2022. 2. 7. 23:52ㆍNaver BoostCamp AI Tech 3기
Optimization : gradient descent를 통하여 loss function의 local minimum을 찾아가는 과정임. 이 optimization에 여러 중요 개념들에 대해 알아보자.
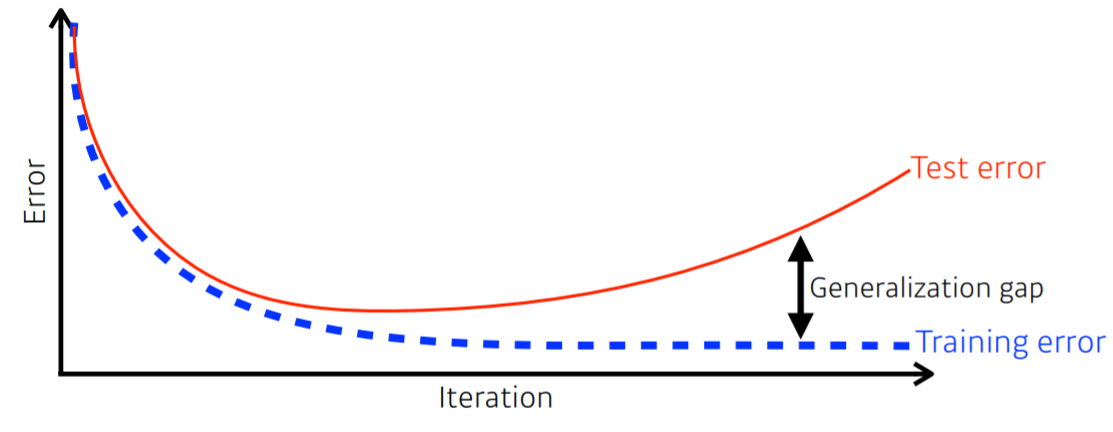
Generalization : model은 training data만 잘 맞추어서는 안되고, 한번도 본적 없는 test data에 대해서도 최대한 training data와 비슷하게 좋은 성능이 나와야 한다. 아래 그림과 같이 Training Error와 Test Error의 차이가 Generalization gap이다. 이 gap이 너무 크면 overfitting이다.
Cross-Validation : 이름 그대로 교차하면서 Validation data를 사용하는 것이다. Validation data를 Training data 중에서 일부분을 골라서 사용하고, 다음 EPOCH때는 다른 일부분을 골라서 Validation data로 사용하는 방식이다. 중요한 것은, 절대로 Test data를 사용하면 안된다.

Bias and Variance : 쉽게 말하자면 variance는 분포에 대한 분산을 의미하는데, model에 대한 variance가 작으면 비슷한 입력값에 대해서 비슷한 출력을 내게 된다. 그러나 variance가 크다면, 입력값이 살짝만 틀어져도 꽤 다른 출력이 나오게 된다. bias는 전체적인 분포에 대한 편향이다. 이는 모든 데이터에 대해 똑같은 방향으로 똑같은 크기만큼 shift된 것으로 생각할 수 있다. 아래의 그림을 참조하자.

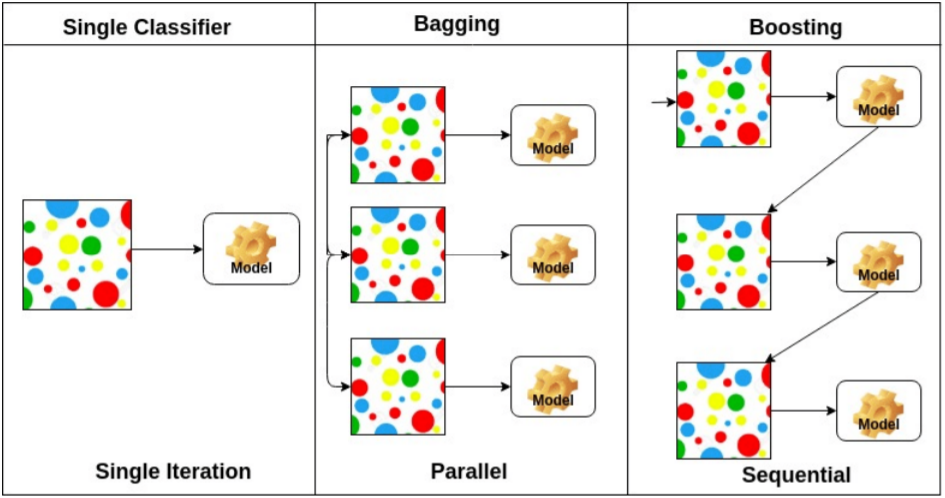
Bagging(Bootstrapping aggregating) : Ensemble Learning이라고도 한다. Bootstrapping은 통계학 및 ML에서 랜덤 샘플링(중복 허용)을 통해 데이터를 뽑아내는 것이다. 이렇게 Bootstrapping을 이용하면 데이터가 충분치 않아도 ensemble을 만들 수 있다. 방법은 간단하다. Bootstrapping을 통해 데이터를 랜덤으로 추출하고, 그 데이터로 모델을 훈련시킨다. 여기서 Bootstrapping을 여러번 해서 여러 데이터셋을 만든다. 이걸로 같은 알고리즘으로 모델을 여러 개 만든다. 물론 데이터셋이 다르므로 구조는 같아도 서로 다른 모델이다. 이 모델들의 각각의 출력값을 Voting(다수결 투표)하여, 가장 많이 정답이라고 나온 예측을 정답으로 사용한다. 간단하면서도 꽤 강력한 방법이다.
Boosting : Bagging처럼 여러 개의 모델을 사용하는 것은 동일하지만, Bagging과는 달리 Boosting은 sequential하다. weak learner 여러 개를 합쳐 strong learner로 만드는 것으로, 초반의 모델들이 잘 예측하지 못한 data에 대해서 가중치를 줘서 다음 모델들이 그 data들에 집중하게 만든다. 이렇게 해서 만들어지는 모델은 전체적인 data를 잘 예측하게 된다.
'Naver BoostCamp AI Tech 3기' 카테고리의 다른 글
| [DL Basic] 8강 Transformer (1) | 2022.02.08 |
|---|---|
| [DL Basic] 7강 RNN, LSTM, GRU (1) | 2022.02.08 |
| [DL Basic] 2강 MLP (0) | 2022.02.07 |
| [Python] 5강 (0) | 2022.02.06 |
| Sequence to Sequence Learning with Neural Networks (1) | 2022.02.03 |