2022. 2. 8. 01:21ㆍNaver BoostCamp AI Tech 3기
RNN(Vanilla) : 재귀적인 신경망으로, sequential한 data를 처리할 수 있는 신경망이다. 각각의 timestep에서의 입력과 이전 timestep까지의 hidden state를 이용하여 과거의 정보를 사용할 수 있는 Neural Network인 것이다. 그림으로 나타내면 다음과 같다.
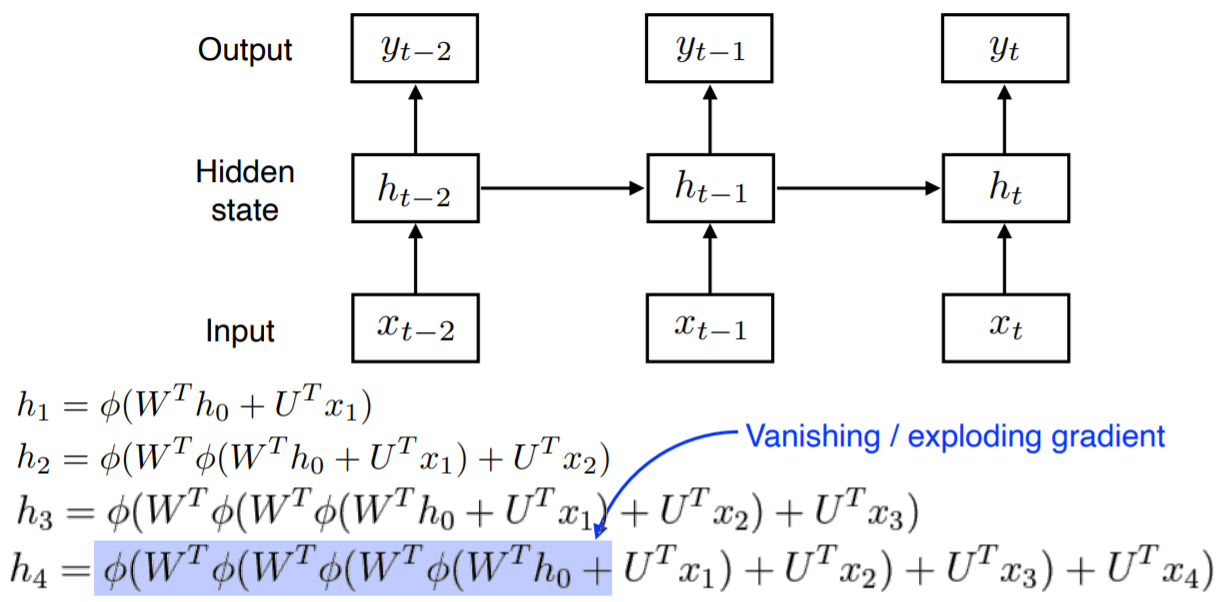
RNN의 단점으로는 vanishing gradient 혹은 exploding gradient가 발생할 수 있다는 것이다. 만약 activation function이 sigmoid같은 것이면 vanishing gradient가 발생하고, ReLU같은 것이면 exploding gradient가 발생할 수 있다. 또한, Vanilla RNN은 너무 먼 과거의 정보를 활용할 수가 없다. 이를 보완하기 위해서, LSTM과 GRU가 등장하였다.
LSTM : Long-Short Term Memory의 줄임말로, 기존 Vanilla RNN의 long-term dependency 단점을 보완한 구조이다. 그림은 다음과 같다.

LSTM에는 크게 3개의 gate가 있다. Forget gate, Input gate, Output gate로 각각 이름 그대로의 역할을 한다.
Forget gate는 이전 cell state의 정보를 얼마나 잊어버릴지를 결정한다. 식은 다음과 같다. 그리고 gate에서 주로 sigmoid가 사용되는데, sigmoid를 사용하면 값이 0~1로 mapping 된다. 0에 가까울수록 state를 반영하지 않겠다는 의미이고, 1에 가까울수록 최대한 반영하겠다는 것으로 해석할 수 있다.

이런 식으로, ht-1과 xt가 concatenate되어서 계산되는 것으로 적혀있는데, 이 식을 다음과 같이 볼 수 있다.

다음은 Input gate에 관한 것이다. 이는 Forget gate와는 반대로, 어떤 정보를 cell state에 저장할 지를 결정한다. it는 어떤 정보를 얼마나 반영할 지에 관한 것이고, Ct(tilda)는 새로 저장될 정보의 "후보군"으로 볼 수 있다.

역시 다음과 같은 식으로 볼 수 있다. 여기서 gt는 위의 그림의 Ct(tilda)를 의미한다.

이렇게 Forget Gate와 Input Gate를 통해 망각할 계수 ft와 새로 저장할 계수 및 정보 it, Ct(tilda)를 구하면, 다음의 과정으로 Cell State를 Update해준다.

여기서 *은 element-wise product이다. 즉, ft와 Ct-1은 행렬의 크기가 같아야한다. 이를 통해서 Cell State Ct를 구한다.
마지막으로 Output Gate를 통해서 ht를 구하게 된다.

역시 다음과 같이 표현 가능하다.

LSTM cell은 이와 같이 동작한다. 이를 통해 Long-Term Dependency 문제를 해결하는 데에 탁월하다.
이 외에도, GRU(Gated Recurrent Unit)이 존재한다.
GRU : Gated Recurrent Unit으로, LSTM보다는 비교적 간단하다. gate가 Reset Gate와 Update Gate로 2개가 있다. cell state가 없고 hidden state를 직접 사용하게 된다. LSTM에 비해 parameter 수가 적어서, LSTM보다 훈련이 잘 되서 성능이 좋아지는 경우가 많다고 한다.


'Naver BoostCamp AI Tech 3기' 카테고리의 다른 글
| BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (1) | 2022.02.13 |
|---|---|
| [DL Basic] 8강 Transformer (1) | 2022.02.08 |
| [DL Basic] 3강 Optimization (0) | 2022.02.07 |
| [DL Basic] 2강 MLP (0) | 2022.02.07 |
| [Python] 5강 (0) | 2022.02.06 |