2022. 2. 19. 17:04ㆍNaver BoostCamp AI Tech 3기
ABSTRACT
Transformer 아키텍처가 NLP task에서 de-facto standard(사실상 표준, 공인 기관에서 공식적으로 지정한 표준은 아니지만 현재 압도적으로 쓰이는 업계 표준을 의미함)된 반면에, Computer Vision에서의 Transformer 적용은 제한적인 상태이다. Vision에서는, 전반적인 아키텍처를 유지하는 상태에서, attention은 CNN과 결합하여 적용되거나, CNN 내의 특정 구성요소를 대체하는 방식으로 사용된다. 이번 연구팀에서는 이 CNN에 의존할 필요가 없고, 순수히 transformer를 image patch들의 sequence에 직접 적용하는 것이 image classification task들에 매우 잘 작동할 수 있다는 것을 보여준다. 많은 양의 데이터로 pre-trained되고 중간 사이즈 혹은 작은 사이즈의 image recognition benchmark에 전이될 때(ImageNet, CIFAR-100, VTAB 등), Vision Transformer(ViT)는 훈련을 위해서 대체로 더 적은 계산 리소스를 요구하며, state-of-the-art를 달성한 CNN들과 비교하여 매우 훌륭한 결과를 달성할 수 있다.
1 INTRODUCTION
Self-attention 기반 아키텍처들, 특히 Transformers(Vaswani et al., 2017)은 NLP에서 주로 선택하는 모델이 되었다. 우세한 접근법은 거대한 텍스트 corpus로 pre-train을 하고 더 작은 task-specific한 데이터셋으로 fine-tune을 시키는 것(Devlin et al., 2019)이다. Transformers의 계산적 효율성과 확장성 덕택에, 전례없는 사이즈(1000억개가 넘어가는 파라미터들(Brown et al., 2020; Lepikhin et al., 2020))의 모델들을 훈련시키는 것이 가능해졌다. 모델들과 데이터셋들이 성장하는 상태에서, 여전히 성능이 포화되는 sign(성능이 더 이상 올라가지 않는 상태를 말하는 듯함)이 있지는 않은 상태이다.
그러나, Computer Vision에서는 CNN 아키텍처들이 여전히 강세를 보인다. (LeCun et al., 1989; Krizhevsky et al., 2012; He et al., 2016) NLP에서의 성공에 자극을 받아, 여러 개의 연구들에서 CNN-like한 아키텍처들과 self-attention을 결합하려고 시도(Wang et al., 2018; Carison et al., 2020)를 하며, 몇몇 연구는 convolution들 전체를 교체하는 시도(Ramachandran et al., 2019; Wang et al., 2020a)도 하고 있다. 근래의 모델들은, 이론적으로는 효율적이지만, 전문화된 attention 패턴들의 사용으로 인해, 현대 하드웨어 가속기들에 대해 효율적으로 확장되지 못한 상황이다. 그러므로, 거대한 규모의 image recognition에서, classic한 ResNet-like한 아키텍처들이 여전히 state-of-the-art를 달성하는 상황이다. (Mahajan et al., 2018; Xie et al., 2020; Kolesnikov et al., 2020)
NLP에서의 Transformer scaling 성공에 자극을 받아, 이번 연구팀에서는 standard한 Transformer를 이미지들에 직접 적용하는 실험을 하고, 가능한 변화사항을 최소화하여 진행하였다. Transformer 적용을 위해서, 연구팀에서는 이미지를 patch들로 분할하고 이 patch들의 linear embedding의 sequence를 Transformer의 input으로 제공한다. 이미지 patch들은 NLP application에서의 token들과 같은 방식으로 취급받는다. 연구팀에서는 image classification을 supervised fashion으로 훈련시킨다.
강한 regularization 없이 중간 사이즈의 데이터셋인 ImageNet과 같은 것으로 훈련을 시킬 때, 이 모델들은 유사한 사이즈의 ResNet보다 몇 퍼센트 포인트 낮은 그다지 크지 않은 정확도를 얻는다. 이 김빠지는 결과는 아마 예상 가능한 결과일 것이다. 왜냐하면 Transformers는 CNN의 고유한 inductive bias(귀납적 편향, 학습 시에는 만나보지 않았던 상황에 대하여 정확한 예측을 하기 위해 사용하는 추가적인 가정을 의미함)(translation equivariance(이미지에서 어떤 사물의 위치가 바뀌면 CNN과 같은 연산의 activation 위치가 바뀜), locality와 같은 것들)들이 없고, 그러므로 충분치 않은 양의 데이터로 훈련 시 일반화를 잘하지 못하게 되기 때문이다.
