 이후로 제안되었는데, VGG, NiN, Inception, ResNet, DenseNet, 그리고 NASNet 등을 포함하여 제안되었다. 동시에, 연구팀에서는 모델 정확도 향상의 꾸준한 트렌드를 봐왔다. 예를 들어, ImageNet에 대한 top-1 validation accuracy는 62.5%(AlexNet)에서 82.7%(NASNet-A)로 향상되었다.
그러나, 이러한 발전들은 향상된 모델 아키텍처에서만 왔던 것이 아니였다. Loss function, data preprocessing, optimization 방법의 변화들을 포함해서, 훈련 과정의 refinement들 또한 주요한 역할을 하였다. 이러한 매우 많은 refinement들은 과거 몇 년 동안 제안되어 왔지만, 비교적 관심을 덜 받았다. 문헌에서는, 대부분의 refinement들은 implement detail로 간단히 언급만 되거나, source code 안에서만 발견할 수 있었다.
이번 논문에서는, 연구팀은 모델의 정확도를 향상시킨(그러나 계산 복잡도는 거의 그대로인) 훈련 과정의 refinement와 모델 아키텍처의 refinement의 모음에 대해 조사할 것이다. 이 refinement들 중 상당수는 사소한 “trick”들이다. 특정 convolution layer의 stride size를 변화하거나 학습률 schedule을 조정하는 등이다. 그러나, 공동적으로, 이들은 큰 차이를 만들어낸다. 연구팀은 다수의 네트워크 아키텍처와 데이터셋으로 이 trick들을 평가할 것이고, 이들의 최종 모델에 대한 영향력을 보고할 것이다.
연구팀의 경험적인 평가는 여러 trick들이 상당한 정확도 향상으로 이어지고 이들을 함께 사용하면 모델 정확도가 폭발적으로 상승할 수 있다는 것을 보여준다. Table 1에는 모든 trick들을 적용한 후에 ResNet-50과, 다른 관련 있는 네트워크들을 비교한다. 주목해야 할 점은 이 trick들이 ResNet-50의 top-1 validation 정확도(ImageNet)를 75.3%에서 79.29%로 향상시킨다는 것이다. 또한 이 모델은 다른 새롭고 향상된 네트워크 아키텍처들(SE-ResNeXt-50과 같은)을 성능에서 압도한다. 게다가, 연구팀에서는 그들의 접근법이 다른 네트워크들과 데이터셋에 일반화될 수 있다는 것을 보여준다. 연구팀은 또한 그들의 기술로 훈련된 모델이 object detection과 semantic segmentation등과 같은 다른 application domain에서 더 나은 transfer learning 성능을 제공한다는 것을 보여준다.
Paper Outline.
연구팀에서는 먼저 Section 2에서는 baseline training procedure를 세우고, Section 3에서는 새로운 하드웨어로 효율적인 training을 위한 여러 trick들을 의논할 것이다. Section 4에서는 ResNet에 대한 사소한 수준의 모델 아키텍처의 3가지 변화를 살펴보고 새로운 trick 하나를 제안할 것이다. 그리고 나서는 Section 5에서는 4개의 추가적인 training procedure refinement를 의논할 것이다. 마지막으로, Section 6에서는 이 더욱 정확한 모델들이 transfer learning을 도와줄 수 있을 지에 대해 연구할 것이다.
연구팀의 모델 구현과 training script는 GluonCV에 공개되어 있다.
2 Training Procredures
Algorithm 1은 mini-batch stochastic gradient descent(SGD)로 신경망을 훈련하는 template을 보여주고 있다.