그러나, 만약 모델들이 더 큰 데이터셋(1400만~3억개 이미지)에 훈련이 되면, 이러한 양상은 변화한다. 연구팀에서는 거대한 규모의 훈련이 inductive bias를 뛰어넘는다는 걸 발견하였다. 연구팀의 Vision Transformer(ViT)는 충분한 scale로 pre-trained되고 더 적은 datapoint가 있는 task들로 전이될 때 매우 좋은 결과를 달성한다. Public ImageNet-21k 데이터셋, 또는 in-house JFT-300M 데이터셋으로 pre-trained될 때, ViT는 여러 image recognition benchmark들의 state-of-the-art에 근접하였다. 특히, 가장 좋은 모델은 ImageNet에 대해 88.55%의 정확도를, ImageNet-ReaL에 대해서는 90.72%의 정확도를, CIFAR-100에 대해서는 94.55%의 정확도를, 그리고 19개 task의 집합군인 VTAB에 대해서는 77.63%의 정확도를 달성하였다.
2 RELATED WORK
Transformers는 Vaswani et al. (2017)에 의해 제안된 구조로, machine translation을 위한 것이였다. 그리고 현재 많은 NLP task들의 state-of-the-art 방법이 되었다. 거대한 Transformer-based 모델들은 보통 거대한 corpora로 pre-trained되고 task들로 fine-tuned 된다. BERT (Devlin et al., 2019)는 denoising self-supervised pre-training task를 사용하고, 반면에 GPT 계열 연구는 language modeling을 pre-training task로 사용한다. (Radfored et al., 2018; Brown et al., 2020)
이미지에 대한 self-attention의 naïve application은 각 픽셀이 모든 다른 픽셀에 참여하는 것을 요구할지도 모른다. Cost는 픽셀의 숫자에 제곱되지만, 이것은 실제 input size에 비례하지 않는다. 그래서, image processing에서 Transformers를 적용하기 위해서는, 과거에 여러 접근이 시도되었다. Parmar et al. (2018)은 self-attention을 global하지는 않고 각 query 픽셀에 대해 오직 이웃한 local 픽셀들에만 적용하였다. 이러한 local multi-head dot-product self-attention 블록들은 완전하게 convolution들을 대체할 수 있다. (Hu et al., 2019; Ramachandran et al., 2019; Zhao et al., 2020) 다른 계열 연구에서는, Sparse Transformers(Child et al., 2019)는 이미지에 응용하기 위해 global self-attention에 대한 scalable한 접근을 사용하였다. Scale attention에 대한 대안법은 attention을 다양한 사이즈의 블록들에 적용하는 것이고(Weissenborn et al., 2019), 극단적인 경우에는 오직 individual axes 사이에만 적용한다. (Ho et al., 2019; Wang et al., 2020a) 이런 많은 전문화된 attention 아키텍처들은 computer vision task들에 대한 기대되는 결과를 증명해냈지만, 하드웨어 가속기들에 효율적으로 구현되기 위해 복잡한 engineering을 요구한다.
이번 연구와 가장 관련된 모델은 Corodonnier et al. (2020)의 모델이고, 이 모델에서는 input 이미지로부터 2x2 사이즈의 patch들을 추출하고 맨 위에 전체 self-attention을 적용한다. 이 모델은 ViT와 매우 비슷하지만, 연구팀의 연구는 여기서 더 발전하여 거대한 규모의 pre-training이 vanilla transformers를 state-of-the-art CNN들과 경쟁할 수준이라는 것을 증명한다. 게다가, Cordonnier et al. (2020)은 작은 patch 사이즈의 2x2 픽셀들을 사용하고, 이는 모델이 오직 낮은 해상도의 이미지에만 적용 가능하게 해준다. 반면에, 연구팀의 모델은 중간 정도의 해상도의 이미지 역시 처리할 수 있다.