각 iteration에서, gradient를 계산하기 위해서 b개의 image를 랜덤하게 샘플링하고, 네트워크 파라미터들을 업데이트한다. 이 과정은 데이터셋을 K번 훑어본 후에 멈춘다. Algorithm 1의 모든 함수와 hyperparameter들은 많은 다른 방법들로 구현될 수 있다. 이번 section에서는, 먼저 Algorithm 1의 baseline 구현을 구체화한다.
2.1 Baseline Training Procedure
연구팀은 ResNet의 널리 사용되는 구현법을 baseline으로 따른다. Training과 validation 사이의 preprocessing 파이프라인들은 다르다. Training 동안에, 연구팀은 다음 step들을 one-by-one으로 수행한다.
1) 이미지를 랜덤하게 샘플링하고 그 이미지를 [0, 255] 범위의 32비트 소수점 raw pixel 값으로 decode한다.
2) [3/4, 4/3] 범위에서 랜덤하게 샘플링 하여 나온 가로세로 비율로 사각형의 region을 랜덤하게 잘라내고 영역은 [8%, 100%] 범위에서 랜덤하게 샘플링 된다. 그리고 잘려 나온 region을 224x224 사각형 이미지로 resize시킨다.
3) 0.5의 확률로 horizontally flip을 한다.
4) hue(색상), saturation(채도), brightness(밝기)를 [0.6, 1.4] 범위에서 uniform하게 뽑힌 계수로 scale한다.
5) 정규분포 N(0, 0.1)에서 샘플링 된 계수의 PCA noise(??)를 추가한다.
6) RGB channel에서 123.68, 116.779, 103.939를 빼고 58.393, 57.12, 57.375로 각각 나누어서 정규화를 한다.
Validation 동안에, 각 이미지에서 더 짧은 선을 256 픽셀로 resize하며, 가로세로비율은 유지시킨다. 다음으로, 중앙에서 224x224 region을 잘라내고 RGB channel을 training과 유사하게 정규화 한다. Validation 동안에는 어떠한 랜덤 augmentation도 수행하지 않는다.
Convolutional layer와 fully-connected layer의 weight 둘 다는 Xavier algorithm으로 초기화된다. 특히, 파라미터는 [-a, a] 범위에서 uniform하게 랜덤 값으로 설정한다. (a = (6 / (d_in + d_out)) ^ (-1/2)) 여기서 d_in과 d_out은 각각 input과 output의 channel size이다. 모든 bias들은 0으로 초기화된다. Batch normalization layer에서, γ 벡터들은 1로 초기화되고 β 벡터들은 0으로 초기화된다.
Nesterov Accelerated Gradient(NAG) descent가 training에 사용된다. 각 모델은 batch size 256으로 8개의 Nvidia V100 GPU로 120 epoch만큼 훈련된다. 학습률은 0.1로 초기화하고 30, 60, 90번째 epoch에서 10씩 나누게 된다.
2.2 Experiment Results
ResNet-50, Inception-V3, MobileNet 이렇게 3개의 CNN을 평가한다. Inception-V3에서는 input image를 299x299로 resize한다. 연구팀은 ISLVRC2012 데이터셋(ImageNet이라고 하는 것)을 사용하고, 이 데이터셋은 training을 위해 130만개의 이미지가 있고 1000개의 클래스가 있다. Validation 정확도는 Table 2에 묘사되어 있다.