또한 CNN을 self-attention과 결합하는 것에 대해 많은 관심들이 있어왔다. 예시로 image classification을 위해 feature map들을 augment하는 것(Bello et al., 2019), 또는 self-attention을 사용하여 CNN의 output을 처리하는 것이 있다. 예시로는 object detection(Hu et al., 2018; Carion et al., 2020), video processing(Wang et al., 2018; Sun et al., 2019), image classification(Wu et al., 2020), unsupervised object discovery(Locatello et al., 2020), 또는 unified text-vision task(Chen et al., 2020c; Lu et al., 2019; Li et al., 2019)등이 있다.
또다른 최근의 관련된 모델은 image GPT(iGPT)(Chen et al., 2020a)로, 이것은 이미지의 해상도와 color space를 낮춘 후에 Transformers를 이미지 픽셀들에 적용하는 방식이다. 이 모델은 generative model처럼 unsupervised fashion으로 훈련되며, 결과적인 representation은 classification performance를 위해서 fine-tuned 되거나 probe될 수 있고, ImageNet에 대해 최대 정확도 72%를 달성하였다.
이번 연구팀의 연구는 표준적인 ImageNet 데이터셋보다 더 거대한 규모의 image recognition에 대해 연구하는 논문들과 결을 같이한다. 추가적인 data source들의 사용은 standard benchmark(Mahajan et al., 2018; Touvron et al., 2019; Xie et al., 2020)들에 대해 state-of-the-art를 달성할 수 있게 한다. 게다가, Sun et al. (2017)은 어떻게 CNN 성능이 데이터셋의 크기에 맞춰 조절되는지를 연구하고, Kolesnikov et al. (2020); Djolonga et al. (2020)은 ImageNet-21k와 JFT-300M과 같은 거대한 규모의 데이터셋으로부터 CNN transfer learning에 대해 경험적인 분석을 수행한다. 이번 연구팀에서는 이 마지막 2개의 데이터셋에 또한 집중하지만, 이전 연구들에서 사용된 ResNet-based 모델들 대신에 Transformers를 훈련시킨다.
3 METHOD
모델 디자인에서는 original Transformer (Vaswani et al., 2017)을 가능한 가까이 따라하였다. 이 의도된 간단한 setup의 장점은 확장가능한 NLP Transformer 아키텍처와 그들의 효율적인 구현들이 거의 다 즉시 사용할 수 있다는 것이다.
3.1 VISION TRANSFORMER (ViT)
모델의 개요는 Figure 1에 묘사되었다.
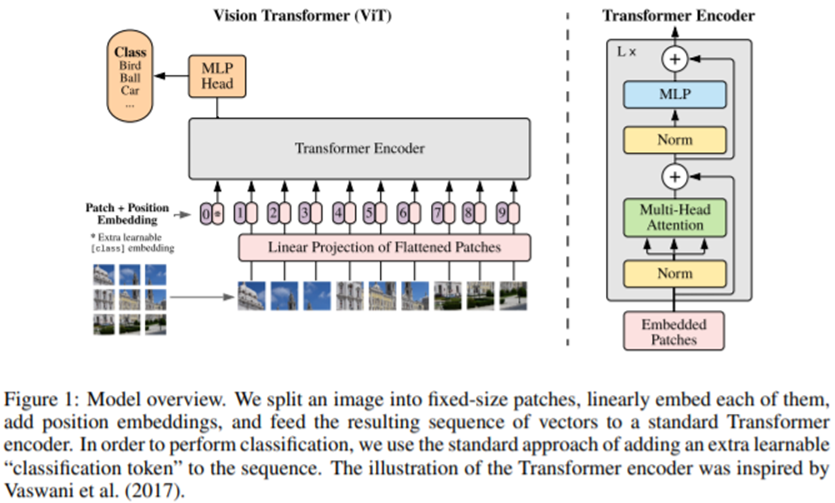
Standard Transformer는 input으로 token embedding의 1D sequence를 받는다. 2D 이미지들을 처리하기 위해서, 연구팀에서는 image x(H x W x C 차원에 속함)를 flattened된 2D patch x_p(N x (P^2 ∙ C))의 sequence로 reshape한다. 여기서 (H, W)는 original 이미지의 해상도이고, C는 channel의 숫자이고, (P, P)는 각 이미지 patch의 해상도이고, N = HW / P^2은 patch의 최종적인 개수이며, 또한 Transformer에 대해 효율적인 input sequence length로써의 역할도 한다. 이 Transformer는 상수 latent vector size인 D를 모든 layer들 내내 사용하며, 그래서 연구팀에서는 patch들을 flatten하고 훈련 가능한 linear projection과 함께 D 차원들로 map한다. (Eq. 1)

연구팀에서는 이 projection의 output을 patch embedding이라고 언급한다.