여기서 볼 수 있다시피, 연구팀의 ResNet-50 결과들이 Reference 결과들보다 조금 더 좋으며, 반면에 baseline Inception-V3와 MobileNet은 다른 training procedure로 인해 조금 더 낮은 정확도를 보인다.
3 Efficient Training
하드웨어, 특히 GPU는 최근 몇 년간 가파르게 발전해왔다. 결과적으로, trade-off와 관련된 많은 performance를 위한 최적의 선택지들이 변화하였다. 예를 들어, 현재는 훈련 동안에 더 낮은 숫자 정밀도를 사용하고 더 큰 batch size를 사용하는 것이 더 효율적이다. 이번 section에서, 모델의 정확도 희생 없이 낮은 정밀도와 큰 batch size를 가능하게 하는 여러가지 테크닉을 살펴본다. 몇몇 테크닉은 심지어 정확도와 훈련 속도도 향상시킬 수 있다.
3.1 Large-batch training
Mini-batch SGD는 병렬 구조를 증가시키고 communication cost를 감소시키기 위해서 여러 개의 샘플들을 mini-batch로 묶는다. 그러나, 거대한 batch size를 사용하는 것은 training progress를 느리게 할지도 모른다. Convex problem(convex optimization을 의미하는 듯함, convex function의 optimization문제로 convex하기 때문에 optimization의 solution은 유일하다)의 경우에는, batch size가 증가함에 따라 convergence rate가 감소한다. 다시 말해서, 같은 숫자의 epoch라면, 거대한 batch size로 훈련하는 것이 작은 batch size로 훈련한 모델들과 비교하여 validation 정확도가 감소한다는 것이다.
다수의 연구에서 이 issue를 해결하기 위해 휴리스틱들을 제안해왔다. 다음 나오는 문단들에서, single machine training을 위해 batch size를 증가시키는 것을 도와줄 4가지 휴리스틱에 대해 알아볼 것이다.
Linear scaling learning rate.
Mini-batch SGD에서, gradient descending은 랜덤한 작업이다. 왜냐하면 각 batch에서 랜덤하게 선택되기 때문이다. Batch size를 증가시키는 것은 SGD의 기댓값을 변화시키는 것은 아니지만, 분산은 줄여주게 된다. 다시 말해서, 거대한 batch size는 gradient 내의 noise를 감소시켜주며, 그래서 연구팀에서는 더 큰 향상을 위해서 gradient의 반대 방향으로 학습률을 증가시킬 것이다. Goyal et al.은 batch size와 함께 선형적으로 학습률을 증가시키는 것이 ResNet-50 training에 경험적으로 잘 될 것 이라고 보고하고 있다. 특히, batch size 256에 초기 학습률을 0.1로 설정하는 He et al.의 사례를 따른다면, 더 큰 batch size 256으로 변경할 때, 초기 학습률은 0.1 * b / 256으로 증가시킬 것이다.
Learning rate warmup.
Training의 초기에, 모든 파라미터들은 전형적으로 랜덤한 값이며 최종 solution과는 멀리 떨어져 있게 된다. 너무 큰 학습률을 사용하는 것은 numerical instability(수치적 불안정성, input에서의 error가 최종 output에 커다란 error를 일으키게 됨(그래디언트 폭발 같은 것 같음))을 일으킬 수 있다. Warmup 휴리스틱에서, 초기에는 작은 학습률을 사용하며, training process가 안정화되면 초기의 학습률로 바꾸게 된다. Goyal et al.은 학습률을 0에서 초기 학습률까지 선형적으로 증가시키는 점진적인 warmup을 제안한다. 다시 말하면, 첫 m개의 batch들은 warm up에 사용하고 초기 학습률이 η이라고 가정하면, batch i(1 <= I <= m)에서는 학습률이 iη/m이 될 것이다.
Zero γ.
ResNet 네트워크는 여러 개의 residual block들로 구성되고, 각 block은 여러 개의 convolutional layer들로 구성된다. Input x가 주어지고, block(x)를 block의 마지막 layer의 output이라고 가정하면, 이 residual block은 output으로 x + block(x)을 내게 된다. 명심해야 할 것은 block의 마지막 layer가 batch normalization(BN) layer가 될 수 있다는 것이다. BN layer는 처음에 BN layer의 input을 정규화시키고(이를 X̂이라 표시함), 후에 scale transformation인 γX̂ + β를 수행한다. γ와 β는 학습 가능한 파라미터들로, 이들의 원소들은 각각 1과 0들로 초기화된다. Zero γ 휴리스틱에서, residual block의 끝에 위치한 모든 BN layer들에 대하여 γ = 0으로 초기화한다. 그러므로, 모든 residual block들은 그저 그들의 input을 return할 뿐이고, 더 적은 숫자의 layer를 가진 네트워크를 모방하며, 초기 단계에서 훈련시키기 더 쉽다.
No bias decay.
Weight decay는 종종 weight와 bias를 포함한 모든 학습 가능한 파라미터들에 적용된다. 이는 모든 파라미터들의 값을 0으로 향하게 하는 L2 regularization을 적용하는 것과 동일하다. 그러나, Jia et al.에 의해 지적된 것처럼, overfitting을 방지하기 위해서는 오직 weight에만 regularization을 적용하는 것이 추천된다. No bias decay 휴리스틱은 이 권고사항을 따르며, convolution layer와 fully-connected layer의 weight에만 weight decay를 적용한다. Bias와 BN layer의 γ, β를 포함하는 다른 파라미터들은 그대로 냅둔다.
주목할 점은 LARS(Layer-wise Adaptive Rate Scaling, weight와 gradients update의 norm 사이의 비율을 측정, 이를 토대로 layer마다 학습률을 다르게 하며, update되는 정도는 weight norm에 따라 달라짐)에서 layer-wise adaptive learning rate를 제안하고, 이는 극단적으로 거대한 batch size(16K 이상)에 효과적이라고 보고되었다. 비록 이 논문에서는 single machine training에 충분한 방법들로 제한하지만, 이 경우에는 2K 이하의 batch size가 종종 시스템의 효율성을 향상시킨다.
3.2 Low-precision training
신경망은 보통 32bit 부동소수점(FP32) 정밀도로 훈련된다. 즉, 모든 숫자들이 FP32 포맷으로 저장되고 input과 output의 산술연산 또한 FP32 숫자이다. 그러나, 새로운 하드웨어는 더 낮은 precision data type을 위해서 아마 향상된 산술 logic unit을 가질 것이다. 예를 들어서, 이전에 언급된 Nvidia V100은 FP32에서 14 TFLOPS(Tera Floating Point Operations Per Second, 초당 부동소수점 연산이라는 의미로 컴퓨터가 1초동안 수행할 수 있는 부동소수점 연산의 횟수로 컴퓨터의 성능을 수치로 나타내는 단위)를 제공하지만, FP16에서는 100이상의 TFLOPS를 제공한다. Table 3에서처럼 전반적인 training 속도는 V100 기준 FP32에서 FP16으로 바꾼 후에 2배에서 3배정도 증가하였다.

성능의 이익에도 불구하고, 감소된 정밀도는 결과들이 범위를 벗어나게 만드는 더 좁은 범위를 가지게 되어(??) training 진행을 방해할 수 있다. Micikevicius et al.은 모든 파라미터들과 activation들을 FP16으로 저장하고 gradient 계산 시 FP16을 사용하는 것을 제안한다. 동시에, 모든 파라미터들은 파라미터 업데이트를 위해 FP32로 copy본을 가진다. 게다가, gradient의 범위를 FP16에 더 잘 맞추기 위해서 loss에 scalar를 곱하는 것 또한 실용적인 solution이다.
3.3 Experiment Results
ResNet-50에 대한 평가 결과는 Table 3에 나타난다. Batch size 256 및 FP32를 사용하는 baseline과비교할 때, 더 큰 1024 batch size와 FP16을 사용하는 것은 ResNet-50의 훈련 시간을 epoch 당 13.3분에서 4.4분으로 줄여준다. 게다가, 거대한 batch training을 위해 모든 휴리스틱을 쌓음으로써, batch size 1024 및 FP16으로 훈련된 모델은 baseline 모델과 비교하여 미세하게 top-1 accuracy가 0.5% 상승하였다.
모든 휴리스틱의 ablation study는 Table 4에 나타나있다.

Linear scaling learning rate만으로 batch size를 256에서 1024로 증가시키는 것으로 top-1 accuracy가 0.9% 감소하는 것에 이르며, 나머지 3개의 휴리스틱을 쌓는 것으로 이 격차를 메우게 된다. 훈련의 끝에서 FP32에서 FP16으로 바꾸는 것은 정확도에 영향을 주지 않는다.
4 Model Tweaks
Model tweak은 네트워크 아키텍처에 대한 작은 조정으로, 특정 convolution layer의 stride를 변경하는 등이 있다. 이러한 tweak은 종종 계산 복잡도는 거의 변화시키지 않지만, 모델 정확도에 있어서 무시할 수 없는 영향을 가질 수 있다. 이번 section에서는, model tweak들의 영향을 조사하기 위해서 ResNet을 예시로 사용할 것이다.
4.1 ResNet Architecture
간단하게 ResNet 아키텍처를 소개할 것이고, 특히 model tweak과 관련된 모듈들을 소개할 것이다. 자세한 설명을 원한다면 He et al.을 참조하라. ResNet 네트워크는 input stem, 4개의 후속 stage들, 그리고 최종 output layer로 구성되며, Figure 1에 묘사 되어있다.