BERT의 [class] 토큰과 비슷하게, 연구팀에서는 학습 가능한 embedding(z0_0 = x_class)을 embedded patch들의 sequence의 앞에 붙인다. Transformer encoder의 output(z0_L)에서의 이 embedded patch들의 상태는 image representation y로써의 역할을 한다. (Eq. 4)

pre-training과 fine-tuning 동안에, classification head는 z0_L에 부착된다. 이 classification head는 pre-training 할 동안에 1개의 hidden layer가 있는 MLP에 의해 구현되며, fine-tuning 동안에는 단일 linear layer에 의해 구현된다.
Position embedding은 positional 정보를 유지하기 위해서 patch embedding에 더해진다. 연구팀에서는 standard한 학습 가능한 1D position embedding을 사용하며, 이는 더 발전된 2D-aware position embedding을 사용하는 것과는 커다란 performance차이를 발견하지 못했기 때문이다. (Appendix D.4) 결과적인 embedding vector들의 sequence는 encoder의 input으로써의 역할을 한다.
Transformer encoder (Vaswani et al., 2017)는 multiheaded self-attention(MSA, Appendix A 참조)를 대체하는 layer들로 구성되며, MLP 블록들로 구성된다. (Eq. 2, 3)

Layernorm(LN)은 모든 블록 이전에 적용되며, residual connection은 모든 블록 이후에 적용된다. (Wang et al., 2019; Baevski & Auli, 2019) MLP는 GELU의 비선형성과 함께 2개의 layer로 구성된다.
Inductive bias.
연구팀에서는 Vision Transformer가 CNN보다 훨씬 더 적은 image-specific한 inductive bias를 가진다고 주목한다. CNN에서는 locality, 2차원 neighborhood 구조, 그리고 translation equivariance들이 전체 모델 내내 각 layer로 필수적인 부분이 된다. ViT에서는, 오직 MLP layer들만 local이고 translationally equivariant하며, 반면에 self-attention layer들은 global하다. 2차원 neighborhood 구조는 매우 절약적으로 사용된다. 이 말은 모델 초기에 이미지를 patch들로 자르고 fine-tuning때 다른 해상도의 이미지들을 위한 position embedding을 조정하기 위함이다.(무슨 의미인지 모르겠음) 그 외에는, 초기화를 할 때의 position embedding은 patch들의 2D position에 대한 어떤 정보도 전달하지 않고 patch들 사이의 모든 공간적인 관계들은 scratch로부터 학습 되어야만 한다.
Hybrid Architecture.
Raw한 이미지 patch들에 대한 대안으로, input sequence는 CNN의 feature map들로부터 형성될 수 있다. (LeCun et al., 1989) 이 hybrid model에서는, patch embedding projection E(Eq. 1)는 CNN feature map으로부터 추출된 patch들에 적용된다. 특별한 경우로, patch들은 공간 size 1x1을 가질 수 있으며, 이는 input sequence가 단순히 feature map의 공간 dimension들을 flatten하고 Transformer dimension으로 project함으로써 얻어질 수 있음을 의미한다. Classification input embedding과 position embedding은 위에서 묘사한 것처럼 더해진다.