Input stem에는 7 x 7 filter, output channel 64개, 그리고 stride는 2인 convolution과 그 뒤에는 3 x 3 filter에 stride가 2인 max pooling layer가 있다. Input stem은 input의 너비와 높이를 4배 감소시키고 channel size는 64로 증가시킨다.
Stage 2에서 시작하여, 각 stage는 downsampling block으로 시작하여, 뒤에는 여러 residual block이 오게 된다. Downsampling block에서, path A와 path B가 있다. Path A에는 3개의 convolution이 있으며, 각 kernel size는 1 x 1, 3 x 3, 1 x 1이다. 첫번째 convolution은 input의 width와 height를 반으로 나누기 위하여 stride 2를 가지며, 마지막 convolution의 output channel은 이전 2개보다 4배 더 크며, 이 구조를 bottleneck 구조라 한다. Path B는 input shape을 path A의 output shape이 되도록 변환하기 위해 1 x 1 convolution에 stride 2를 사용한다. 그래서 downsampling block의 output을 얻기 위해 2개의 path의 output을 더할 수 있다. Residual block은 downsampling block과 비슷한데, 다른 점은 오직 stride 1인 convolution만 사용한다.
다른 ResNet 모델들을 얻기 위해 각 stage에서 residual block의 숫자를 달리 할 수 있으며, ResNet-50 및 ResNet-152등이 있고, 여기서 숫자는 네트워크 내의 convolutional layer의 숫자를 나타낸다.
4.2 ResNet Tweaks
다음으로, 2개의 인기있는 ResNet tweak을 다시 살펴볼 것이고, 각각 ResNet-B, ResNet-C라 부를 것이다. 후에는 새로운 model tweak인 ResNet-D를 제안한다.
ResNet-B.
이 tweak은 ResNet의 Torch 구현에서 처음 등장하였고 많은 연구에서 채택되었다. 이것은 ResNet의 downsampling block을 변화시킨다. 확인할 수 있는 것은 path A의 convolution이 input feature map의 4분의 3을 무시하며, 이유는 바로 stride 2의 1 x 1 kernel size를 사용하기 때문이다. ResNet-B는 path A의 첫 2개의 convolution들의 stride size를 Figure 2a에 나타난 것처럼 변경하므로, 어떤 정보도 무시되지 않는다.

왜냐하면 2번째 convolution이 3 x 3 kernel size를 가지므로, path A의 shape은 변화가 없다.
ResNet-C.
이 tweak은 원래 Inception-v2에서 제안된 것이며, 다른 모델들의 구현에서 발견할 수 있다. SENet, PSPNet, DeepLabV3, 그리고 ShuffleNetV2 등이 있다. 확인할 수 있는 점은 convolution의 계산 cost가 kernel width 또는 height에 제곱적이라는 것이다. 7 x 7 convolution은 3 x 3 convolution보다 5.4배 정도 더 expensive하다. 그래서 이 tweak에서는 input stem의 7 x 7 convolution을 3개의 3 x 3 convolution들로 교체하며, Figure 2b에 묘사되어 있다. 첫번째와 두번째 convolution들은 output channel이 32이며 stride가 2이고, 마지막 convolution은 64개의 output channel을 사용한다.
ResNet-D.
ResNet-B에 자극을 받아, downsampling block의 path B의 1 x 1 convolution 또한 input feature map의 3/4을 무시한다는 점을 주목하여, 어떠한 정보도 무시되지 않도록 이를 변경할 것이다. 경험적으로, convolution의 stride를 1로 바꾸고, stride가 2인 2 x 2 average pooling layer를 convolution 이전에 추가하는 것이 실제로 잘 동작하고 계산 cost에 거의 영향을 안 준다는 것을 발견하였다. 이 tweak은 Figure 2c에 묘사되어 있다.
4.3 Experiment Results
ResNet-50을 3개의 tweak과 Section 3에서 묘사된 setting들(batch size가 1024, 정밀도는 FP16)로 평가한다. 결과는 Table 5에 묘사되어 있다.

결과에 따라 ResNet-B는 downsampling block의 path A에서 더 많은 정보를 얻고 ResNet-50과 비교하여 0.5% 정도 validation accuracy가 향상되었다. 7 x 7 convolution을 3개의 3 x 3 convolution들로 교체하는 것은 또다시 0.2% 정도의 향상을 만들어낸다. Downsampling block의 path B에서 정보를 더 얻는 것은 validation accuracy를 다시 0.3% 정도 향상시킨다. 종합적으로, ResNet-50-D는 ResNet-50보다 1%정도 성능이 향상된다.
반면에, 이 4가지 모델들은 같은 모델 사이즈를 가진다. ResNet-D는 가장 큰 계산 cost를 가지지만, 부동소수점 연산에 있어서는 ResNet-50과의 차이는 15% 이내이다. 실제로, ResNet-50-D는 ResNet-50과 비교하여 훈련 속도가 오직 3%만 더 느릴 뿐이다.
5 Training Refinements
이번 section에서, 모델의 정확도를 더욱 향상시키는 것을 목적으로 4가지 training refinement를 묘사할 것이다.
5.1 Cosine Learning Rate Decay
학습률 조정은 training에서 매우 중요하다. Section 3.1에서 묘사된 learning rate warmup 후에, 초기 학습률로부터 값을 점진적으로 감소시킨다. 널리 사용되는 전략은 학습률을 지수적으로 감소시키는 것이다. He et al.에서는 매 30 epoch마다 0.1의 비율로 감소시키고, 연구팀에서는 이를 “step decay”라 부른다. Szegedy et al.은 매 2 epoch마다 0.94의 비율로 감소시킨다.
이와 대조적으로, Loshchilov et al.은 cosine annealing(금속과 관련된 용어로, 고온에서 오랫동안 금속을 노출시켜 금속을 더 부드럽게 만드는 작업, 담금질과 비슷함) 전략을 제안한다. 간단한 버전은 초기값에서 0까지 cosine 함수를 따라서 학습률을 감소시키는 것이다. Batch의 총 개수를 T(warmup stage는 무시함)라 가정하면, batch t에서 학습률 η_t는 다음과 같이 계산된다.