3.2 FINE-TUNING AND HIGHER RESOLUTION
전형적으로, 연구팀에서는 거대한 데이터셋으로 ViT를 pre-train 시켰고, 더 작은 downstream task들로 fine-tune을 시켰다. 이를 위해서, 연구팀에서는 pre-trained prediction head를 제거하고 0으로 초기화된 D x K feedforward layer를 붙였다. 여기서 K는 downstream class들의 개수이다. 종종 pre-training보다는 더 높은 해상도로 fine-tune하는 것이 더 이득이 된다. (Touvron et al., 2019; Kolesnikov et al., 2020) 더 높은 해상도의 이미지들을 투입할 때, 연구팀에서는 patch size를 동일하게 유지하고, 이는 결과적으로 sequence 길이가 더 커지게 되었다. Vision Transformer는 임의의 sequence length를 처리할 수 있다. (메모리 제약사항까지 가능함) 그러나, pre-trained position embedding은 아마 더 이상 의미가 없을 것이다. 그래서 연구팀에서는 pre-trained position embedding의 2D interpolation(보간법, 두 데이터 지점 사이에 새로운 데이터 지점을 만들어냄)을 수행하며, 이는 original 이미지의 위치에 의하여 수행한다. 명심할 것은 이 해상도 조절과 patch 추출이, 이미지들의 2D 구조에 대한 inductive bias가 Vision Transformer 내로 수동으로 주사되는 유일한 지점이라는 것이다.
4 EXPERIMENTS
연구팀에서는 ResNet, Vision Transfromer(ViT), 그리고 hybrid의 representaiton 학습 능력을 평가한다. 각 모델의 데이터 요구사항을 이해하기 위해서, 연구팀에서는 다양한 사이즈의 데이터셋으로 pre-train을 시키고 많은 benchmark task들을 평가한다. 모델을 pre-training하는 계산적인 cost를 고려할 때, ViT는 매우 순조롭게 수행하고, 더 적은 pre-training cost로 대부분의 recognition benchmark에서 state-of-the-art를 달성한다. 마지막으로, 연구팀에서는 self-supervision을 사용하여 작은 실험을 수행하고, self-supervised ViT가 미래를 약속하는 것(이후의 연구에도 활용 가능할 것이라는 의미인듯 함)을 보여준다.
4.1 SETUP
Datasets.
모델의 확장성을 탐구하기 위해서, 연구팀에서는 1000개의 클래스가 있고 130만개의 이미지가 잇는 ILSVRC-2012 ImageNet 데이터셋(앞으로는 이것을 ImageNet이라고 언급함)을 사용하고, 이 데이터셋의 superset(상위집합, 부분집합의 반대)인 21000개의 클래스가 있고 1400만개의 이미지가 있는 ImageNet-21k(Deng et al., 2009)와 18000개의 클래스가 있고 3억300만개의 고해상도 이미지가 있는 JFT(Sun et al., 2017)을 사용한다. 연구팀에서는 Kolesnikov et al. (2020)의 방식을 따라서 downstream task들의 test set에 관련된 pre-training 데이터셋의 중복을 제거한다. 연구팀에서는 이 데이터셋으로 훈련된 모델들을 여러 benchmark task들로 transfer시킨다. 여기에는 ImageNet(original validation label, cleaned-up ReaL labels로 이루어짐), CIFAR-10/100, Oxford-IIIT Pets, Oxford Flowers-102가 있다. 이 데이터셋들은, pre-processing은 Kolesnikov et al. (2020)을 따른다.
연구팀에서는 또한 19-task VTAB classification suite (Zhai et al., 2019b)에 대해서도 평가한다. VTAB은 다양한 task로의 low-data transfer을 평가하며, task 하나 당 1000개의 훈련 예시를 사용한다. task들은 3가지 그룹으로 나뉜다. Natural – 위에 나온 task들 중 Pets, CIFAR 등이다. Specialized – 의료 및 인공위성의 형상화이다. Structured – localization(국소화)와 같은 기하학적 이해를 필요로 하는 task들이다.
Model Variants.
연구팀은 ViT의 configuration을 BERT (Devlin et al., 2019)에서 사용된 것에 기초를 두었고, Table 1에 묘사되었다.

“Base”와 “Large” 모델들은 BERT로부터 직접 채택된 형태이며, 연구팀에서는 더 거대한 “Huge” 모델을 추가하였다. 이제부터는, 연구팀에서는 모델의 size와 input patch의 size를 나타내기 위해 간단한 기호를 사용할 것이다. 예를 들어, ViT-L/16은 input patch의 size가 16 x 16인 ViT-Large 모델을 의미한다. 명심해야 할 것은, Transformers의 sequence length는 patch size의 제곱에 반비례하며, 그러므로 더 작은 patch size의 모델들은 계산적으로 더 expensive하다는 것이다.