여기서 η은 초기 학습률이다. 연구팀에서는 이 scheduling을 “cosine” decay라 부른다.
Step decay와 cosine decay사이의 비교가 Figure 3a에 묘사되어 있다.

그림에서 보다시피, cosine decay는 초기에는 학습률이 천천히 감소하다가, 중반부에는 거의 선형적으로 감소하고, 마지막에는 다시 천천히 감소한다. Step decay와 비교하여, cosine decay는 초기부터 감소하기 시작하지만, step decay가 학습률이 1/10로 감소할 때 까지 큰 상태를 유지하며, 이는 잠재적으로 training의 진행을 향상시킨다.
5.2 Label Smoothing
Image classification 네트워크의 마지막 layer는 예측된 confidence score를 출력하기 위해서 종종 label의 개수(K로 표시함)와 같은 hidden size를 가지는 fully-connected layer이다. 이미지가 주어지면, z_i로 class i에 대한 예측 점수를 표시한다. 이 score들은 예측 확률을 얻기 위해 softmax 연산(q = softmax())을 통해 정규화 될 수 있다. Class i에 대한 확률인 q_i는 다음과 같이 계산된다.

여기서, q_i > 0이고 q_i의 합이 1이라는 것을 쉽게 확인할 수 있고, 그래서 q는 유효한 확률분포이다.
반면에, 이 이미지의 true label이 y라 가정하면, i = y일때 p_i = 1, 아니라면 p_i = 0인 참 확률분포를 만들 수 있다. training동안에, 이 2개의 확률분포를 서로 비슷하게 하기 위해서 모델 파라미터를 업데이트하고, 이를 위해서 음의 cross entropy loss를 최소화한다.

특히, p가 구성되는 방법을 통해서, l(p, q) = -logp_y = -z_y + log(...)을 알 수 있다.
(이 부분을 읽다가 이상한 점을 느꼈는데, 저 cross entropy loss식이 성립하려면, q가 truth probability distribution이여야하고 p가 predicted probability distribution이여야 성립한다. 다른 곳에서도 q와 p의 역할이 반대인 것으로 나타나고 있다.)
최적의 solution은 z*_y = inf이고 다른 score들은 충분히 작아야 한다. 다시 말해서, 이는 output score를 극적으로 독특하게 만들어서, 잠재적으로 overfitting에 이르게 할 수 있다.
Label smoothing의 아이디어는 Inception-v2를 훈련시키기 위해 처음으로 제안되었다. 여기서 참 확률분포를 다음과 같이 변경한다.
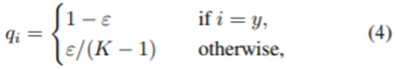
여기서 ε은 작은 상수이다. 그러면 이제 최적의 solution은 다음과 같아진다.

여기서 α는 임의의 실수가 될 수 있다. 이 방법은 fully-connected layer로부터 유한한 output을 유도하고 더 일반화를 잘 시킬 수 있다.
ε = 0일 때, log((K - 1)(1 - ε)/ε)은 무한대가 되고, ε이 증가하면, 이 값은 줄어든다. 구체적으로 ε = (K - 1) / K일 때, 모든 최적의 z*_i은 동일해진다. Figure 4a에서 ε이 이동하는 것에 따라 이 격차가 어떻게 변하는 지 보여지며, 여기서 ImageNet 데이터셋을 써서 K = 1000이다.

연구팀에서는 경험적으로 output value를 label smoothing으로 훈련된 것과 훈련되지 않는 각각 2개의 ResNet-50-D 모델들로부터 비교하고, 최대 예측값과 나머지의 평균 사이의 격차를 계산한다. ε = 0.1 이고 K = 1000일 때, 이론적인 격차는 9.1정도 된다. Figure 4b에서는 ImageNet의 validation set을 예측하는 두 모델로부터의 격차 분포를 증명한다. 여기서 label smoothing이 있으면 분포가 이론적인 값 근처로 모이고 더 적은 극단적인 값을 갖는다는 것이 명확히 보인다.
5.3 Knowledge Distillation
Knowledge distillation(미리 학습시킨 Teacher network(거대 네트워크)의 출력을 실제로 사용하고자 하는 작은 모델인 Student network가 모방하여 학습함. 파라미터 수가 적어도 모델의 성능을 높이게됨)에서는 현재 모델(student model)의 훈련을 돕기 위해 teacher model을 사용한다. Teacher model은 보통 높은 정확도의 pre-trained 모델이며, 모방을 통해서 student model은 모델의 복잡도를 동일하게 유지한 상태에서 정확도를 높일 수 있다. 한 예시로는 ResNet-152를 teacher model로하여 ResNet-50의 훈련을 돕는 것이다.
Training 동안에, teacher model과 learner model로부터의 softmax output 사이의 차이를 penalize하기 위해 distillation loss를 더해준다. Input이 주어지면, p를 실제 확률분포라 하면, z와 r은 각각 student model과 teacher model의 마지막 fully-connected layer의 output이라 하자. 기억해야 할 것은, 이전에 음의 cross entropy loss l(p, softmax(z))를 p와 z 사이의 차이를 측정하기 위해 사용하였고, 여기서는 같은 loss를 distillation을 위해 사용한다는 것이다. 그러므로, loss는 다음과 같이 변경된다.

여기서 T는 softmax output을 더 smooth하게 만들기 위한 temperature hyper-parameter이며, teacher의 예측으로부터 label distribution의 지식을 distill(증류)한다.
5.4 Mixup Training
Section 2.1에서, 이미지들이 training 전에 어떻게 augment되는지 묘사하였다. 여기서는 또다른 augmentation인 mixup에 대해 고려한다. mixup에서, 각 시간마다 2개의 예시인 (x_i, y_i)와 (x_j, y_j)를 랜덤하게 샘플링한다. 그러고나서 이 2개의 예시에 대한 가중치가 곱해진 선형 보간법을 통해 새로운 예시를 생성한다.

여기서 λ는 베타분포인 Beta(α, α)로부터 나온 랜덤값으로 [0, 1] 범위에 해당한다. Mixup training에서, 이 새로운 예시 (xhat, yhat)만 사용한다.
5.5 Experiment Results
이제 4개의 training refinement에 대해 평가한다. Szegedy et al.을 따라서 label smoothing에서 ε = 0.1로 설정한다. Model distillation에서, T = 20을 사용하고, 구체적으로 cosine decay와 label smoothing을 다 적용한 pre-trained ResNet-152-D 모델이 teacher로 사용된다. Mixup training에서, 베타분포의 α = 0.2로 고르고 epoch 숫자는 120에서 200으로 증가시킨다. 왜냐하면 mixed example은 더 잘 수렴하기 위해서 더 긴 training progress를 요구하기 때문이다. Mixup training과 distillation을 결합할 때, mixup과 함께 teacher model 또한 훈련시킨다.
연구팀에서는 refinement가 ResNet 구조나 ImageNet 데이터셋에만 제한된 것이 아니라는 것을 증명한다. 먼저, ResNet-50-D, Inception-V3, 그리고 MobileNet을 refinement와 함께 ImageNet 데이터셋으로 훈련시킨다. 이 training refinement들을 하나씩 적용하여 나온 Validation 정확도가 Table 6에 나와있다.

Cosine decay, label smoothing, 그리고 mixup을 쌓음으로써, ResNet, Inception-V3, 그리고 MobileNet 모델들을 꾸준히 상승시켰다. 그러나, Distillation은 ResNet에서는 잘 작동하지만, Inception-V3와 MobileNet에서는 잘 작동하지 않는다. 이에 대한 해석으로는, teacher model이 student와 같은 가족으로부터 온 게 아니기에, 예측 시 다른 분포를 가지고, 모델에 악영향을 준다는 것이다.
이 trick들을 다른 데이터셋으로 전이할 수 있도록 지원하기 위해서, ResNet-50-D 모델을 refinement를 적용 혹은 적용하지 않은 채 MIT Places365 데이터셋으로 훈련시킨다. 결과는 Table 7에 나와있다.