Baseline CNN을 위해서, 연구팀에서는 ResNet (He et al., 2016)을 사용하지만, Batch Normalization layer(Ioffe & Szegedy, 2015)를 Group Normalization (Wu & He, 2018)로 대체한다. 그리고 standardized convolution (Qiao et al. 2019)를 사용하였다. 이러한 변경점들은 transfer 능력(Kolesnikov et al., 2020)을 향상시키고, 연구팀에서는 이 변경된 모델을 “ResNet (BiT)”라 표시한다. Hybrid 모델을 위해서, 연구팀에서는 intermediate feature map들을 patch size가 1픽셀로 하여 ViT로 투입한다. 다른 sequence length로 실험하기 위해서, 연구팀에서는 (i) regular ResNet50의 stage 4의 output을 가져오거나 (ii) stage 4를 제거하고 stage 3에서의 layer의 개수를 그대로 배치하고 (전체 layer의 개수를 유지함), 이 확장된 stage 3의 output을 가져온다. 옵션 (ii)는 결과적으로 4배 긴 sequence length를 얻을 수 있고, ViT 모델이 더 expensive해진다.
Training & Fine-tuning.
연구팀에서는 ResNet을 포함하여 모든 모델들을 훈련시킨다. Adam optimizer를 beta1 = 0.9, beta2 = 0.999로 하여 사용하고, batch size는 4096에 높은 weight decay인 0.1을 적용한다. 이 값들이 모든 모델의 transfer에 유용하다는 것을 발견해냈다. (Appendix D.1 참고, 일반적인 관례와 달리 Adam이 ResNet에 대해 SGD보다 조금 더 좋게 동작하였음) 연구팀에서는 linear learning rate warmup과 decay를 사용하며, 자세한 사항은 Appendix B.1을 참고하면 된다. Fine-tuning을 위해서 연구팀에서는 모든 모델에 대해 모멘텀과 함께 SGD를 사용하고, batch size는 512로 한다. 자세한 사항은 Appendix B.1.1을 참고하면 된다. ImageNet에 대해서는 Table 2에 결과가 나오며, 연구팀에서는 더 높은 해상도로 fine-tune을 하였다. ViT-L/16은 512(무슨 값인지 모르겠음), ViT-H/14는 518이며, 또한 Polyak & Juditsky (1992) averaging을 factor 0.9999로 하여 사용하였다.

Metrics.
연구팀에서는 downstream 데이터셋에 대한 결과를 few-shot 또는 fine-tuning 정확도로 결과를 냈다. Fine-tuning 정확도는 각각의 데이터셋에 대해 fine-tuning을 한 이후의 performance를 나타낸 것이다. Few-shot 정확도는 훈련 이미지들의 부분집합의 (frozen) representation을 {-1, 1}^K target vector들로 mapping시키는 regularized least-squares regression problem을 해결함으로써 얻을 수 있다. 이 공식은 closed form에서 정확한 solution을 회복하도록 해준다. (어떤 문제에 대한 해를 정확한 식의 형태로 표현하는 것을 의미하는 듯함) 비록 연구팀에서는 fine-tuning 성능에 주로 집중하지만, 가끔은 fine-tuning이 너무 cost가 들 경우에는 즉석에서 빠르게 적용 가능한 평가를 위해 linear few-shot 정확도를 사용한다.
4.2 COMPARISON TO STATE OF THE ART

이전까지는 ImageNet에 대해서는 Noisy Student가 state-of-the-art이며, 그 외의 데이터셋에 대해서는 BiT-L(Big Transfer)이 state-of-the-art이다. Table 2에서는 기존 SOTA 모델들과 연구팀의 ViT 모델들의 결과 비교를 보여준다. 흥미롭게도, 모델이 가장 큰 ViT-H/14가 기존의 BiT-L, Noisy Student를 제치고 성능에서 앞섰으며, 반면에 계산 cost는 현저하게 적다는 것을 확인할 수 있다. JFT로 훈련된 ViT-L/16 역시 이전 SOTA 모델과 비슷하거나 앞선 성능을 보여주며 계산 cost는 ViT-H/14보다 적다는 것을 확인할 수 있다.