Refinement들이 Validation set과 test set 양쪽 모두에서 top-5 정확도를 상승시킨다는 것을 볼 수 있다.
6 Transfer Learning
Transfer learning은 훈련된 image classification 모델의 주요한 down-streaming use case이다. 이번 section에서, 지금까지 논의된 이러한 개선들이 transfer learning에 도움이 될 지 조사할 것이다. 특히, 2가지 중요한 CV task를 고를 것이다. Object detection과 semantic segmentation이 있으며, base model들을 다양하게 하여서 성능을 측정한다.
6.1 Object Detection
Object detection의 목표는 이미지에서 물체들의 bounding box를 위치시키는 것이다. 성능은 PASCAL VOC을 사용하여 평가한다. Ren et al.과 비슷하게, VOC 2007 trainval과 VOC 2012 trainval의 합집합을 training에 사용하고, VOC 2007 test를 평가에 사용한다. 이 데이터셋으로 Faster-RCNN을 훈련시키고, refinement는 Detectron에서의 refinement인 linear warmup과 long training schedule을 사용한다. Faster-RCNN의 VGG-19 base model은 이전 논의에서의 여러가지 pretrained model들로 대체된다. 다른 세팅들은 동일하게 유지하여 gain이 base model로부터만 오도록 한다.
Mean average precision(mAP, 주로 object detection의 성능 평가 지표로 사용된다. 각각의 클래스에 대한 AP의 면적, AP는 Precision-Recall 그래프의 아래 면적을 의미함) 결과는 Table 8에 나와있다.

확인할 수 있는 것은, 더 높은 validation 정확도를 가진 base model이 동일하게 Faster-RNN에 대해 더 높은 mAP에 이른다는 것이다. 특히, 가장 좋은 base model(정확도 79.29%, ImageNet)은 가장 좋은 mAP에 이른다.
6.2 Semantic Segmentation
Semantic Segmentation은 input image들로부터의 모든 픽셀에 대한 카테고리를 예측한다. 이 task를 위해서 Fully Convolutional Network(FCN)을 사용하고 모델은 ADE20K 데이터셋으로 훈련시킨다. PSPNet과 Zhang et al.을 따라서, base network를 이전 section들에서 논의된 다양한 pretrained 모델들로 교체하고 stage-3와 stage-4에서 dilation network 전략을 적용한다. Fully convolutional decoder는 base network 맨 위에 붙게 되며, 이를 통해 최종 예측을 만든다.
픽셀의 정확도와 mean intersection over union(mIoU, 주로 semantic segmentation에서 사용하는 대표적인 성능 측정 방법)가 Table 9에 나타난다.

Object detection에서의 결과와는 반대로, cosine 학습률 schedule은 FCN 성능의 정확도를 높이지만, 다른 refinement들은 덜 최적화된 결과를 제공한다. 이 현상에 대한 가능성 있는 설명은 바로 semantic segmentation이 pixel level로 예측해서이다. Label smoothing, distillation, mixup으로 훈련된 모델은 soften label을 선호하는 반면에, 흐릿한 pixel-level 정보는 흐릿해 질것이고, 전반적인 pixel-level 정확도가 저하될 것이다.
7 Conclusion
이번 논문에서, 연구팀은 모델의 정확도를 높이기 위한 deep convolutional neural network를 훈련시키기 위한 12개의 trick들을 조사하였다. 이 trick들은 모델 아키텍처, 데이터 전처리, 손실 함수, 그리고 학습률 schedule에 작은 변화를 준다. ResNet-50, Inception-V3, MobileNet에 대한 경험적인 결과들에서 이 trick들이 모델 정확도를 올린다는 것을 보여주고 있다. 더 대단한 것은, 이것들을 모두 묶어 사용하는 것이 더 높은 정확도로 이어진다는 것이다. 게다가, 이 향상된 pre-trained 모델들은 transfer learning에서 강한 장점을 보이며, object detection과 semantic segmentation의 성능을 향상시킨다. 연구팀은 이 장점들이 classification base 모델들이 선호되는 더 넓은 domain들로 확장할 수 있다고 생각한다.
References
생략함
'Naver BoostCamp AI Tech 3기' 카테고리의 다른 글
| Language Models are Unsupervised Multitask Learners (0) | 2022.03.14 |
|---|---|
| Improving Language Understanding by Generative Pre-Training (0) | 2022.03.10 |
| (Vision Transformer)AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (0) | 2022.02.19 |
| [코드리뷰]BERT (2) | 2022.02.15 |
| BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (1) | 2022.02.13 |