4.3 PRE-TRAINING DATA REQUIREMENTS


Figure 3에서는 Pre-training 시 데이터셋의 크기가 성능에 얼마나 영향을 주는지 실험을 한다. 데이터셋의 크기는 ImageNet < ImageNet-21k < JFT-300M이며, 크기가 작은 데이터셋은 성능을 최대한 끌어올리기 위해 weight decay, dropout, label smoothing을 최적화한다. Figure 3에서 확인할 수 있는 것은, 작은 데이터셋에서는 크기가 작은 모델의 성능이 더 좋으며, 데이터셋이 커지면 거대한 모델의 성능이 압도한다. BiT의 경우 작은 크기의 데이터셋에서는 성능을 압도하지만, 그 외에는 ViT가 따라잡게 된다.
Figure 4에서는 JFT-300M 데이터셋에서 랜덤하게 부분집합을 뽑아내어(9M, 30M, 90M, 300M) 실험을 한다. 모델의 내재된 특성을 테스트하기 위한 것이므로, 추가적인 regularization없이 early-stopping만 도입하고 hyperparameter는 전부 동일하게 세팅하였다. 그리고 계산량을 줄이기 위해 few-shot accuracy를 사용한다. 확인할 수 있는 결과는, 작은 데이터셋에서는 ViT가 ResNet보다 overfitting되며, 더 큰 데이터셋에서는 ViT가 더 좋다. 즉, convolutional inductive bias는 작은 데이터셋에서는 유용하지만, 데이터셋이 커지면 그냥 데이터로부터 관련된 pattern을 직접 학습하는 것이 더 좋다.
4.4 SCALING STUDY

Figure 5에서는 각 모델 아키텍처의 pre-training cost 대비 transfer 성능을 비교한다. 데이터셋은 JFT-300M이다. 결과적으로, ViT는 ResNet(BiT)를 전반적으로 압도한다. ViT와 BiT를 섞은 Hybrid의 경우 작은 모델 크기에서는 ViT를 조금 앞서지만, 모델이 커지게 되면 차이가 사실상 거의 없어진다. BiT의 convolutional local feature가 도움을 주어 Hybrid가 모든 구간에서 ViT를 이길 수 있다는 예측을 조금 벗어난 결과이다. 또한, ViT는 성능이 수렴하지 않는 것으로 보여, 이후의 연구에서 scaling을 하는 것에 따라 더욱 더 성능 향상을 보일 수 있다.
4.5 INSPECTING VISION TRANSFORMER

Figure 7에서 왼쪽의 그림은 학습된 embedding filter들의 top principal component(주성분)을 보여주는데, 이 주성분들은 각 patch내의 미세한 structure의 low-dimensional representation을 나타내기 위한 그럴듯한 기저 함수와 유사하다.
Figure7에서 가운데 그림은 모델이 position embedding의 유사성에서 이미지 내의 distance를 encode하는 것을 보여준다. Patch 중 가까운 patch(row가 같거나 column이 같은 곳) 사이의 cosine similarity는 높다.
Figure7에서 오른쪽 그림은 attention weight에 기반하여 정보가 통합된 이미지 공간의 평균 거리를 계산한 것을 보여준다. 이 attention distance는 CNN의 receptive field size(출력 레이어의 뉴런 하나에 영향을 미치는 입력 뉴런들의 공간 크기로 filter의 size와 같음)와 유사하다. 중요한 점은 self-attention을 통해서 ViT가 전체 이미지의 정보를 통합하는 것이 가능하다는 것이다. 또한, 네트워크가 깊어질수록 attention distance도 증가한다는 것을 발견했다.
4.6 SELF-SUPERVISION
Transformers가 NLP task에서 놀라운 성능을 보여준 이유는 좋은 확장성도 있지만, 거대한 규모의 self-supervised pre-training또한 존재한다. 연구팀에서도 BERT에서 사용된 Masked Language Modeling(MLM)을 모방한 Masked Patch Prediction을 예비적으로 수행하였다. 그 결과, ViT-B/16 모델이 ImageNet에 대하여 79.9% 정확도를 달성하여, scratch보다 2% 더 높은 성능을 보여주었다. 그래도 supervised pre-training보다는 4%정도 뒤쳐진다.
5 CONCLUSION
연구팀에서는 Transformers를 image recognition에 직접적으로 적용하는 방법을 발견하였다. CV에서 self-attention을 사용하는 이전의 연구들과는 다르게, 연구팀에서는 초기의 patch extraction 단계를 제외하고는 image-specific한 inductive biases를 아키텍처에 도입하지 않는다. 대신에, 연구팀에서는 image를 patch들의 sequence로 바라보고 NLP에서 사용된 standard한 Transformer encoder처럼 처리한다. 이 간단하면서도 확장 가능한 전략은 거대한 데이터셋으로 pre-training하는 것과 함께 시도할 때 놀라울 만큼 잘 작동한다. 그러므로, Vision Transformer는 많은 image classification 데이터셋에 대해 state-of-the-art를 달성하거나 뛰어넘으며, 그러면서도 pre-train하기에는 비교적 비용이 적게 든다.
이 초기 결과들이 고무적인 반면에, 많은 challenge들이 남아있다. 하나는 ViT를 다른 CV task들에 적용하는 것으로, detection이나 segmentation등이 있다. 연구팀의 결과는, Carion et al. (2020)의 결과와 함께 묶여서, 이러한 접근법의 가망성을 보여준다. 또다른 challenge로는 self-supervised pre-training 방법들을 계속 시도해보는 것이다. 연구팀의 초기 실험들은 self-supervised pre-training으로부터 성능 향상을 보여주지만, 여전히 self-supervised pre-training과 large-scale supervised pre-training간에는 커다란 격차가 있다. 마지막으로, ViT의 추가 확장이 향상된 성능으로 이끌게 될 것이다.
ACKNOWLEDGEMENTS
생략함
REFERENCES
생략함
APPENDIX
A MULTIHEAD SELF-ATTENTION
Standard한 qkv self-attention (SA, Vaswani et al. (2017))은 신경망 구조에서 인기있는 building block이다. Input sequence z(N x D 차원)의 각 원소에 대해서, 연구팀에서는 sequence의 모든 value v의 weighted sum을 계산한다. Attention weight인 A_ij는 sequence의 2개의 원소 사이의 pairwise similarity와 그들 각각의 query q^i와 key k^j의 representation에 기반한다.

Multihead self-attention (MSA)은 SA의 확장판인데, 여기서는 “heads”라 불리는 k개의 self-attention 연산을 병렬적으로 수행하며, 그들의 concatenated된 output을 제시한다. (Eq. 5)에서 k를 변경할 때 파라미터의 숫자를 일정하게 유지하기 위해서, 일반적으로 D_h는 D / k로 설정된다.

기타 참고자료
[invariance] : https://stats.stackexchange.com/questions/208936/what-is-translation-invariance-in-computer-vision-and-convolutional-neural-netwo
What is translation invariance in computer vision and convolutional neural network?
I don't have computer vision background, yet when I read some image processing and convolutional neural networks related articles and papers, I constantly face the term, translation invariance, or
stats.stackexchange.com
[inductive bias] : https://robot-vision-develop-story.tistory.com/29
Inductive Bias
안녕하세요 오랜만에 글을 쓰게 되었습니다. 요즘 대학원 진학 후 이것저것 하다 보니 시간이 빨리 가네요.. 오늘 다룰 주제는 제가 최근에 공부하고 있는 Transformer에서 나온 용어에 대해서 짚어
robot-vision-develop-story.tistory.com
'Naver BoostCamp AI Tech 3기' 카테고리의 다른 글
| Improving Language Understanding by Generative Pre-Training (0) | 2022.03.10 |
|---|---|
| Bag of Tricks for Image Classification with Convolutional Neural Networks (0) | 2022.02.22 |
| [코드리뷰]BERT (2) | 2022.02.15 |
| BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (1) | 2022.02.13 |
| [DL Basic] 8강 Transformer (1) | 2022.02.08 |